

作者介绍: 本文作者来自通义实验室 RAG 团队,致力于面向下一代 RAG 技术进行基础研究。该团队 WebWalker 工作近期也被 ACL 2025 main conference 录用。

-
论文:https://arxiv.org/pdf/2505.22648
-
代码:https://github.com/Alibaba-NLP/WebAgent
一、背景:信息检索的新需求与挑战
在当今信息爆炸的时代,解决复杂问题不再仅仅是简单的知识检索,而是需要深入的信息挖掘和多步推理。从医学研究到科技创新,从商业决策到学术探索,每一个领域都呼唤着能够自主思考、自主决策的智能体。Deep Research 等系统已经为我们展示了自主多步研究的巨大潜力,但构建这样的智能体并非易事。它们需要在复杂的网络环境中感知、决策、行动,还要面对任务复杂度高、泛化能力弱等诸多挑战。
但打造这样一个 Deep Research 类智能体智能体,并不简单!
-
它得能看懂网页,能做多步决策;
-
它得能适应开放动态环境;
-
它得能自主提问、自主行动、自主修正……
在这种背景下,WebDancer 的出现,走出了一条复现 Deep Research 类智能体的可行路径。
自主信息检索智能体的构建,或者如何复现 Deep Research 类的模型一直面临着两大棘手难题:高质量训练数据的稀缺与开放环境训练的复杂性。这两大难题如同两座大山,阻挡了众多研究者和开发者前进的步伐。然而,WebDancer 的出现,就像一把锋利的宝剑,成功地劈开了这两座大山,为自主智能的发展开辟了一条全新的道路。
以下是一些运行的 case:
我们可以看到 WebDancer 可以完成多步的信息检索,包含多步思考和 action 执行,在运行过程中进行完成自主的任务拆解、知识回溯和反复验证。
二、训练数据难获得:WebDancer 的创新突破
(一)数据稀缺的困境
在自主信息检索领域,高质量的训练数据至关重要,OpenAI 的 Deep Research 积累了大量的 browsing data。然而,现实情况是,现有的问答数据集大多浅薄且单一,往往只能解决一两步的简单问题。这些数据集不仅数量有限,而且难以反映真实世界中的复杂信息需求。例如,GAIA 数据集仅有 466 个样本,WebWalkerQA 也只有 680 个样本,远远不足以支持有效的训练。此外,许多数据集只有测试集或验证集,缺乏足够的训练数据,这使得智能体的训练面临巨大的挑战。
(二)WebDancer 的数据合成策略
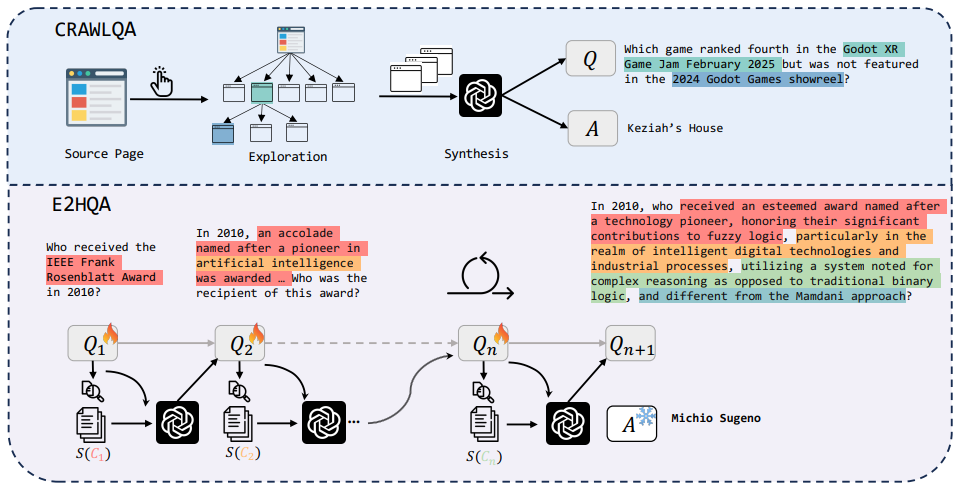
面对数据稀缺的困境,WebDancer 采取了创新的数据合成策略,成功地解决了这一难题。WebDancer 通过两种主要方式构建了高质量的深度信息检索问答数据集:CRAWLQA 和 E2HQA。
-
CRAWLQA:通过爬取网页信息,模拟人类浏览行为,从权威网站中提取有价值的知识,生成复杂的问答对。这种方法不仅能够获取大量数据,还能确保数据的多样性和真实性。
