

本文将介绍 DeepMath-103K 数据集。该工作由腾讯 AI Lab 与上海交通大学团队共同完成。
本文的通讯作者为涂兆鹏,腾讯混元数字人专家研究员,研究方向为深度学习和大模型,在国际顶级期刊和会议上发表学术论文一百余篇,引用超过 10000 次,担任 SCI 期刊 NeuroComputing 副主编,多次担任 ACL、EMNLP、ICLR 等国际顶级会议领域主席。共同通讯作者王瑞,上海交通大学副教授,研究方向为计算语言学。第一作者为上海交通大学博士生何志威,腾讯 AI Lab 高级研究员梁添、徐嘉豪。
在 AGI 的浩瀚征途中,数学推理能力始终是衡量其智能水平的关键试金石。然而,当前大语言模型(LLM)在数学推理,特别是通过强化学习(RL)进行训练时,正面临着前所未有的数据瓶颈:现有数据集普遍缺乏挑战性和新颖性、答案难以验证,且常与评估基准存在 “污染” 问题。
为了解决以上问题,DeepMath-103K 数据集横空出世,它以其大规模、高难度、严格去污染和可验证答案的特性,为 AI 数学推理领域带来进一步突破。

-
论文题目:DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning
-
论文地址:https://arxiv.org/pdf/2504.11456
-
数据地址:https://hf.co/datasets/zwhe99/DeepMath-103K
-
模型地址:https://hf.co/collections/zwhe99/deepmath-6816e139b7f467f21a459a9a
-
代码地址:https://github.com/zwhe99/DeepMath
痛点:现有数据集为何 “拖后腿” ?
想象一下,你正在训练一个 AI 数学家,但它手里的 “习题集” 却有诸多缺陷:
-
难度不够:题目过于简单,无法真正挑战模型的推理极限。
-
答案难验:缺乏标准化、可验证的答案格式,让强化学习的奖励机制无从下手。
