

视频理解是通往 AGI 的必要路径。当前视频理解的探索主要集中于视频事件内容,人物动作,关系等。然而,嵌入视频中的可视文字却往往被忽略。从视频字幕到场景文字(街头招牌,道路指示牌),这些视频文本对于推理视频的内容,人物行为等提供了重要线索。
针对于此,来自哈工大,特伦托大学,北大,中科院,北航,南理工和南开大学的研究者们联合提出了 VidText,旨在提供视频文本理解的系统性基准:

论文标题:
VidText: Towards Comprehensive Evaluation for Video Text Understanding
论文链接:
https://arxiv.org/pdf/2505.22810
项目链接:
https://github.com/shuyansy/VidText


VidText 的三大核心亮点
1. 全场景、多语言覆盖
VidText 涵盖媒体、娱乐、体育、知识、生活记录等 27 个真实视频场景,涵盖了丰富的视觉文本场景,例如场景文本和字幕。此外,它还支持多语言评测,包括英语、中文、韩语、日语和德语。
2. 多粒度任务设计
-
视频级(Holistic Level):视频级任务涉及对全局视频内容进行整体 OCR 理解和推理。
-
片段级(Clip Level):片段级任务需要基于特定时间片段的局部理解。
-
实例级(Instance Level):实例级任务需要对单个文本实例进行细粒度的时间和空间定位,以支持精确的问答。
3. 感知-推理任务全链路评估
VidText 涵盖了从视觉文本感知到基于视觉语境的跨模态推理。基于精心标注的视频文本数据,我们生成了以视频文本为中心的思维链(CoT)标注,清晰地捕捉视频描述与嵌入文本之间的推理过程,包括与周围物体的空间关系以及与动作或事件相关的时间依赖关系。
通过这种方式,我们将视频文本感知任务扩展至相应的推理任务,形成一个涵盖八个任务、涵盖多个理解层面的全面配对感知推理框架。
根据以上设计原则,VidText 提出了以下 8 个子任务

