

新智元报道
新智元报道
【新智元导读】AI芯片战争进入白热化! AMD在Advancing AI大会发布了3nm工艺的MI355X以1850亿晶体管、288GB HBM3e显存实现最高2.2倍于英伟达B200的推理性能;明年推出的MI400系列更将搭载423GB HBM4显存。
就在昨天,AMD Advancing AI大会上,AMD董事长兼首席执行官苏资丰一口气推出了其史上最强的AI新品组合!

这些新产品有:
-
AMD Instinct MI350系列AI芯片
-
AMD Instinct MI400系列AI芯片(明年推出)
-
全新AI软件栈ROCm 7.0
-
「Helios」AI机架级基础设施(明年推出)
-
全新AMD开发者云

其中Instinct MI350系列,包括MI350X和旗舰MI355X,基于台积电3纳米工艺节点的全新CDNA 4架构,集成高达1850亿个晶体管。
这两款芯片的主要区别在于散热方式不同,前者使用风冷,后者使用更先进的液冷。
新芯片支持最新的FP6和FP4人工智能数据类型,并配备了超大容量的HBM3e内存。

在FP6推理精度上,AMD Instinct MI355X相比B200有2.2倍的速度提升。

现场,苏妈还补充了MI400系列的细节。
MI400将采用HBM4显存,每颗GPU提供423GB容量,并通过Pensando网卡支持300GB/s的连接,将于明年推出。
性能相比Instinct MI355X又是巨大的飞跃。
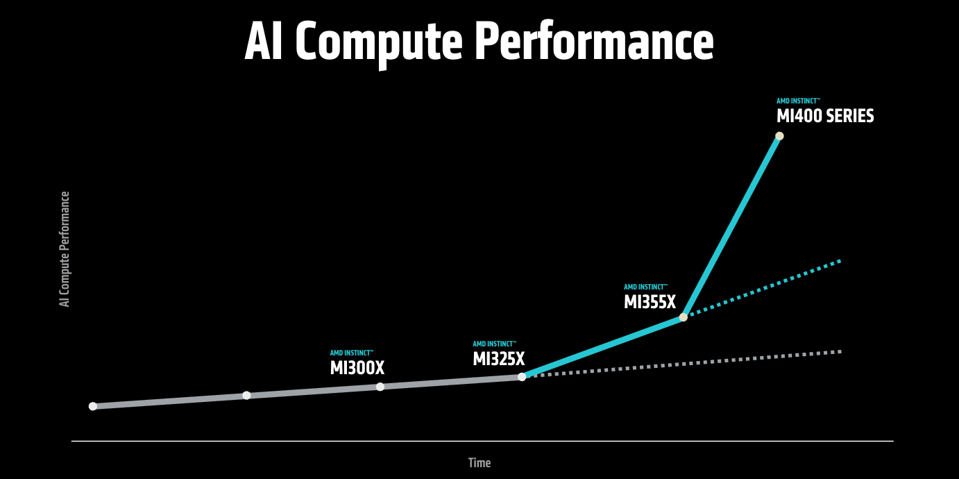
基于MI400系列芯片的AMD首个AI机架「Helios」,也将在明年推出。
Helios支持将多达72个MI400集成,支持高达260T/s的扩展带宽,FP4峰值算力达到了2.9EFLOPS。
「这是世界上最好的AI机架解决方案」,苏妈表示。


现场的一个亮点是OpenAI CEO奥特曼作为嘉宾压轴出场,他表示OpenAI将使用AMD的AI芯片。
苏妈表示对与OpenAI的合作感到兴奋。
「当你最初向我介绍规格时,我简直不敢相信,那听起来太疯狂了,」奥特曼说「不过这东西绝对会很厉害」。

AMD的机架式设计会让芯片看来就像一个整体系统,这对大多数客户,比如云服务商和大语言模型公司来说非常重要。
这些客户想要的就是「超大规模」的人工智能计算集群,能覆盖整个数据中心,当然耗电量也会超级大。
「可以把Helios想象成一个机架,但它运作起来就像一台超强的单体计算引擎,」苏妈说。

