

图像描述(Image Captioning)是多模态学习中基础且重要的任务,随着 LLM 时代模型的发展,现代的视觉语言模型可以生成详细而全面的描述。然而,由于评测的主观性和困难,当前的视觉语言评测往往只关注 VQA、推理等任务,忽略了对模型 Detailed Image Captioning 能力的评估。
为了促进大模型时代图像描述的研究,本文主要做了以下三方面的贡献:
1. 构建了第一个面向 Detailed Image Captioning 的大规模人工评测体系
CapArena,首次观察到显示顶尖模型如 GPT-4o,在图像描述任务已经达到或超过人类专家水平。
2. 评估了各类指标、以及 VLM-as-a-Judge 和人类偏好的一致性,结果展现了 LLM 时代的图像描述评测的范式迁移:从传统的 reference-based 方法切换到具有更高一致性和区分性的 pair-wise 对战方法;同时指出指标的“系统性偏差”是影响和人类偏好一致性的关键因素。
3. 构建一个轻量的 Detailed Image Captioning 自动化评测基准 CapArena-Auto,单次 $4 成本达到了和人工排名 94.3% 的相关性。

论文题目:
CapArena: Benchmarking and Analyzing Detailed Image Captioning in the LLM Era (ACL 2025 Findings)
作者单位:
南京大学、香港大学、上海AI Lab
论文地址:
https://arxiv.org/abs/2503.12329
项目主页:
https://caparena.github.io/

引言
图像描述是计算机视觉与自然语言处理领域的长期挑战,在辅助视障人士、多媒体检索等场景中具有重要应用价值。随着大语言模型(LLMs)的快速发展,现代视觉语言模型(VLMs)已突破传统短描述的局限,能够生成长文本的详细描述,为领域带来新机遇。