1. Holistic OCR(全局文字识别)
模型需要识别视频中完整出现过的所有视觉文本,涵盖整个视频的时空范围。目标是考察模型的全局视频文字感知能力,包括跨时间整合不同帧中出现的文字实例,去重、排序后输出完整的文字列表。
2. Holistic Reasoning(全局推理)
基于 Holistic OCR 识别到的文本,结合视频全局语义信息,模型需要理解视频整体主题或事件。该任务评估模型整合跨时间文本线索与多模态背景信息进行高层语义推理的能力。
3. Local OCR(局部文字识别)
模型在指定的局部视频片段(如用户定义的片段或标注片段)中识别出现的视觉文本。考察模型在局部时间窗口内进行有效文本检测与识别的能力。
4. Local Reasoning(局部推理)
基于局部片段内识别出的文字及上下文场景,模型需回答与该局部语义相关的推理问题。主要考察模型利用局部视觉文本与场景信息完成细粒度语义理解的能力。
5. Text Localization(文本时间定位)
给定指定文本,模型需要预测该文本在视频中出现的时间段(起止时间)。该任务考察模型对视觉文本跨时间动态出现规律的检测与定位能力。
6. Temporal Causal Reasoning(时序因果推理)
在 Text Localization 的基础上,模型需推理该文本与视频事件或动作之间的时序因果关系。重点评估模型理解“文本出现”与“事件发生”之间因果逻辑的能力。
7. Text Tracking(文本空间跟踪)
针对指定的文字实例,模型需预测其在首次出现与消失时的空间位置(即空间 bounding box)。考察模型对动态视频场景中视觉文本在空间维度的持续追踪与识别能力。
8. Spatial Reasoning(空间推理)
在 Text Tracking 的基础上,模型需推理指定文本与其周围视觉对象的空间关系(如上下、左右、包含、邻近等)。评估模型对视觉文本与场景中其他元素之间空间结构关系的理解与推理能力。