-
数据污染:训练数据与测试基准存在重叠,无法真实反映能力。
-
缺乏新意:大多是对现有资源的简单重组,新颖性和多样性严重不足。
这些问题,就像给 AI 数学家戴上了 “镣铐”,即使模型架构再先进,也难以施展拳脚,更别提实现真正的 “深度思考” 和泛化能力。
DeepMath-103K:AI 数学推理的 “硬核” 解决方案
为了打破这些桎梏,DeepMath-103K 应运而生。它是一个包含约 103,022 个数学问题的全新大规模数据集,专为通过强化学习训练高级推理模型而设计。
1. 规模与难度:专为 “极限挑战” 而生
DeepMath-103K 的显著特点是其高难度。其中 95K 个问题被精心构造为难度等级 5-10,另有 8K 个来自 SimpleRL 的问题(难度等级 3-5)以确保更广泛的难度覆盖。这种难度分布明显偏向高难度,旨在推动当前模型的推理极限,与现有其它数据集形成鲜明对比。
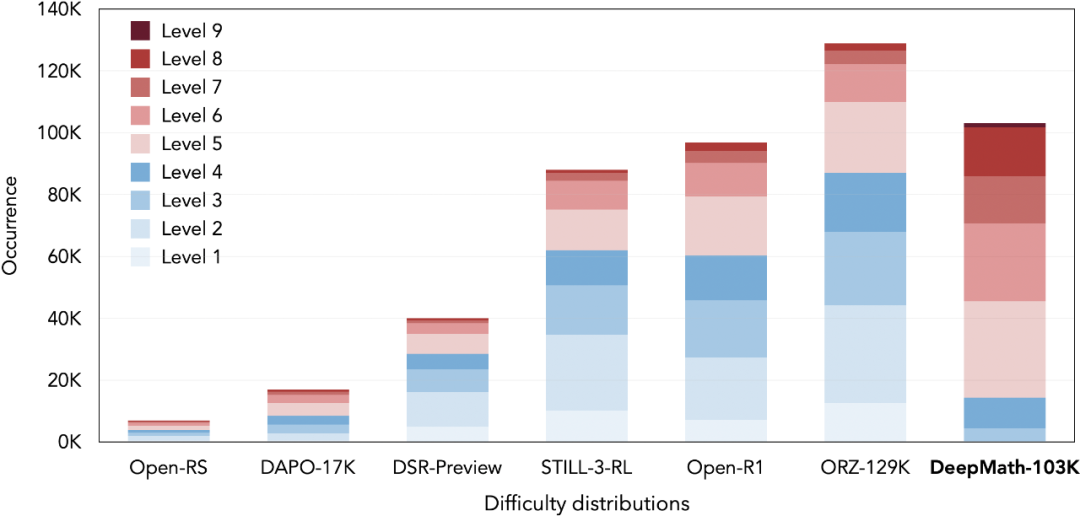
2. 数据新颖性:告别 “千篇一律”
与许多现有开放数据集不同,DeepMath-103K 主要从 Math StackExchange 等更多样化但结构性较差的来源获取内容。这种方法将非正式讨论转化为结构化问答,带来了显著的新颖性和多样性。
在涵盖的主题上,DeepMath-103K 包含了从基础概念(如初等代数、平面几何)到高级主题(如抽象代数、微积分、数论、几何、概率、离散数学等)的广泛数学领域 。这种分层且全面的主题覆盖,确保了模型能够接触到不同复杂度、不同类型的数学问题,从而促进在不同数学领域中通用推理能力的发展。

对数据集内容的深入分析表明,DeepMath-103K 在问题新颖性和独特性方面表现出压倒性优势。在对数据集的问题进行嵌入化,降维,可视化后,我们惊人地发现大多数数据集的问题分布极其雷同(蓝色点簇)。而 DeepMath-103K 的问题(红色点簇)则在空间中形成了一个与众不同的分布。

