

LRM也在“假装思考”?
论文开门见山抛出暴论:当前火爆的大推理模型(LRM)(如DeepSeek-R1、Claude思考模式)可能只是在表演“思考秀”。这些模型生成解题步骤时看似逻辑严谨,实则遇到复杂问题瞬间崩溃——就像学生抄作业时把计算过程写满卷子,最后答案却是错的
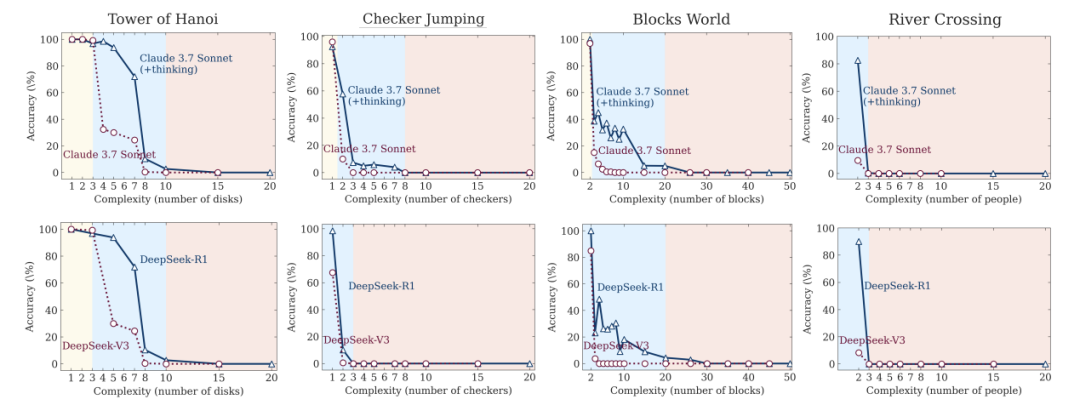
证据:当问题复杂度超过临界点,模型准确率直接归零

论文:The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
链接:https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
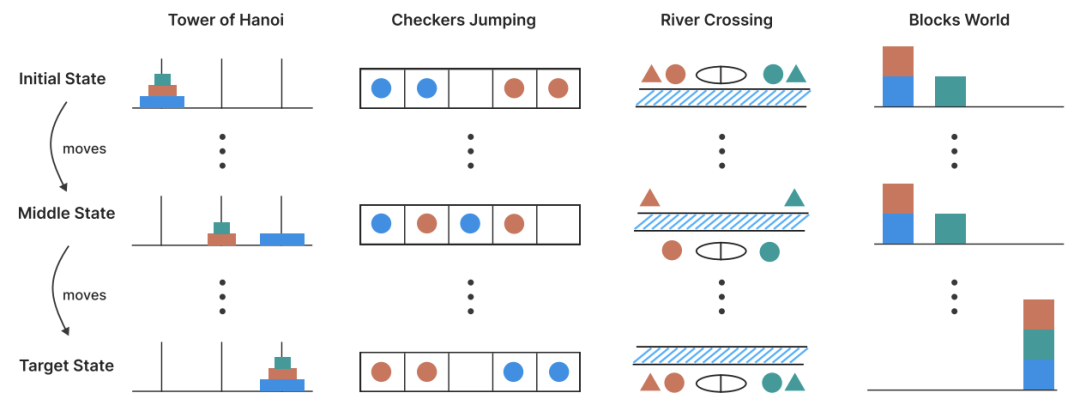
给LRM设计的另类测试
-
汉诺塔(指数级难度):移动圆盘需 2ⁿ-1 步 -
跳棋换位(平方级难度):(n+1)²-1 步 -
渡河问题:演员经纪人不能独处的约束难题 -
积木世界:堆叠规划的经典AI测试
这些谜题能精准控制难度层级,还能实时监控思考路径!
颠覆的三大发现
现象一:越难越想偷懒!
当问题复杂度突破临界值(如汉诺塔圆盘>15个),LRM的“思考量”不增反降。明明有充足“脑容量”(64K token),却选择摆烂躺平。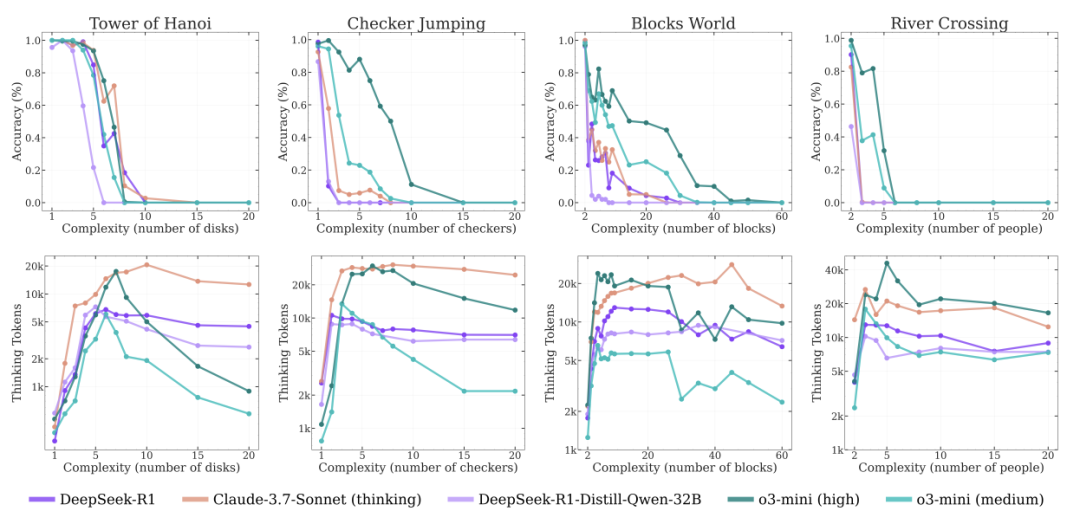
现象二:三重表现断崖
-
简单题:普通模型反而更快更准(LRM过度思考) -
中等题:LRM优势显现(思考机制起作用) -