然而,当前研究面临一个重要瓶颈:Detailed Image Captioning 因缺乏明确答案,传统的选择题式评测方法失效,缺失可靠的评测方法;导致当前主流 VLM-benchmark 多聚焦于视觉问答(VQA)和多模态推理任务,忽视图像描述这一核心需求;少有的评测 benchmark 如 MSCOCO 仅包含短描述文本(平均长度仅 10 词),明显过时。
研究者既难以客观衡量现有 VLMs 的描述能力,也无法有效优化模型性能。
为此,本研究首先构建了首个大规模人类标注的 Detailed Captioning 对战评测系统 CapArena(包含 6000 + 高质量人工标注,覆盖 14 个先进 VLMs 与人类表现的对战)。
结果显示,当前顶尖模型如 GPT-4o 已经打平甚至超过人类专家的表现,这标志着图像描述领域的一个里程碑;同时,开源模型与商业模型仍存在显著差距,表明小型开源模型在图像描述任务上仍有很大提升潜力。
借助上述标注数据,我们系统性地评估了一系列传统指标、以及 VLM-as-a-Judge 都在图像描述评估上与人类偏好的一致性。
我们首次展示了指标的系统性偏差对 caption 评估的影响,最终结果揭示 LLM 时代的图像描述评测所需的范式迁移:从传统的 reference-based 方法切换到具有更高一致性和区分性的 pair-wise battle 配合 VLM-as-a-Judge 方法。
为此,本研究通过构建首个人类标注的大规模评测体系 CapArena(包含 6000 + 高质量人工标注,覆盖 14 个先进 VLMs 与人类表现)发现,顶尖模型如 GPT-4o 首次实现与人类水平相当甚至更优的表现,这是一个惊人的结果,而开源模型与商业模型仍存在显著差距,同时 InternVL2-26B 又凸显了轻量化高效 VLMs 的潜力。
针对评测方法,研究揭示传统指标(如 CLIPScore)对详细描述完全失效,基于规则的指标(如 METEOR)虽在单条描述层面与人类评判部分契合,却存在跨模型的系统性偏差,导致模型排名与人类偏好严重偏离。