AMD的新机架技术令苏妈有底气与黄仁勋掰掰手腕。英伟达是AMD的主要也是唯一的对手。
据透露,英伟达的大客户OpenAI一直在给AMD的MI400系列芯片提建议。
这种芯片功耗更低,运行成本更便宜,而且AMD采用激进的定价策略来挑战英伟达。
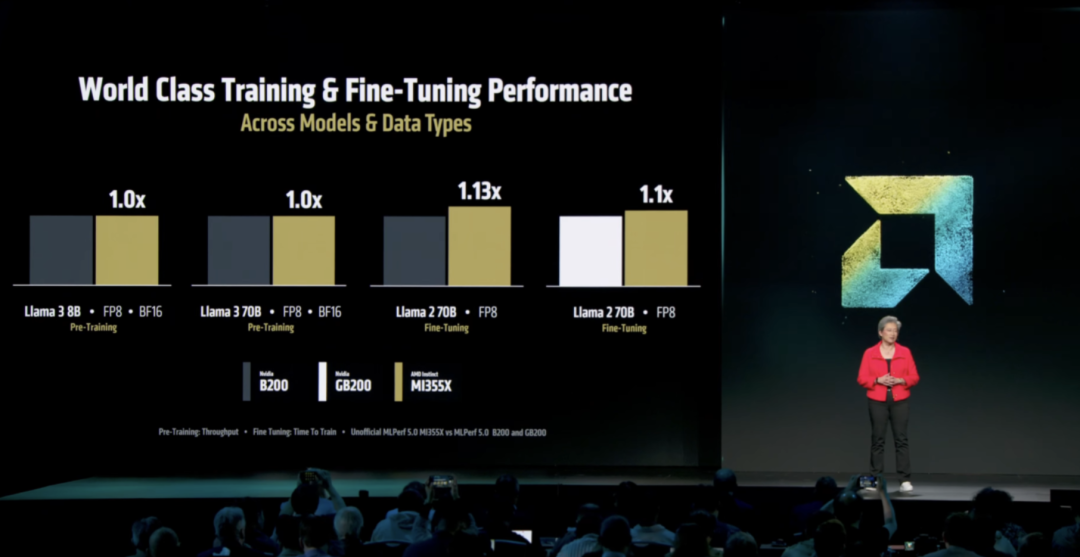
苏妈表示,尽管英伟达有独家的CUDA软件,但即使MI355X芯片性能就可以超过英伟达的Blackwell芯片。
「这说明我们的硬件很强,也表明开源软件框架取得了巨大进步,」苏妈说。

AMD Instinct MI350系列是AMD迄今为止最先进的生成式AI平台,标志着数据中心AI计算的重大突破。
这款芯片采用3nm制程工艺,集成了1850亿颗晶体管,基于AMD CDNA 4架构,配备288GB HBM3e内存,内存带宽高达8TB/s。
单颗MI350 GPU即可运行参数量高达5200亿的大型模型,展现了其在AI训练和推理中的强大能力。

MI350系列在FP4/FP6精度下的峰值算力达到20PFLOPS,是上一代MI300X的4倍,其推理性能更是提升了35倍。
在运行DeepSeek R1模型时,MI350系列的推理吞吐量超越了英伟达B200,展现出强劲的竞争力。
MI350系列包括MI350X和MI355X两款产品,均采用相同的计算架构和内存配置。

相比MI300系列,MI355X在低精度数据类型处理上进行了大幅优化,以满足现代AI应用的需求。
MI350系列采用UBB8版型设计,每个节点配备8块GPU,通过153.6GB/s的Infinity Fabric双向链路实现高效通信。
在8卡配置下,MI355X系统提供2.3TB HBM3e内存和64TB/s内存带宽,FP4/FP6精度下峰值算力高达161PFLOPS。

在机架级部署中,MI350系列展现出强大的扩展能力。
风冷机架最多支持64块GPU,提供18TB HBM3e内存;直接液冷机架可容纳128块GPU,内存容量达36TB,FP4性能高达2.6E FLOPS。
这种超大规模的系统配置,使MI350系列能够轻松应对复杂AI工作负载,为企业级AI应用提供坚实支持。

苏妈还公布了其下一代AI芯片Instinct MI400系列的细节。
这款预计于2026年推出的芯片专为大规模AI训练和分布式推理设计,性能较前代MI355X提升高达10倍。

MI400系列在算力上实现了巨大突破。
在FP4精度下,其峰值算力高达40PFLOPS(每秒40千万亿次浮点运算),FP8精度下也能达到20PFLOPS的出色表现。
MI400系列搭载了432GB的HBM4内存,内存带宽达到惊人的19.6TB/s。
这种超高带宽的内存设计显著提升了数据处理效率,为复杂AI任务提供了强大的支持。
此外,每块GPU支持300GB/s的横向扩展带宽,通过Pensando NIC和超以太网技术实现跨机架和集群的高效互连,确保分布式计算环境下的无缝协作。

相比上一代MI355X,MI400系列通过引入HBM4内存、优化计算单元和增强互联技术,实现了性能10倍的飞跃。
此外,MI400系列在能效和扩展性上的优化,使其在应对多样化AI工作负载时更具灵活性。
无论是训练超大规模语言模型,还是进行分布式推理,MI400都能提供高效、稳定的计算支持。

在MI400系列的发布会上,OpenAI首席执行官Sam Altman亲自登台,对MI450型号给予高度评价。
他表示,OpenAI与AMD工程团队密切合作,深入探讨市场需求,助力MI400系列的开发。
预计2025年第三季度,ROCm 7将全面上线,支持MI350系列GPU。

