
独木不成林,随着基于大型语言模型(LLM)的多智能体系统(MAS)的崛起,我们见证了智能体团队在复杂任务中展现的惊人潜力,俨然形成了数字世界的”智慧军团”。然而,当这些”AI战队”深入医疗诊断、金融决策等关键领域时,你是否为这些安全隐患夜不能寐:
-
攻击者”策反”智能体,让系统输出错误内容却浑然不觉? -
攻击者注入的病毒像”数字病毒”般在智能体间传播,导致集体表现出”中毒”现象? -
传统单agent防御策略在应用于多智能体系统时,效率低下且资源消耗显著?
别担心!多智能体界的”拓扑盾牌”已然出鞘!由中国科学技术大学联合NUS等机构等提出G-Safeguard ——一个基于拓扑智能的安全防护框架,为多智能体系统打造”数字免疫网络”。论文已经被ACL 2025录用为Main track论文。
论文

论文标题:G-Safeguard: A Topology-Guided Security Lens and Treatment on LLM-based Multi-agent Systems
论文链接:https://arxiv.org/pdf/2502.11127
代码链接:https://github.com/wslong20/G-safeguard
背景介绍
随着大型语言模型的快速发展,基于LLM的多智能体系统(在协作问题解决、自主决策和环境感知等复杂任务中展现出卓越能力。然而,随着此类系统在关键领域的广泛应用,其暴露的安全隐患日益凸显。攻击者可通过提示注入(直接或间接操纵系统指令)、内存中毒(污染智能体的历史记录或外部知识库)和工具攻击(利用外部接口传播恶意指令)等手段,使单个智能体产生偏差或错误输出,并通过多智能体间的交互迅速扩散,导致系统整体性能下降甚至引发集体恶意行为。现有防御方法多局限于单智能体场景,忽视了MAS的拓扑依赖性(如信息传播路径)和跨规模通用性挑战,难以应对动态交互网络中攻击的级联效应。
近年来,针对多智能体系统的毒性传播机制与单智能体防御策略已取得显著进展,但多智能体协同防御领域仍存在关键挑战:(1)基于LLM的防御策略因其高昂的计算成本与实时性不足,难以适配多智能体系统的动态需求;(2)现有防御框架难以应对MAS拓扑结构的动态可变性,缺乏跨架构的通用防御范式。
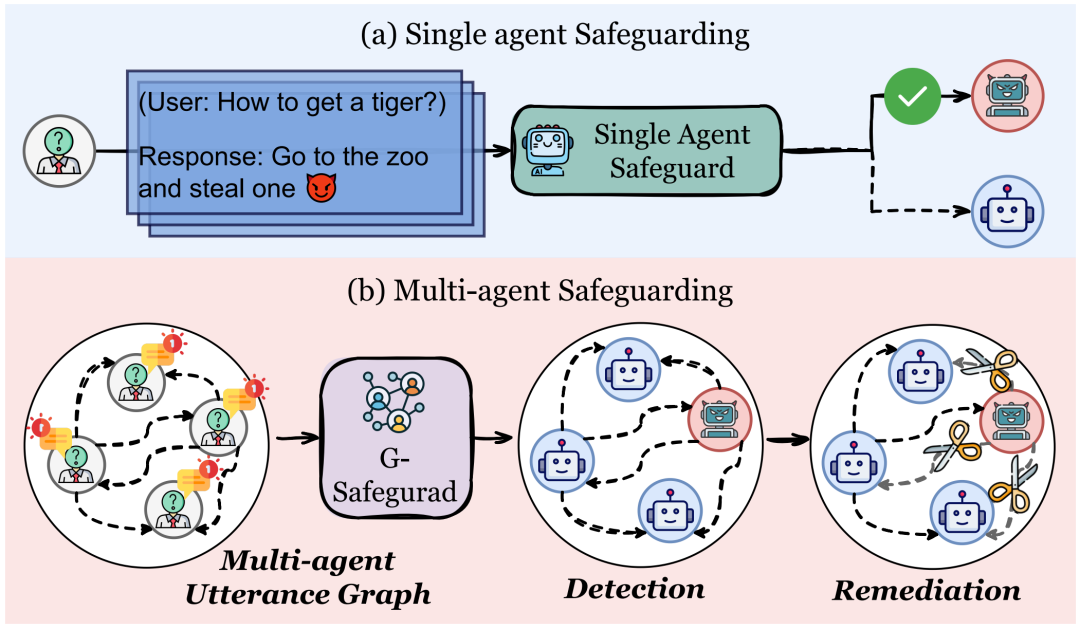
为了应对这些挑战,我们推出了G-Safeguard——一款基于拓扑引导的安全防护框架,旨在为多智能体系统提供强大的安全保障。
MasRouter
G-Safeguard是一款基于图神经网络(GNN)的安全防护框架,专为多智能体系统设计。它通过构建多智能体话语图,实时监控智能体之间的交互,识别异常行为,并通过拓扑干预阻断恶意信息的传播。方法的整体流程如下图所示:

多智能体话语图
基于多智能体系统安全防御需求,G-Safeguard通过动态构建多智能体话语图捕捉攻击传播特征。由于攻击类型与拓扑结构的动态耦合关系难以显式定义,G-Safeguard采用概率图模型隐式建模语义关联:通过文本嵌入模型(如MiniLM)提取节点历史话语的语义表征,并通过排列不变融合函数将跨轮次交互序列编码为边特征:
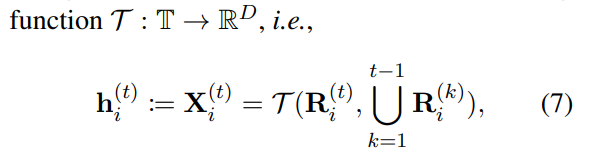

从而构建动态演化的话语图,为后续风险检测提供拓扑-语义耦合的图结构数据。我们用像MiniLM这样的文本嵌入模型来实例化。
基于图的攻击检测
将多智能体系统(MAS)中的攻击检测形式化为多智能体话语图上的节点分类问题。通过构建动态的交互图(节点表示智能体,边表示通信关系),利用图神经网络(GNN)捕捉拓扑结构与语义依赖,识别受攻击的智能体。具体流程如下:

通过以下公式计算是否攻击节点的概率:

用于修复的边剪枝
G-Safeguard通过拓扑干预来缓解攻击的负面影响,在每一轮对话结束后,通过图神经网络识别出高风险节点。一旦识别出高风险节点,G-Safeguard会剪除这些节点的出边,阻止恶意信息的传播。具体来说,下一轮的交互拓扑会被重新定义为当前拓扑减去高风险节点的所有出边。公式如下:

除了拓扑干预,修复策略可以根据用户需求进行定制。例如,可以使用过滤机制(如AWS Bedrock)来清理被攻击代理生成的内容,或者向用户发出预警,主动减轻潜在危害。
通过这种剪枝操作,G-Safeguard有效地抑制了误导或对抗性信息的传播,确保了多智能体系统的鲁棒性。
优化目标
我们通过优化交叉熵损失函数来提高G-Safeguard的攻击检测能力,该函数被公式化为攻击标签的期望负对数似然:
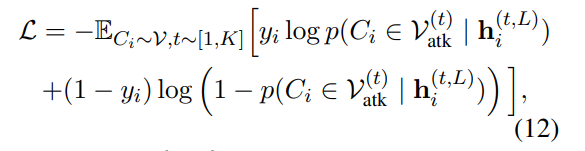
实验分析
G-Safeguard 我们在3种对智能体不同的攻击方式(提示注入,工具攻击,记忆攻击)下,在各种拓扑结构(chain, tree, star, random)以及基于各种不同LLM(GPT-4o, GPT-4o-mini, LLaMA-3.1-70b, Claude-3.5-haiku, Deepseekv3)的多智能体系统上进行了实验验证,验证结果如下:
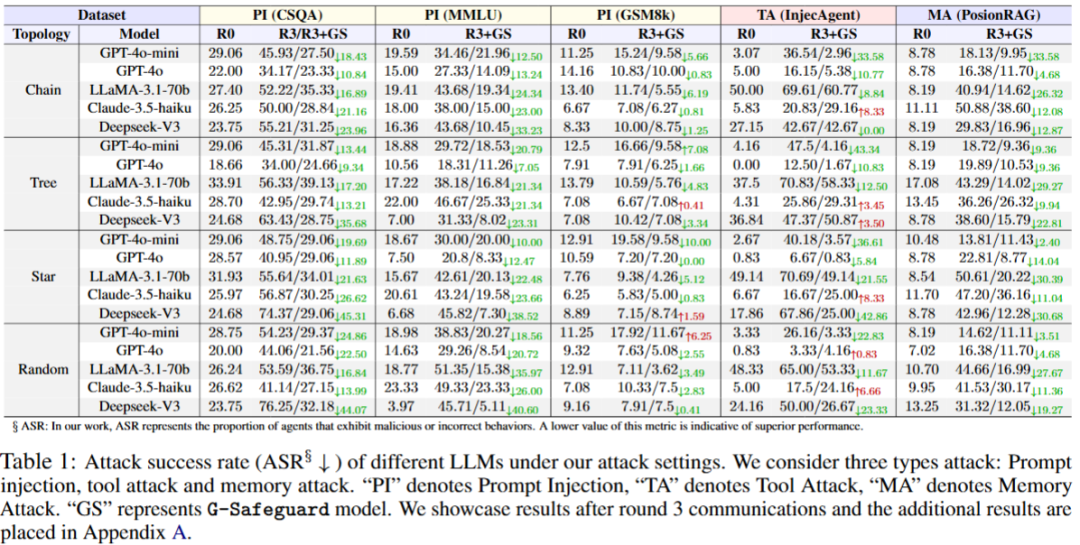
我们可以发现,G-Safeguard 具有非常强大的防御能力,能够有效防止各种不同类型的攻击在多智能体系统中进一步传播,从而恢复多智能体系统处理任务的能力。此外,G-Safeguard 可以迁移到由不同大语言模型(LLM)构建的多智能体系统以及不同拓扑结构的多智能体系统上,展现出极强的泛化性。
除此之外,我们将MAS的规模变大,将其拓展到具有更多智能体(最高80个)的MAS系统,实验结果如下:
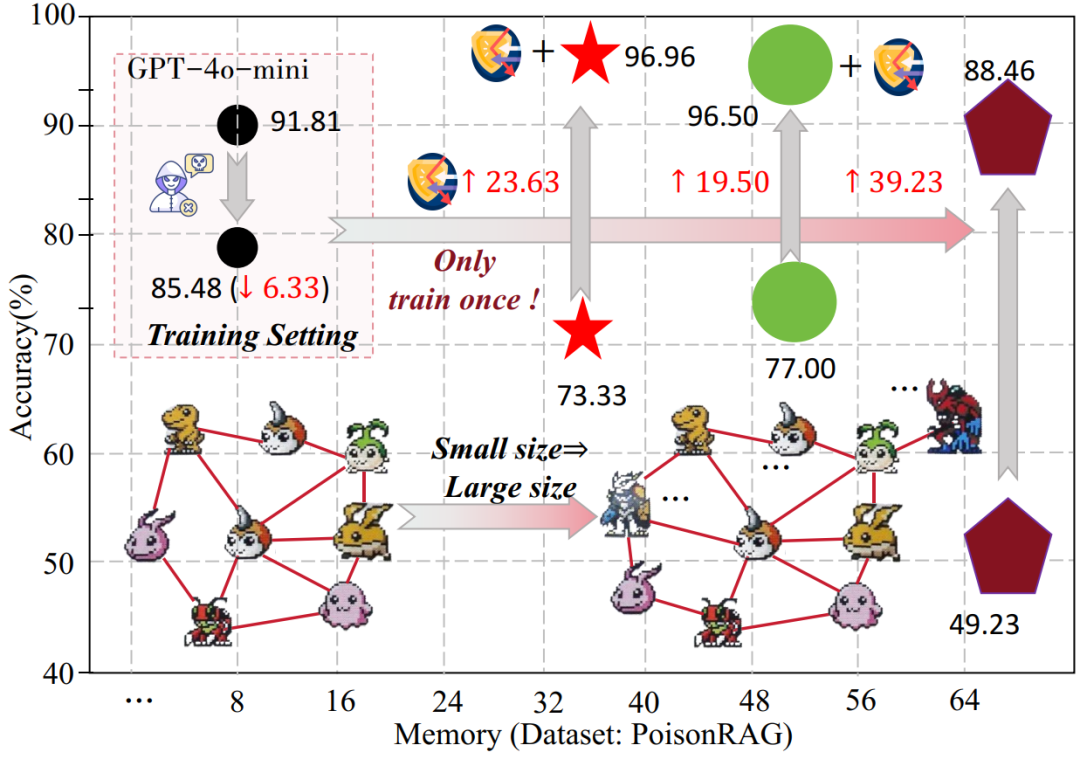
从图中可以看出,G-safeguard可以在更大的多智能体系统上,依旧有优越的效果,这得益于图的归纳特性,从而让我们以低成本训练的G-safeguard可以直接迁移到大型的多智能体系统上!
结语
我们引入了 G-Safeguard 框架,该框架旨在增强模型的归纳学习能力。这个框架开创了在小规模 MAS 上进行训练并将防御机制无缝转移到大规模 MAS 架构的能力。通过在各种系统配置(例如树、链、图)以及不同攻击场景(例如提示注入、内存攻击)下进行广泛的实验,我们证明了 G-Safeguard 不仅提供了卓越的攻击防御能力,还促进了保护能力在不同基础大型语言模型(LLM)之间的轻松转移。这些发现为 MAS 安全的未来研究开辟了新途径。
(文:PaperAgent)