详细分析 MLLMs 在 VidText 上的表现
我们在 VidText 上对 18 个主流多模态大模型(MLLM)进行了系统性评测,包括 GPT-4o、Gemini 1.5 Pro、VideoLLaMA3、Qwen2.5-VL、InternVL2.5 等,实验结果如下:
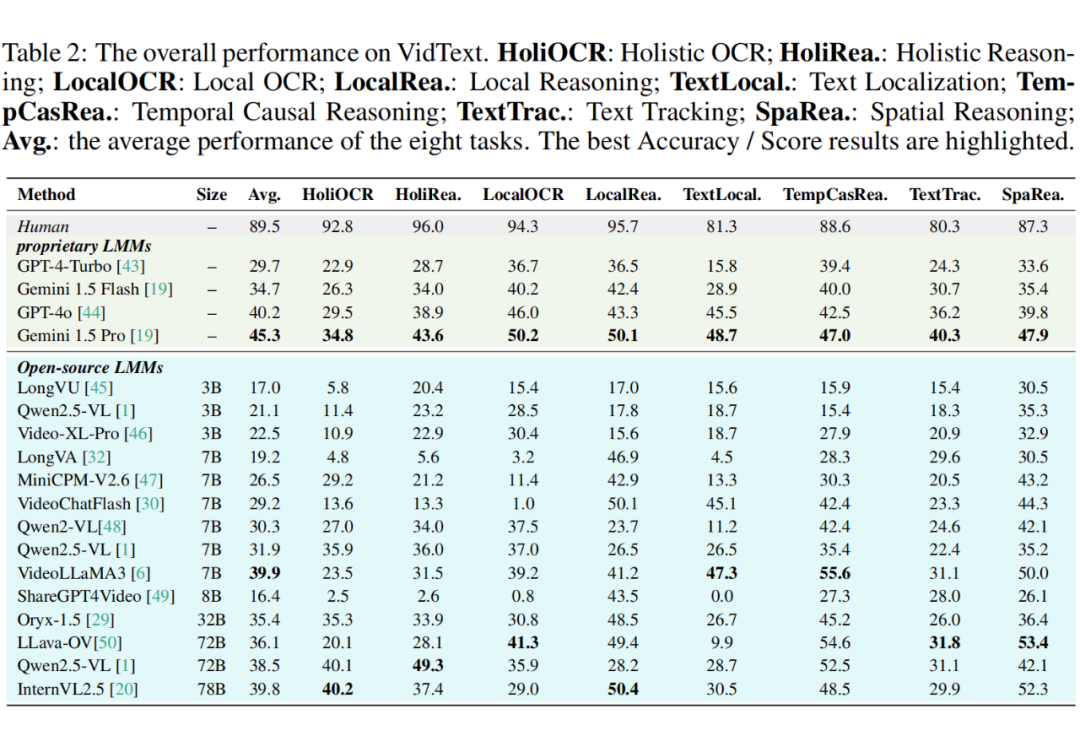
实验结果发现:
(1)视频文字理解任务极具挑战性,当前模型仍远低于人类水平。
(2)在多粒度任务中,视频级别任务和实例级别任务难度高于片段级别任务。因为前者需要视频全局理解,而后者需要细粒度的文字实例理解。
(3)扩大语言模型的规模有助于提升推理任务的效果,但对于感知任务的增益不大。
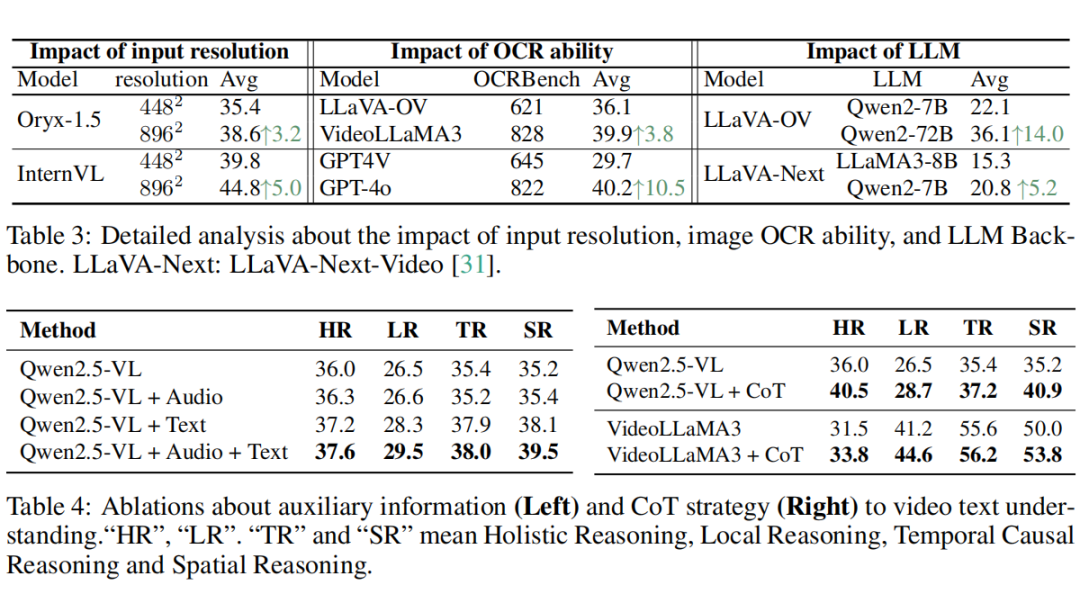
在进一步的实证研究中,我们揭示了影响视频文本理解性能的若干关键因素:
1. 输入分辨率:高分辨率输入可显著提升文本细节保留与检测能力;
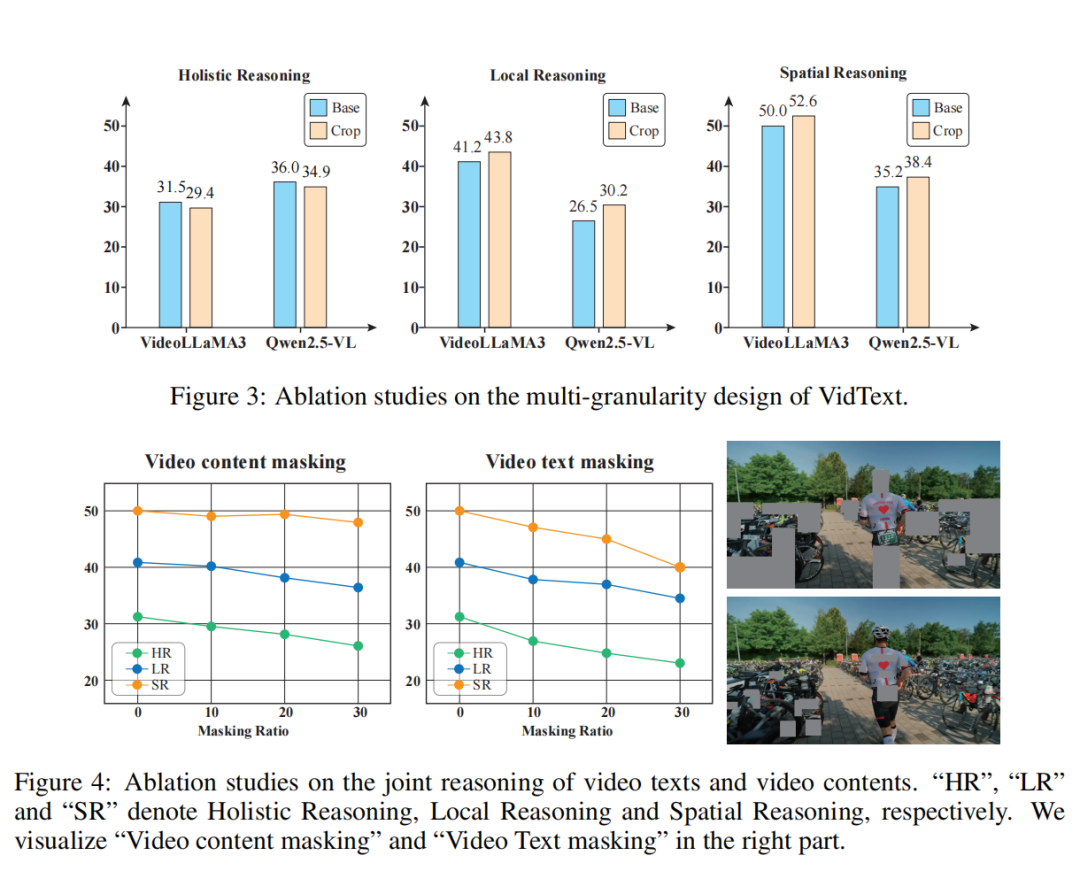
2. OCR 感知能力:图像 OCR 能力是视频文本理解能力的基础。
3. 语言模型的选择:如 Qwen 系列在多语言场景下优势明显,LLaMA 系列表现稍弱;
4. 辅助信息引入:字幕、OCR 结果等外部信息可提升整体语义推理效果;
5. 链式推理(Chain-of-Thought)策略:通过逐步推理引导,有效提升模型跨模态复杂推理能力,在各类推理任务中均带来性能增益。

总结
VidText 系统性填补了视频理解领域长期缺乏“视频内文本建模与推理”能力评测的空白,它有望推动大模型在跨模态时序推理、多粒度感知、多语言理解等方面迈向新的研究方向,为多模态大模型走向实际视频分析与理解应用场景奠定基础。
(文:PaperWeekly)