亮点如下:
-
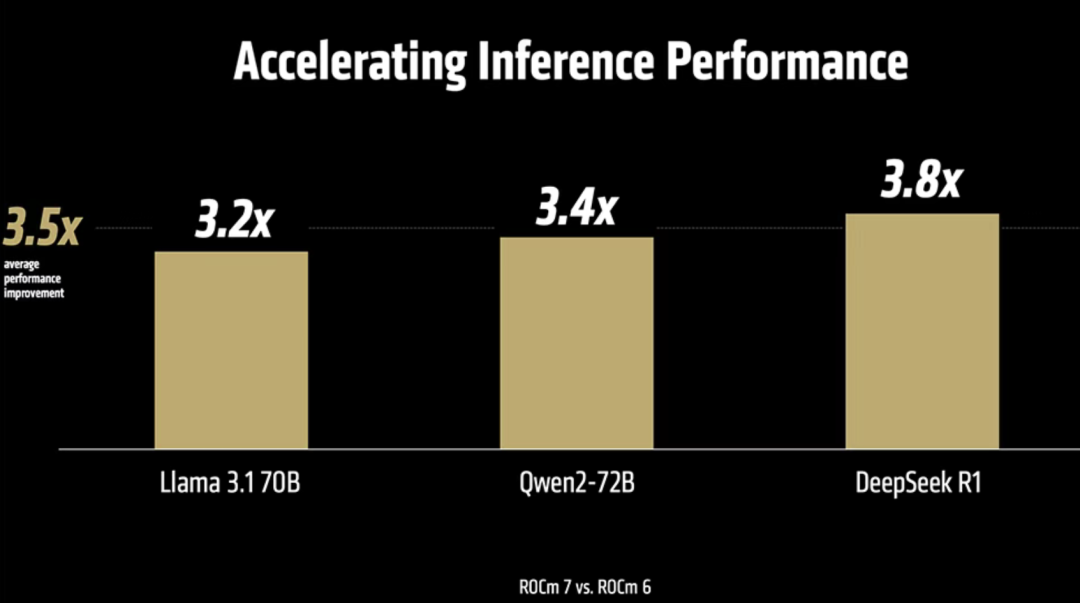
性能暴涨:相比ROCm 6,ROCm 7推理性能提升超3.5倍,训练性能提升3倍!这得益于对FP4、FP6等低精度数据类型的支持、通信栈优化以及更高的GPU利用率和数据移动效率。在Llama 3.1 70B、Qwen2-72B、DeepSeek R1等模型上,ROCm 7推理和训练性能比前代提升3.2~3.8倍。
-
分布式推理更强:ROCm 7引入强大的分布式推理方法,与SGLang、vLLM、llm-d等开源框架深度合作,开发共享接口和原语,实现在AMD平台上的高效分布式推理。相比之下,英伟达的TensorRT-LLM不支持DeepSeek R1的FP8精度,而AMD合作的开源框架完美支持,MI355X的推理吞吐量比英伟达B200高出30%。
-
企业级AI解决方案:ROCm企业级AI软件栈首次亮相,打造全栈MLOps平台,专为企业AI操作设计,提供安全、可扩展的交钥匙工具,支持模型微调、合规性、部署和集成。
-
端侧AI开发新体验:ROCm扩展到Ryzen笔记本电脑和工作站,支持AI辅助编码、自动化定制、推理和模型微调。
AMD通过开源战略和ROCm的持续创新,不仅在AI性能上大步向前,还为开发者、企业和用户带来了更开放、更高效的AI生态!
明年,AMD将推出下一代AI机架解决方案——Helios,集成更强悍的EPYC 「Venice」 CPU、MI400系列GPU和Pensando 「Vulcano」 NIC。

这套架构支持超以太网(Ultra Ethernet)实现横向扩展,结合UALink(Ultra Accelerator Link)实现纵向扩展,还配备Fabric Manager作为ROCm生命周期管理的一部分,助力基础设施自动化,省心又高效。
2026年,下一代Pensando 「Vulcano」 AI NIC将作为MI400系列的标配推出。
Vulcano采用3nm制程,提供800G网络吞吐量,每GPU横向扩展带宽是上一代的8倍,支持UAL和PCIe Gen6,带宽翻倍,可扩展至100万块GPU,且软件完全向前向后兼容。

AMD首次推出了开发者云,助力开发者轻松上手AI开发!
无需自购硬件或繁琐配置,只需一个Github账号或邮箱,就能即刻访问ROCm和AMD GPU。
这个全托管平台提供对MI300X GPU的即时访问,省去硬件投资和本地设置的麻烦。Docker容器已预装热门AI软件,节省安装时间,同时保留代码定制的灵活性。
计算选项灵活可扩展:
-
小型:1个MI300X GPU(192GB GPU内存)
-
大型:8个MI300X GPU(1536GB GPU内存)
首批注册的开发者可获25小时免费使用时长,通过ROCm Star开发者证书等计划,还能额外获得最多50小时的免费时间。
(文:新智元)