进一步地,在总计约 103K 个问题中,高达 82.81K 个问题是独一无二的,这意味着它们在其它数据集中从未出现过。
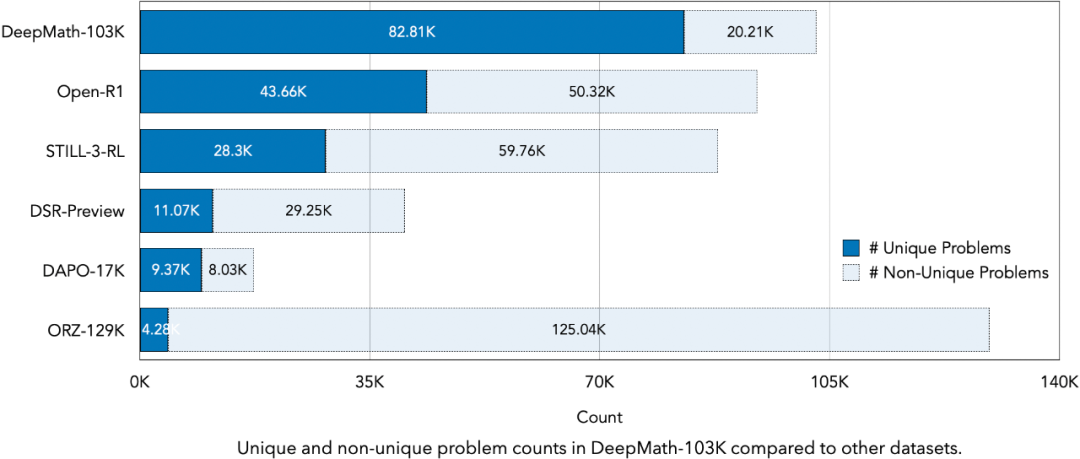
这直观地表明,DeepMath-103K 的问题集合在语义和结构上与现有数据集存在显著差异,避免了 “炒冷饭” 的问题,为模型提供了真正新颖的训练样本。
3. 严格去污染:确保评估 “纯净”
DeepMath-103K 的构建过程堪称 “匠心独运”,通过一个细致的四阶段构造流程:
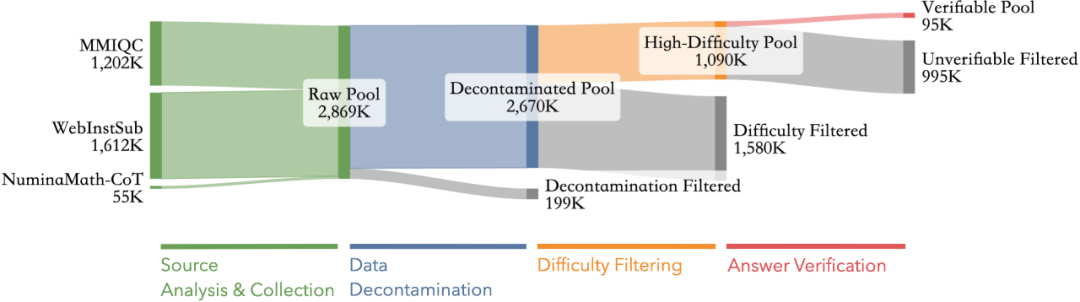
1. 来源分析与收集:分析现有数据来源,选择难题比例高的数据源。
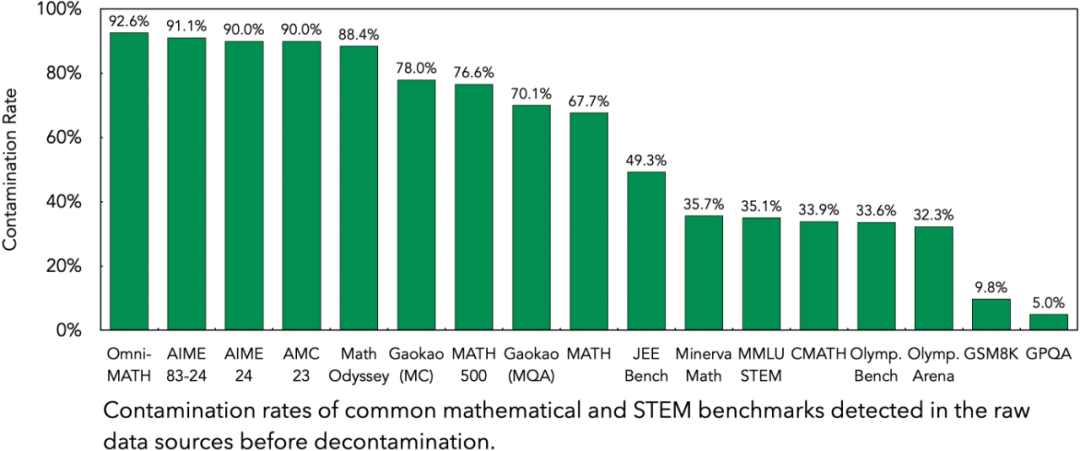
2. 数据去污染:使用嵌入相似性搜索和 LLM-Judge 来识别并消除与 MATH、AIME、AMC、Minerva Math、OlympiadBench 等 17 个数学和 STEM 基准的重叠,确保评估的完整性并防止数据泄露。
3. 难度过滤:使用 GPT-4o 对问题进行难度评估,保留难度等级 5 或更高的问题。
4. 答案验证:采用两阶段流程,确保所有解决方案路径中的最终答案一致且可验证。
这个过程的计算成本极其高昂:约 138,000 美元的费用和 127,000 小时的 H20 GPU 时间 。这足以证明其在数据质量和纯净度上的巨大投入。
4. 独特结构:为 RL 训练 “量身定制”
DeepMath-103K 中的每条数据都包含丰富的信息,支持多种数学推理研究和应用 :
-
问题:核心的数学问题陈述。
-
最终答案:可靠且可验证的最终答案,这对于在可验证奖励强化学习(RLVR)中基于规则的奖励函数至关重要,是自动化评估和反馈的基础。
-
难度:数值难度标注,支持难度感知训练。
-
主题:分层主题分类,涵盖从初等代数到抽象代数、微积分的广泛数学主题。
-
