

近日,抖音内容技术团队开源了 ContentV,一种面向视频生成任务的高效训练方案。该方案在多项技术优化的基础上,使用 256 块 NPU,在约 4 周内完成了一个 8B 参数模型的训练。尽管资源有限,ContentV 在多个评估维度上取得了与现有主流方案相近的生成效果。
该工作探索了在有限算力条件下训练视频生成模型的可行路径。目前,推理代码与模型权重已对外开放。

-
论文标题:ContentV: Efficient Training of Video Generation Models with Limited Compute
-
技术报告:https://arxiv.org/abs/2506.05343
-
代码仓库:https://github.com/bytedance/ContentV
-
模型权重:https://huggingface.co/ByteDance/ContentV-8B
-
项目主页:https://contentv.github.io
我们先来看一些效果展示视频:
✨ 核心亮点
🔧 极简设计
CogVideoX、HunyuanVideo 和 Wan2.1 等一系列优秀的开源工作表明,视频生成的关键并不在于架构上的特殊设计,而在于如何高效利用有限的数据资源,并有效对齐人类偏好。
为验证 ContentV 方案的通用性,本次开源的版本在扩散模型部分采用了经典的文生图模型 Stable Diffusion 3.5 Large。为了适配视频模态,模型在结构上仅做了以下两项必要调整:
-
将原始图像 VAE 替换为 Wan2.1 中使用的 3D-VAE;
-
将 2D 位置编码升级为 3D 版本。在具体编码方式上,团队对比了传统的绝对位置编码与主流的旋转位置编码。评估结果显示,两者在客观指标和主观感受上差异较小,因此保留了计算更高效的绝对位置编码方案。
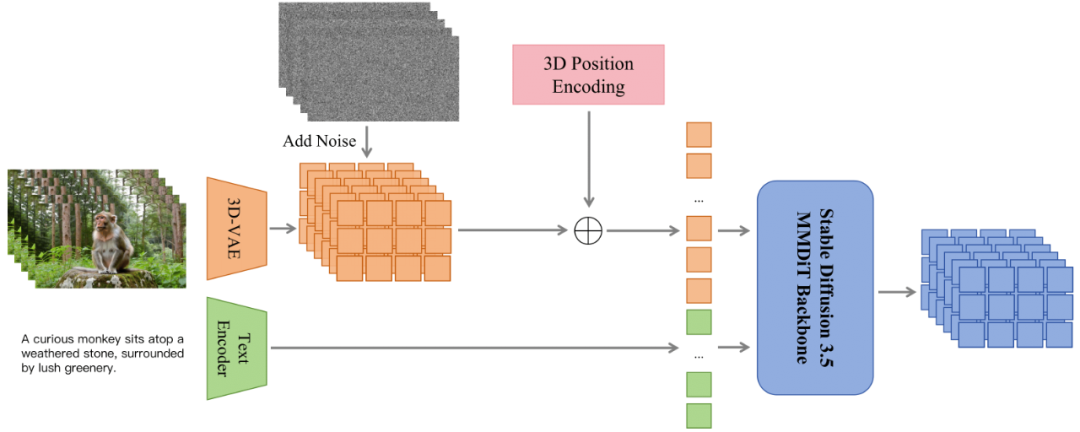
ContentV模型结构
🧠 多阶段渐进训练策略
上述的最小化结构改动,在解锁了视频生成能力的同时,也最大限度地保留了原模型的图像生成能力。实验证明,在新的 VAE 和位置编码的适配阶段,沿用 Flow Matching 的训练方式,仅需 1000 步左右的微调,就能基本还原模型的图片生成能力,大幅节省图片预训练阶段的训练成本。
在视频生成的预训练阶段,为加速收敛实现高效训练,研究团队设计了一套从「低清短片」到「高清长片」的多阶段渐进式训练流程,逐步引导模型学习时间维度与空间维度上的动态表征,从而提升视频的连续性、动态表现力和画面细节。
此外,实验证明,在推理阶段引入非线性采样步长机制(Flow Shift)能够显著提升视频的整体生成质量。通过多组对比实验,团队最终确定了最优的采样策略,进一步优化了生成效果。