-
E2HQA:通过逐步增强简单问题的复杂度,从易到难构建问答对,激励智能体从弱到强逐步进化。这种方法不仅能够生成复杂的多步问题,还能确保问题的逻辑性和连贯性。
通过这两种方法,WebDancer 成功地构建了海量的样本,极大地丰富了训练数据。这些数据不仅数量庞大,而且质量上乘,为智能体的训练提供了坚实的基础。
(三)ReAct 大道至简,模型内化 agentic 能力
获得 QA 对之后,我们使用广泛使用的 ReAct 框架,用闭源的 GPT-4o 和开源的 QwQ 模型进行长短思维链蒸馏,获得高质量的 agentic 数据。
为什么使用 ReAct,是因为这种方式足够大道至简,满足我们对 Agentic Model 的需求,即只需要给其工具,就可以自主思考、执行、研究。
(四)数据过滤与质量提升
有了大量的数据,如何确保数据的质量呢?WebDancer 采用了多阶段的数据过滤策略,确保了数据的高质量。具体来说,WebDancer 通过以下三个阶段进行数据过滤:
-
1. 有效性控制 :直接丢弃不符合指令的数据。
-
2. 正确性验证 :只保留正确结果的数据。
-
3. 质量评估 :通过规则过滤掉重复或冗余的数据点,确保数据的多样性和逻辑性。
通过这些严格的过滤策略,WebDancer 确保了训练数据的高质量,为智能体的高效学习提供了保障。
二、开放网络环境难训练:WebDancer 的高效解决方案
(一)开放环境训练的挑战
在开放环境中训练智能体是一项极具挑战性的任务。开放环境不仅动态变化,而且部分可观测,这使得智能体的训练变得极其复杂。例如,网络环境中的信息不断更新,智能体需要不断适应新的信息和新的任务需求。此外,开放环境中的任务往往需要多步推理和复杂的决策,这对智能体的泛化能力和适应能力提出了更高的要求。
(二)WebDancer 的两阶段训练策略
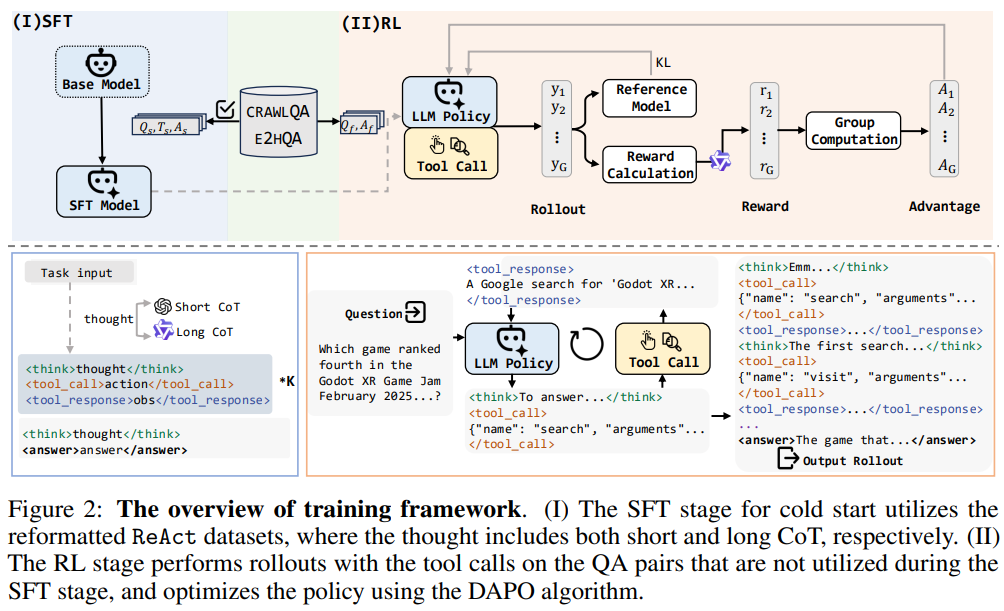
为了应对开放环境训练的挑战,WebDancer 采用了两阶段训练策略:监督微调(SFT)和强化学习(RL)。
监督微调(SFT):SFT 阶段是智能体的 “冷启动” 阶段。通过在高质量轨迹数据上进行微调,智能体能够快速适应任务需求,掌握如何在复杂的环境中进行推理和决策。SFT 阶段不仅提升了智能体的初始性能,还为后续的强化学习打下了坚实的基础。
强化学习(RL):RL 阶段是智能体性能的 “优化器”。通过与环境的交互,智能体不断试错,学习如何在复杂多变的环境中做出最优决策。WebDancer 采用了先进的 DAPO 算法,这种算法能够动态采样,充分利用未被充分利用的数据对,从而提高数据效率和策略的鲁棒性。
(三)高效的数据利用与动态采样
在开放环境中,数据的高效利用至关重要。WebDancer 通过动态采样机制,确保了数据的高效利用。具体来说,DAPO 算法能够动态调整采样策略,优先采样那些未被充分利用的数据对。这种方法不仅提高了数据的利用率,还增强了智能体的泛化能力。