最终,我们提出了一个轻量高效的自动化 Detailed Captioning 评测基准CapArena-Auto,通过 600 条样本配合 VLM-as-a-Judge,单词评测 $4 达到了和人类专家 94.3% 的相关性。
基于此,本工作创新提出带参考描述的 VLM-as-a-Judge 方法,其在不同层级均展现与人类判断的高度一致性,并据此发布自动化评测基准 CapArena-Auto——通过 600 样本的成对比较范式,结合三基线模型对比策略,仅需 4 美元/次测试即可实现 94.3% 的人类排名相关性,为高效、可靠的详细描述评估建立新范式。
该成果不仅填补了 LLM 时代图像描述生成的评测空白,更为模型能力诊断、优化迭代及轻量化开发提供了关键工具与方法论支撑。

CapArena 人工评测体系
2.1 CapArena 标注平台
本研究构建 CapArena 评测体系,首次通过大规模人类标注与创新的标注体系,系统评估 14 个先进 VLMs 的详细描述能力,并揭示关键发现。
借鉴 Chatbot Arena,团队构建了 CapArena 平台,突破传统评分制的局限性,参考大语言模型开放域评测经验,设计匿名成对比较法(Pairwise Comparison),以模型间“对战”形式提升评估可靠性。
平台引入创新性的动态优化算法:通过控制采样概率的策略加速模型排名收敛,结合 Bradley-Terry 模型计算置信区间,确保排名统计显著性。
规定 为 次采样的协方差矩阵,那么 时刻对于模型对 的采样概率 设置为:
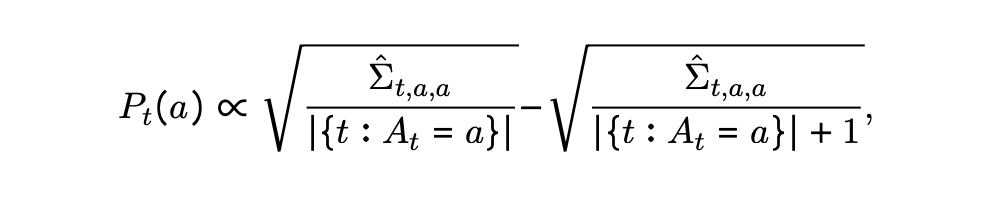
2.2 数据来源与标注协议
研究团队采用 DOCCI 数据集的高分辨率图像及人工撰写长描述作为基础,覆盖多样化真实场景,并精选涵盖商业与开源模型的 14 个 VLMs(如 GPT-4o、Llama-3.2、InternVL2-26B)在图像集上生成描述,设计精简提示词控制生成质量。