VAE适配过程
⚡ 轻量级 RLHF 强化训练

RLHF显著提升画面质感
在后训练阶段,除了使用高质量数据集进行微调外,通过 RLHF 或 DPO 等对齐人类偏好的监督训练,也能显著提升视频生成质量。然而,这类方法通常依赖大量人工标注,用于训练奖励模型或直接监督扩散模型。同时,相较于图像,视频的序列长度显著增加了 RLHF 和 DPO 的训练资源需求。
为此,ContentV 研究团队提出了一种轻量级的 RLHF 训练方案,旨在不依赖人工标注的前提下,低成本提升视频质量:
-
利用开源的图像奖励模型对生成视频的单帧进行监督。相较于视频场景,目前图像奖励模型的训练数据更易获取,且在实际效果中表现更佳。实验证明,由于 MM DiT 采用全局注意力机制,仅优化单帧即可带动整体视频质量的提升;
-
将监督范围限制在生成视频的前 1 秒,相较于对完整视频进行监督,可大幅减少训练资源的消耗,同时获得相近的质量提升效果。
采用上述策略后,在无需人工标注的情况下,仅使用少量训练资源,便可显著提升画面质量。RLHF 微调后,模型在视觉质量(VQ)指标上的表现大幅提升,评估胜率高达 89.38%。
🏆 效果对比
在 VBench 这一主流视频生成评测基准上,ContentV(8B)取得了 85.14 的综合得分,表现优于多个现有的商业闭源模型,包括 Sora、Kling 1.6 和 Gen-3 等。
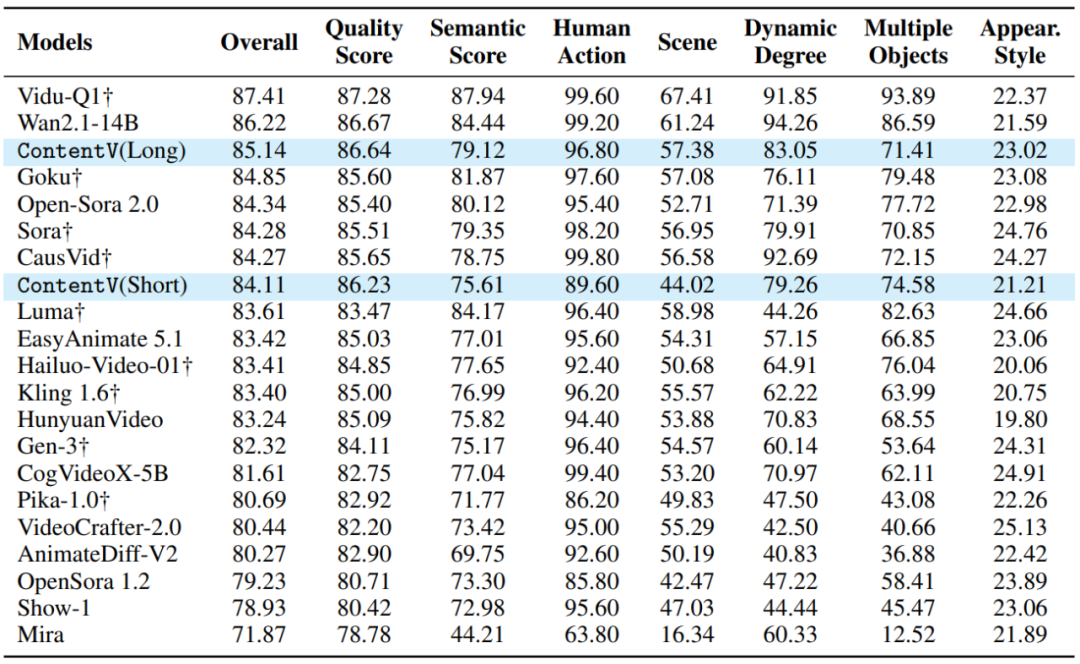
VBench 榜单 (按照 Overall 分数降序排列)
为更贴近真实用户偏好,研究团队围绕感知质量、指令跟随、物理一致性和视觉效果四个维度开展了人类偏好评估。结果显示,ContentV 在整体表现上与 CogVideoX-5B、HunyuanVideo-13B 和 Wan2.1-14B 等主流开源模型相比具有一定优势。
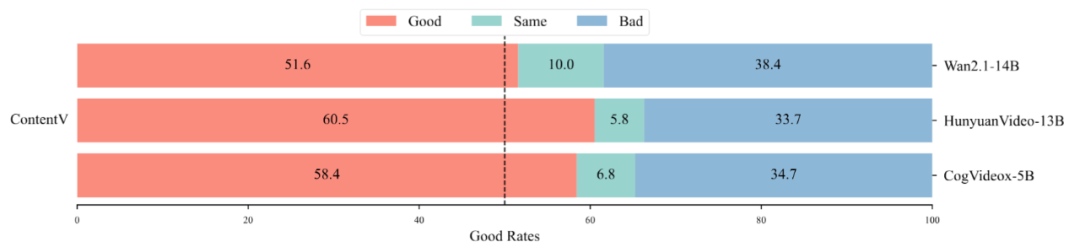
人类偏好评估指标
©
(文:机器之心)