(四)降低强化学习成本
强化学习阶段的高计算成本和时间开销一直是开放环境训练的一大难题。WebDancer 通过优化算法和硬件资源的高效利用,显著降低了强化学习的成本。具体来说,WebDancer 采用了高效的 rollout 机制和并行计算技术,将每次回滚的时间和成本降低到了最低。
三、实验与结果:WebDancer 的卓越表现
WebDancer 的创新策略在 GAIA 和 WebWalkerQA 这两个极具挑战性的信息检索基准测试中得到了充分验证。
(一)GAIA 数据集
GAIA 数据集旨在评估通用人工智能助手在复杂信息检索任务上的表现。WebDancer 在 GAIA 数据集上的表现尤为突出,不仅在 Level 1、Level 2 和 Level 3 的任务中均取得了高分,还在平均分上遥遥领先。这表明 WebDancer 能够在不同难度的任务中保持稳定的高性能,展现了其强大的泛化能力。
(二)WebWalkerQA 数据集
WebWalkerQA 数据集专注于深度网络信息检索。WebDancer 在 WebWalkerQA 数据集上的表现同样出色,尤其是在中等难度和高难度任务中,其性能提升更为明显。这表明 WebDancer 不仅能够处理简单的问题,更能应对复杂的挑战,真正实现了从简单到复杂的跨越。
主实验结果
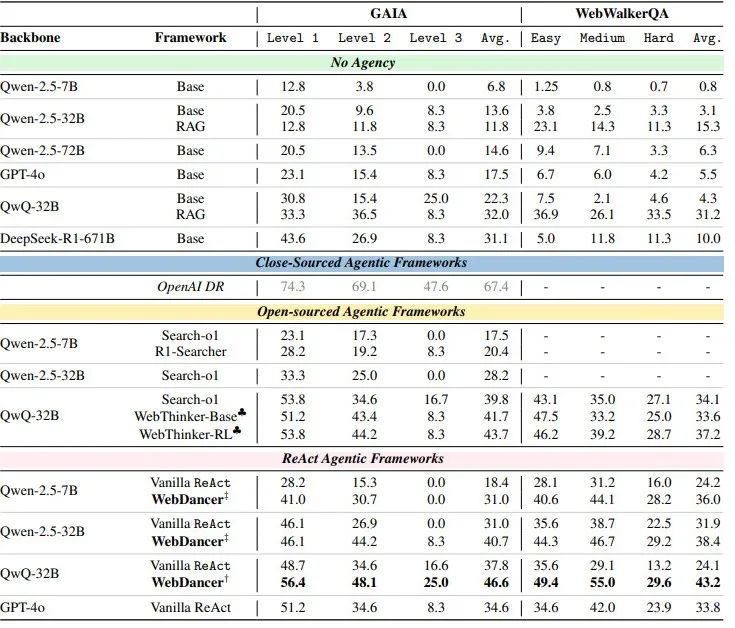
我们分别用短思维链数据训练了 Qwen-2.5-7B 和 Qwen-2.5-32B 模型,长思维链数据训练了 QwQ 模型。实验结果显示,WebDancer 在这些基准测试中取得了显著的成绩,超越了 GPT-4o 等强大的基线模型。
在更具有挑战的信息检索任务上的性能
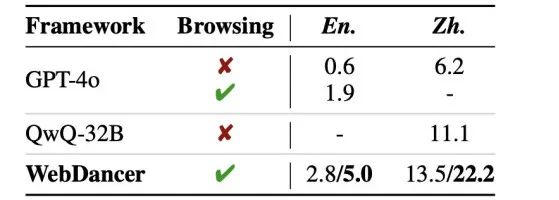
WebDancer 还在 BrowseComp(En.)和 BrowseComp-zh(Zh.)这两个更具挑战性的基准测试中进行了评估。在这些测试中,WebDancer 同样展现出了强大的性能,进一步证明了其在处理复杂信息检索任务方面的鲁棒性和有效性。
实验分析
我们也做了细致的分析实验为后续研究者提供方向。
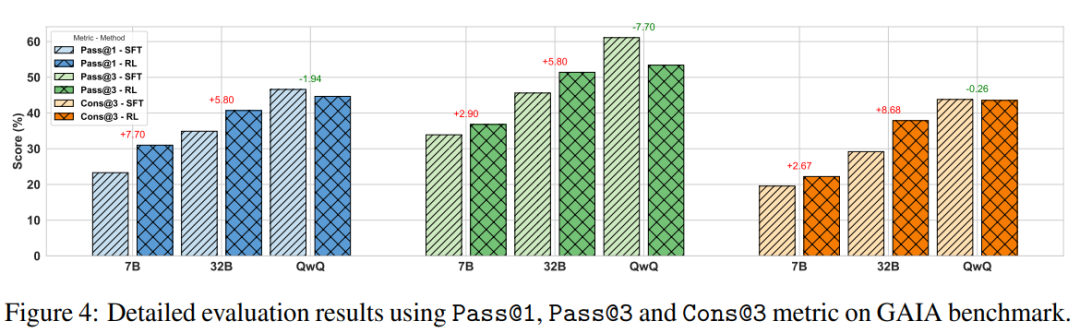
-
分析实验 1: RL 能对普通的 Instruction model 有显著的提升,并且能显著提高 Pass@1 的正确采样效率,使之接近 Pass@3,但对 QwQ 这类 Reasoning 模型提升不是很显著,只能提升采样的稳定性,这可能和整个 agentic 轨迹长有关。
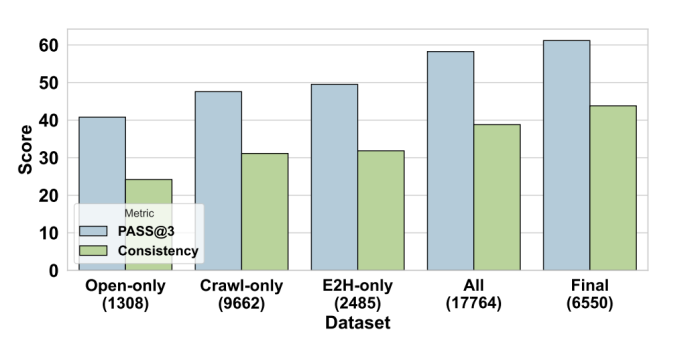
-
分析实验 2: Agentic 数据在于精而不在于多。我们最后仅适用 6k 条长思维链的数据在 QwQ 模型上就能在 GAIA 上获得很好的效果。