评测协议聚焦三大核心维度:精确性(描述与图像细节的严格对齐,如物体属性、空间关系)、信息量(关键内容的覆盖全面性)以及幻觉抑制(对虚构内容的惩罚),同时要求专注于质量(如忽略文本长度干扰、优先质量评估)。通过规范标注协议,有效降低主观偏差。
最终,标注团队完成 6,522 条标注,标注者内部一致性达 0.782,单条标注平均耗时 142 秒。
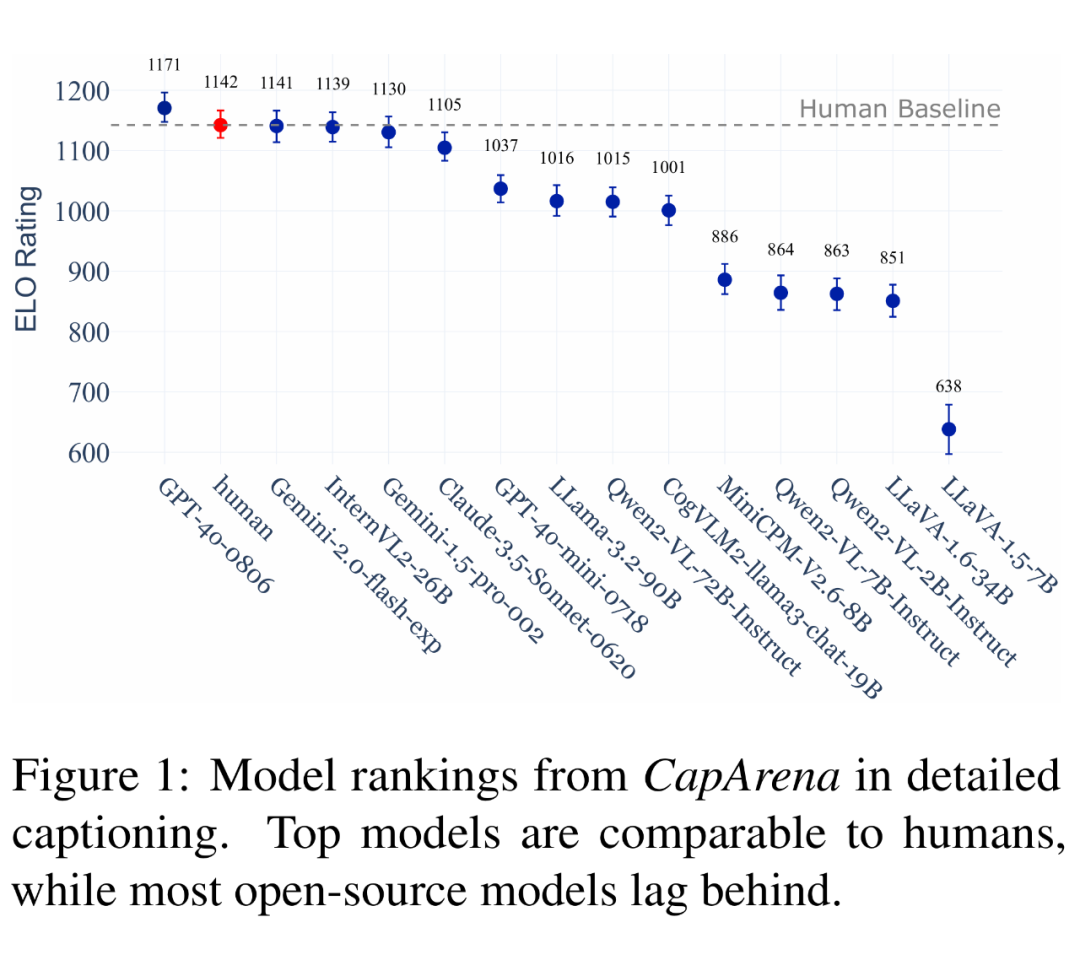
2.3 VLM Detailed Image Captioning 评测结果
评测结果显示三大关键性结论:
其一,顶尖模型首次超越人类水平,GPT-4o 在细节捕捉(如详细动作形态)与信息覆盖度上媲美甚至超越人类标注,标志着模型图像描述能力的突破性进展;
其二,开源模型差距显著,多数开源模型(如 Llama-3.2-90B)在细粒度视觉理解上落后于商业模型,但其中 InternVL2-26B 凭借 6B 视觉编码器脱颖而出,证明高效小模型具有潜力;
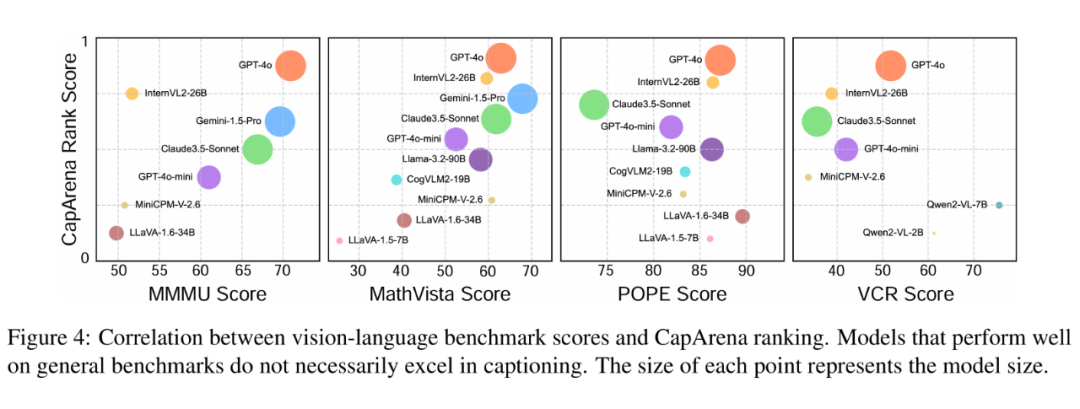
其三,通用评测指标脱节,通用多模态 benchmark(如 MMMU、POPE)与详细 Detailed Image Captioning 能力相关性弱,部分模型在描述任务中表现卓越却在通用任务得分偏低,凸显领域专用评测的必要性。

图像描述 Metric 分析
本研究基于 CapArena 的 6000 + 高质量人类标注数据,系统评估了图像描述传统指标、Detailed Captioning 专用指标及 VLM-as-a-Judge 方法的与人类偏好的一致性。
3.1 Caption-level Agreement and Model-level Agreement
我们选取了两个层面的一致性用来衡量 Metric 的质量:
Caption-level 一致性,计算所有样本对中与人类标注相同的比例,同时也考虑到模型间性能差异,根据胜率,将模型对按照区分的难易程度从易到难分成4个层次;
Model-level 一致性,对于每一个指标给出的 pair-wise battle 结果,使用与人工评测相同的 ELO 分数计算方法得到该指标下模型的排名,并计算与人类标注得到的模型间排名的相关性。
3.2 结果分析
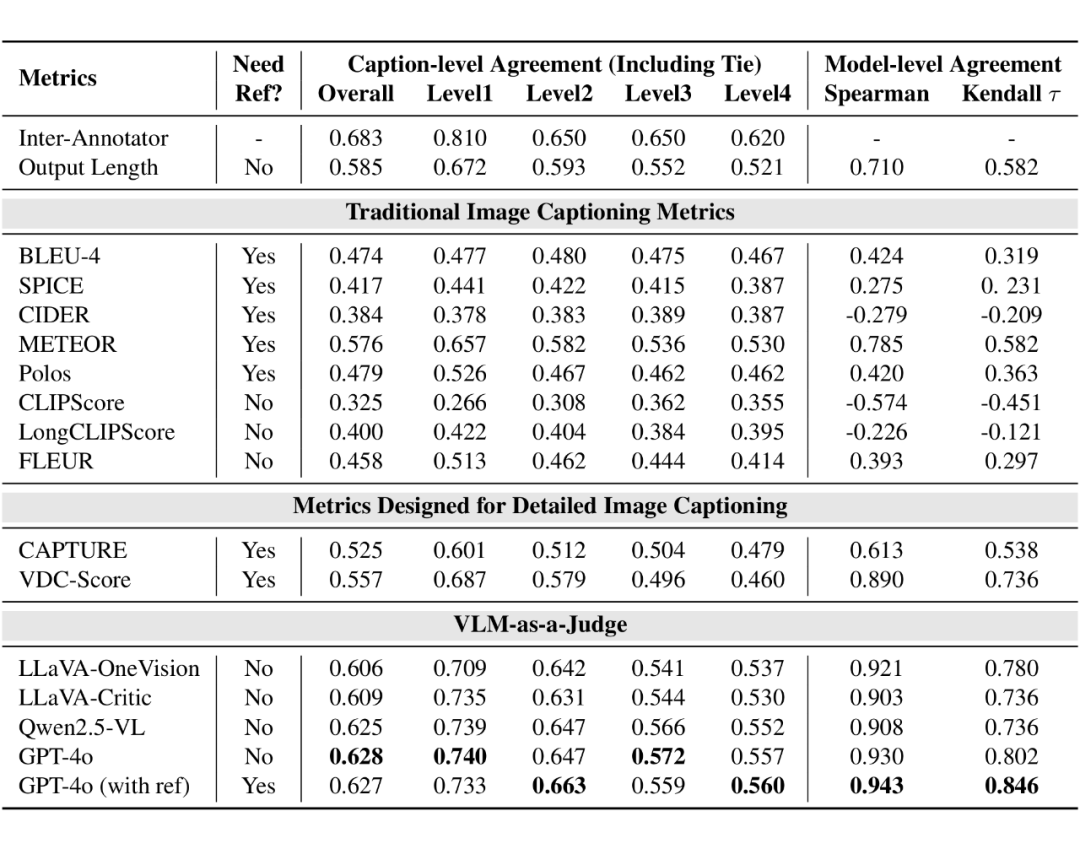
我们发现传统指标全面失效,他们在短描述任务中表现较好,但在详细描述生成任务中表现不佳。
这些指标在长文本和复杂语义对齐方面存在不足,例如基于 n-gram 匹配的指标(如 CIDEr)难以处理详细描述的灵活性。而基于 CLIP 的指标(如 CLIPScore)在处理长文本和复杂语义时,无法有效捕捉图像内容与描述之间的细粒度对齐。
而利用强大的视觉语言模型(如 GPT-4o、Qwen2.5-VL、LLaVA 等)作为评判工具,能够模拟人类偏好。VLM 在详细描述生成任务中表现出更强的辨别能力,尤其是 GPT-4o,其判断与人类偏好高度一致。同时我们发现引入参考描述(reference-enhanced variant)可以进一步提高 VLM 的判断准确性。
此外我们发现一些有趣的现象,传统图像描述指标 METEOR 以及以文本长度为标准的 Output Length(输出越长认为越好)在 Caption-level 上的一致性有着较好的表现,但是在 Model-level 上却无法很好地符合人类偏好。
我们认为这是因为出现了系统性偏差。
3.3 系统性偏差
为了分析这一现象,我们计算了每个模型在所有对战中的平均胜率(即该模型在对战中胜出的比例),并将其与人类标注的 Golden Win Rate 进行比较:如下图所示,红色表示某个指标高估了某个模型,蓝色表示其低估了某个模型,颜色的深浅代表高估或低估的程度。