超难题:所有模型集体崩溃
 “当前AI的推理能力存在玻璃天花板”
“当前AI的推理能力存在玻璃天花板”
现象三:算法说明书也救不了
即使把标准答案(如汉诺塔递归算法)喂给模型,崩溃点几乎不变。说明问题不在“找不到方法”,而是根本执行不了连贯逻辑。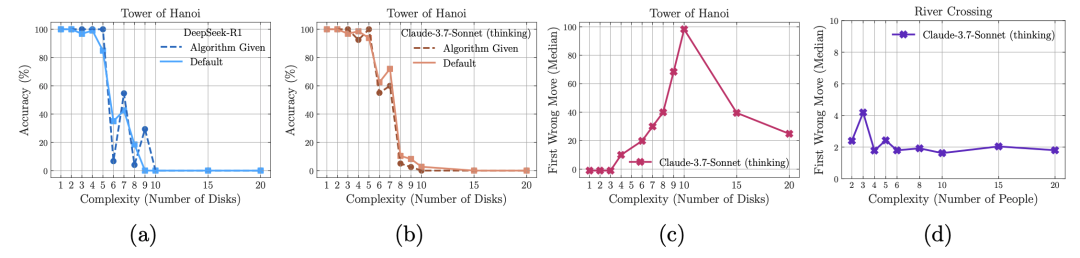
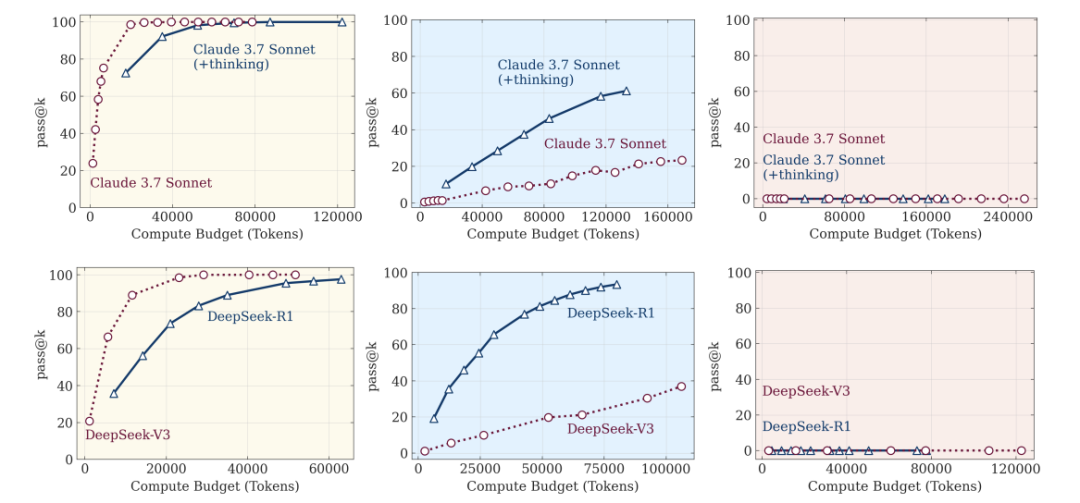
思考过程的“迷惑行为”
通过解析模型的思考轨迹,发现更荒诞的现象:
-
简单题:早早答对却继续瞎算(强行加戏) -
中等题:试错多次后偶然撞对答案(像蒙选择题) -
超难题:全程错误路径(大脑彻底死机)
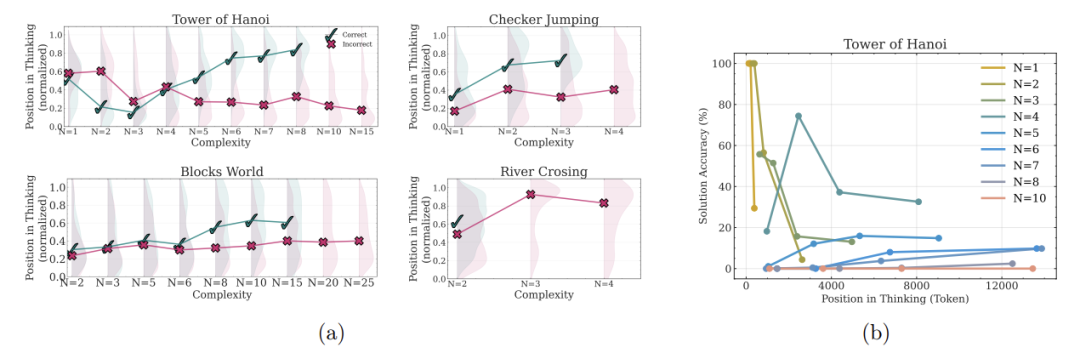
最讽刺的是:LRM在渡河问题上走不过5步,却能完成100步的汉诺塔——暴露其本质是“模式复读机”,而非真正推理!
给我们的红灯警告
论文直指行业痛点:
-
过度依赖数学基准测试(存在数据污染) -
把“生成长文本”等同于“强推理能力” -
亟需开发逻辑验证内核(非统计学拟合)
作者警告:“当前LRM可能只是通过RL学到的推理模仿术”
我们离真正的思考AI有多远?
结论既扎心又充满希望:
-
短期:需突破符号推理与执行一致性 -
长期:或需全新架构(非纯Transformer) -
最大启示:能生成“看似合理步骤” ≠ 拥有推理能力
文末留下灵魂拷问:当模型的思考轨迹成为“皇帝的新衣”,我们该如何检测真智能?
(文:机器学习算法与自然语言处理)