-
分析实验 3: 长短思维链 pattern 在不同模型上不好轻易转化学习。虽然长思维链在 instruction model 和 reasoning model 都能得到很好的效果,但是会带来很高的非法率,通常是由重复导致的,在小一点的模型上该现象更明显。
四、未来展望:WebDancer 的新征程
尽管 WebDancer 已经取得了令人瞩目的成就,但它的发展之路还远未结束。未来,WebDancer 将在多个方向上继续探索和创新。
(一)更多工具的集成
目前,WebDancer 仅集成了两种基本的信息检索工具,未来计划引入更多复杂的工具,如浏览器建模和 Python 沙盒环境。这些工具将使智能体能够执行更复杂的任务,如网页浏览、数据抓取、API 调用等,从而拓展智能体的能力边界,使其能够应对更广泛的挑战。
(二)任务泛化与基准扩展
目前的实验主要集中在短答案信息检索任务上,未来 WebDancer 将扩展到开放域的长文本写作任务。这将对智能体的推理能力和生成能力提出更高的要求,需要设计更可靠和更有效的奖励信号。同时,WebDancer 也将参与更多基准测试,以验证其在不同任务类型和领域中的泛化能力。
五、讨论:Post-train Agentic Models
相比于一些驱动于强大的具有很强的 agentic 能力的闭源模型,例如 gpt-o4,claude 的 promtpting 工程框架,本研究的侧重点在从头训练一个具有强大 agent 能力的模型,这对于实现 agent model 的开源以及推进我们对 agent 在开放系统中如何产生和 scale 的基本理解至关重要。我们使用的的原生 ReAct 框架秉持着简洁性,体现了大道至简的原则。
Agentic models 是指那些在交互式环境中,天生支持推理、决策以及多步骤工具使用的 foundation models。这些模型仅通过任务描述的提示,就能展现出诸如规划、自我反思以及行动执行等突发性能力(emergent capabilities)。
近期的 DeepSearch 和 Deep Research 等系统,展示了强大的底层模型如何作为智能体的核心,通过其对工具调用和迭代推理的天然支持,实现自主的网络交互。然而,由于网络环境本质上是动态的且部分可观察的,强化学习在提升智能体的适应性和鲁棒性方面发挥了关键作用。在本研究中,我们的目标是通过有针对性的后训练(post-training),在开源模型中激发自主智能体的能力。
六、结语:WebDancer,开启自主智能的新时代
WebDancer 的出现,不仅是信息检索领域的一个重大突破,更是自主智能发展的一个重要里程碑。它通过系统化的训练范式,从数据构建到算法设计,为构建长期信息检索智能体,开源模型复现 Deep Research 提供了清晰的指导。WebDancer 的成功,让我们看到了自主智能体在未来科学研究、教育和生产力提升中的巨大潜力。
©
(文:机器之心)