结果显示,METEOR 和 Output Length 有着整体明显更深的颜色,意味着它们经常性高估或者低估特定模型,即它们对特定模型存在偏见。
而 VLM-as-a-Judge 整体颜色较浅意味着偏见更低,其产生的错误更类似于人类标注者的随机不一致,而非对特定模型的偏好。
因此 VLM-as-a-Judge 有着更高的 Model-level Agreement。
我们发现部分评估指标在对模型进行评价时,可能对某些特定的模型表现出固定的偏好或偏见。
这种偏差不是随机的,而是由指标本身的特性或设计导致的。例如,某些指标可能倾向于高估某些模型的生成结果,而低估其他模型的结果,从而导致对模型性能的估计不准确。
为了分析系统性偏差,我们计算每个模型在所有对比中的平均胜率(即该模型在对比中胜出的比例),并将其与人类标注的 Golden Win Rate 进行比较。
如果某个指标的平均胜率与人类标注的胜率存在显著差异,则认为该指标对某些模型存在系统性偏差。偏差可以是正的(指标高估了模型的性能)或负的(指标低估了模型的性能)。
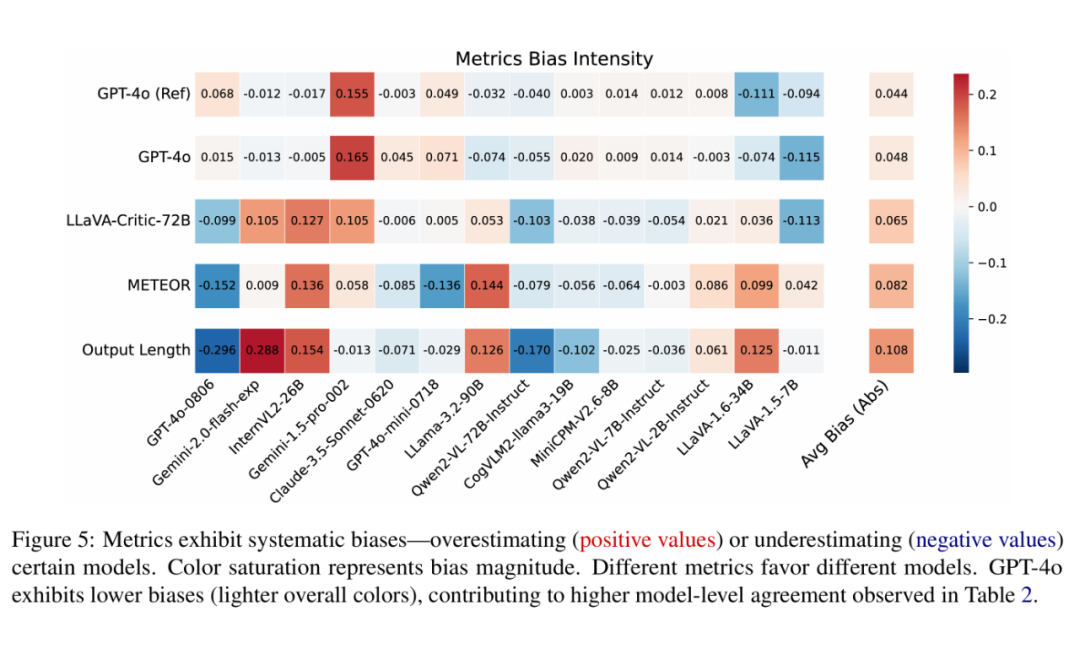
通过可视化偏差分布,直观的展示不同指标对不同模型的偏差程度,GPT-4o-as-a-Judge 的平均偏差为 4.4%,而 METEOR 的平均偏差为 8.2%,这表明 GPT-4o 的偏差更小,说明其与人类判断的不一致更多是由于随机偏好,而非对特定模型的有害偏见,从而使其在模型排名中更具可靠性。
系统性偏差是一个关键问题,因为它可能导致评估指标无法准确反映模型的真实性能。
即使某个指标在单个对比中与人类判断一致率较高(即 Caption-level Agreement 较高),但如果它对某些模型存在固定偏好,那么在整体模型排名中可能会出现偏差(即 Model-level Agreement 较低)。这种偏差会误导模型开发者,使他们无法准确判断模型的优劣。

自动评估基准 CapArena-Auto