R1 解决方案:由 DeepSeek-R1 模型生成的三种不同的推理路径。这些多重解决方案对于监督微调和模型蒸馏等多种训练范式都具有巨大价值。

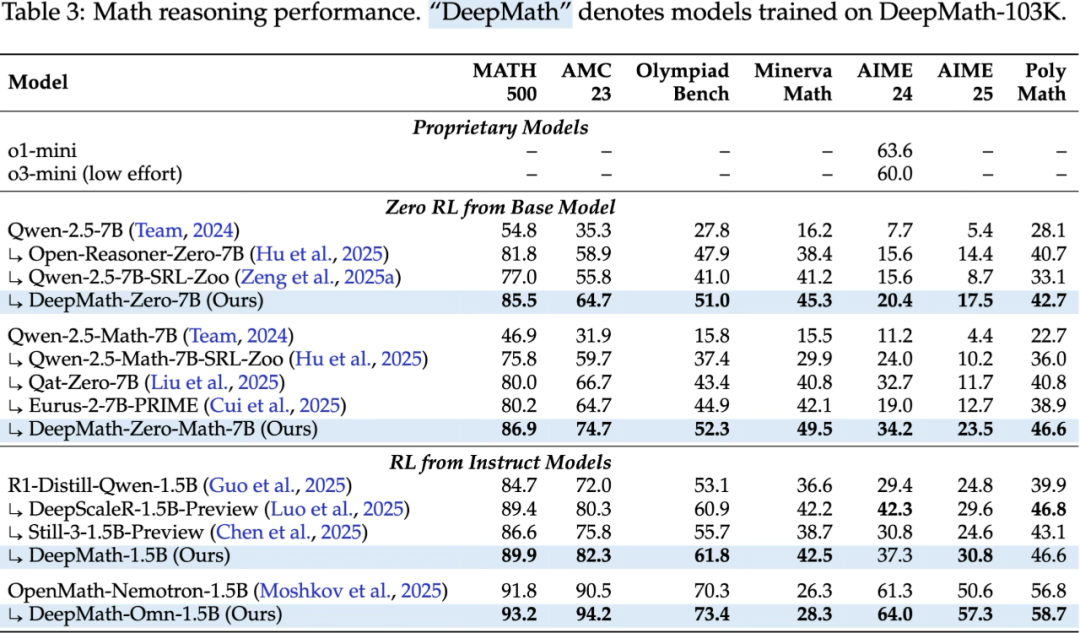
DeepMath 系列模型在多个基准上达到 SOTA
-
Zero RL(从 Base model 直接开始 RL): DeepMath-Zero-7B 和 DeepMath-Zero-Math-7B 从 Qwen-2.5-7B 和 Qwen-2.5-Math-7B 模型开始训练,表现出显著的性能提升,并在所有评估基准上取得了新的 SOTA 结果。
-
RL(从 Instruct model 开始 RL):基于 R1-Distill-Qwen-1.5B 初始化的 DeepMath-1.5B 取得了优异的性能;从 OpenMath-Nemotron-1.5B 开始的 DeepMath-Omn-1.5B 在所有评估基准上都获得了 1.5B 规模模型中新的 SOTA 结果,甚至超越了 o1-mini 和 o3-mini (low effort)。
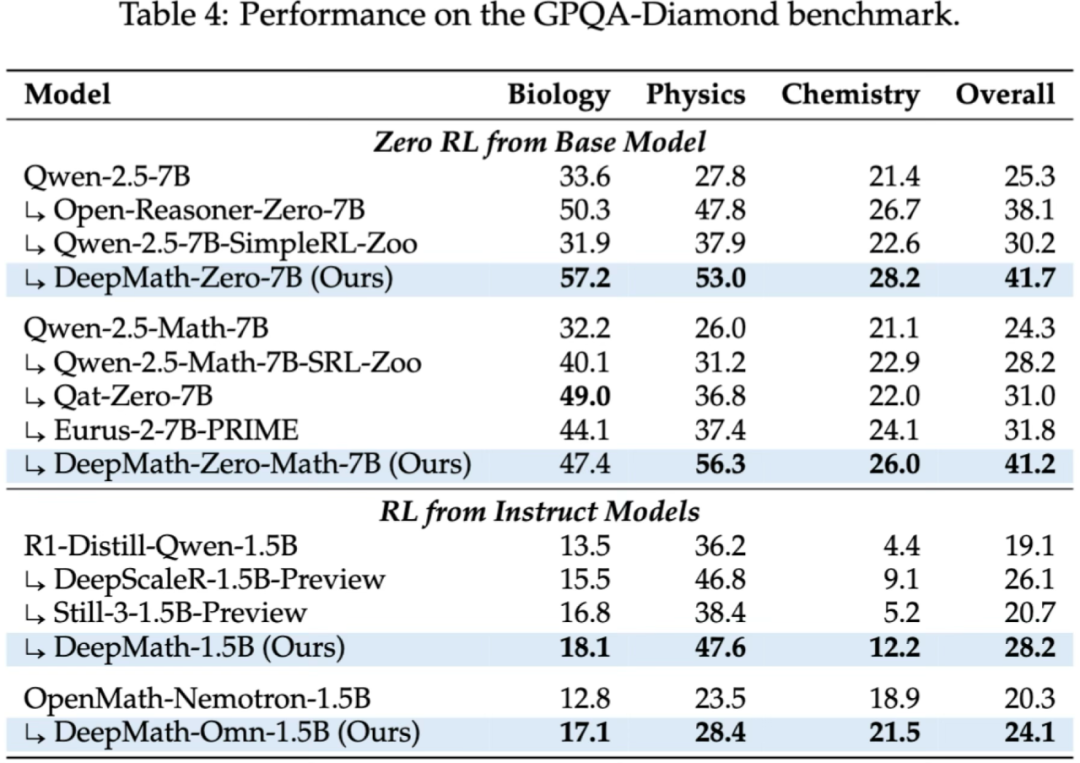
可泛化的推理:从数学到科学的飞跃
DeepMath 系列模型展示了将其推理能力从纯数学领域泛化到更广泛的科学领域的显著能力。与基线模型相比,它们在涵盖生物学、物理学和化学的 GPQA-Diamond 基准上取得了卓越的性能。这支持了强大的数学推理并非孤立技能,而是一种基础性认知能力,支撑着更广泛的科学和逻辑理解的假设。
结语
DeepMath-103K 的发布,无疑为人工智能数学推理领域形成了新的突破。它不仅解决了数据瓶颈问题,更通过其独特的设计和卓越的性能,证明了精心构造的高质量训练数据在推动 AI 前沿方面的深远价值。我们期待,在 DeepMath-103K 的推动下,AI 能够真正学会 “深度思考”,从数学的逻辑殿堂走向更广阔的科学探索,最终迈向更强大、更具通用性、认知上更复杂的智能系统!

©
(文:机器之心)