最后,为了减少对昂贵且耗时的人工标注的依赖,我们提出了 CapArena-Auto 自动评估框架,用于快速评估详细图像描述生成模型的性能。该框架包含 600 张高质量测试图像,并通过与基线模型的成对对比来评估模型性能。
为了确保测试集的多样性,我们采用了 DOCCI 提供的图像特征聚类方法,从 149 个聚类中均匀采样了 600 张图像。
此外,我们还使用基于 CLIP 特征的过滤方法移除了过于相似的样本,以确保最终选择的图像质量。
我们使用了三个不同性能水平的基线模型:GPT-4o、CogVLM-19B 和 MiniCPM-8B,并选择 GPT-4o 作为评估者,因为它与人类偏好的一致性最高,并提供人类参考描述以辅助判断。
为了计算测试模型的最终得分,我们在每次成对对比中为胜利分配 +1,失败分配 -1,平局分配 0。测试模型在 CapArena-Auto 中的最终得分是其在 600 个测试样本上的得分总和。
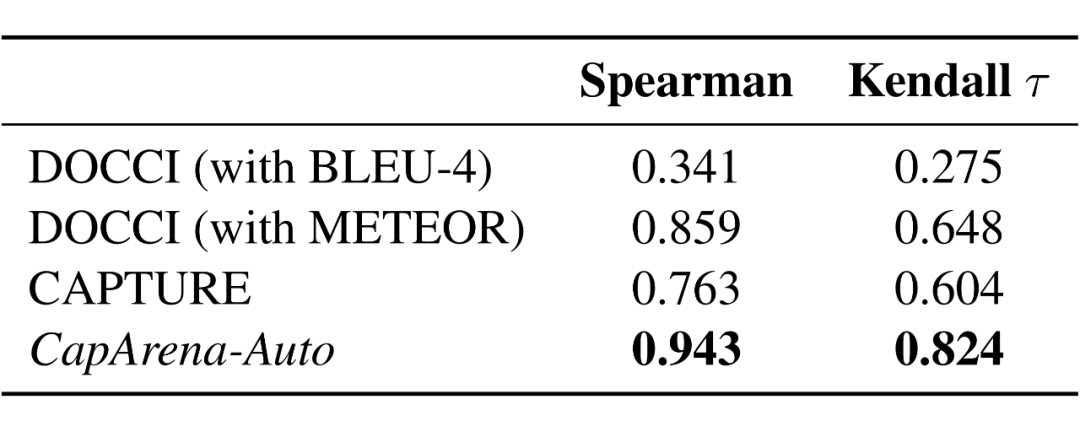
结果证明,CapArena-Auto 在 Spearman 和 Kendall τ 系数上均显著优于现有基准测试,表明其与人类偏好的一致性最高。此外,CapArena-Auto 单次评估的成本仅为 4 美元,使其成为一种轻量高效的详细图像描述评估基准。
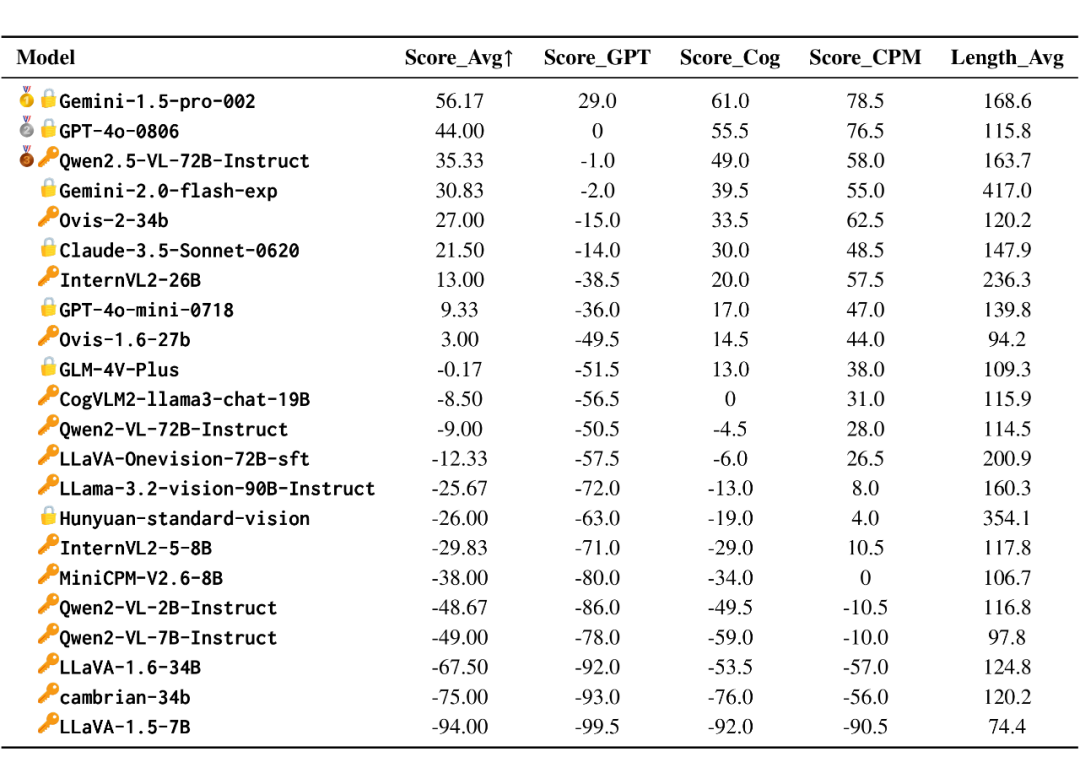

总结
本文探讨了在大语言模型(LLM)时代详细图像描述生成任务的现状。通过大规模人类标注,我们发现当前最先进的视觉语言模型首次达到或超越了人类水平的表现。
同时,我们还深入分析了现有图像描述评估指标,揭示了图像描述评估的一个范式迁移:从传统 reference-based 指标到有着更高一致性和区分度的 VLM-as-a-Judge 评测。
为了推动图像描述研究发展,我们发布了 CapArena-Auto,一个与人类偏好高度一致的自动化基准测试工具,为详细图像描述评估提供了一种经济高效的解决方案。
(文:PaperWeekly)