

第一作者是来自中南大学软件工程的本科生李光照,通讯作者为来自西湖大学 AGI 实验室的助理教授张驰。本文工作是李光照在西湖大学 AGI 实验室访问时完成。
视频的生成与编辑往往有着较高的门槛,新手往往会被视频工作中各种复杂的工作流劝退。随着人工智能技术的发展,AIGC 视频编辑简化了这种复杂的工作流程,只需在输入框里敲下一句自然语言,就能让原视频在几分钟内蜕变成全新画面。然而,当前的视频编辑方法通常采用非常复杂的策略来维持编辑前后无关的事物保持一致,这带来了很多不必要的开销,尤其是计算资源的消耗,且仍会对无关区域造成严重的干扰,同时也会抑制主体对象的编辑效果,使得产生用户难以接受的效果。
为解决上述困境,西湖大学 AGI Lab 团队提出了 FlowDirector:一种全新的无需训练的视频编辑框架。FlowDirector 在视频 “流匹配”(Flow Matching)范式下进行,可以将任意基于流的视频生成模型改造成有效的视频编辑工具,而无需任何的重新训练。相较于其他视频编辑方法,FlowDirector:
1. 质量更高:FlowDirector 可以进行更加彻底的对象编辑,允许产生大幅度形变。
2. 功能更加广泛:不仅仅支持编辑,更支持添加、删除、纹理替换转移等多种复杂的编辑功能
3. 开销更低:在编辑过程中,除所用基础生成模型带来的显存开销外,不会添加任何额外的显存占用,单卡 4090 就可实现高质量视频编辑。


-
论文标题:FlowDirector: Training-Free Flow Steering for Precise Text-to-Video Editing
-
论文链接:https://arxiv.org/abs/2506.05046
-
项目地址:https://flowdirector-edit.github.io
-
Github:https://github.com/Westlake-AGI-Lab/FlowDirector
-
Huggingface: https://huggingface.co/spaces/Westlake-AGI-Lab/FlowDirector
编辑结果视频:





研究背景与挑战
文本驱动的视频编辑近年进展迅猛,但现有的视频编辑方法都是基于反演的方法,即通过 DDIM Inversion 将用户所给的原始视频反演为对应的高斯噪声,再对此高斯噪声重新采样,在重采样过程中注入一定的条件 (如文本、图片) 等来实现视频编辑效果,但现有基于反演的技术方法普遍存在以下问题:
1. 时序不一致 —— 反演误差会打破帧间连贯,导致编辑的视频出现不一致现象;
2. 结构失真 —— 视频高维动态难以重建,背景容易 “漂移”;
3. 编辑幅度受限 —— 无法同时兼顾大幅度语义变换与细节保真。
FlowDirector 选择 “绕过” 错误较多的反演阶段,直接在数据域构造 ODE 演化路径,让原视频平滑过渡到目标语义,从而根本性缓解上述问题。
方法概述
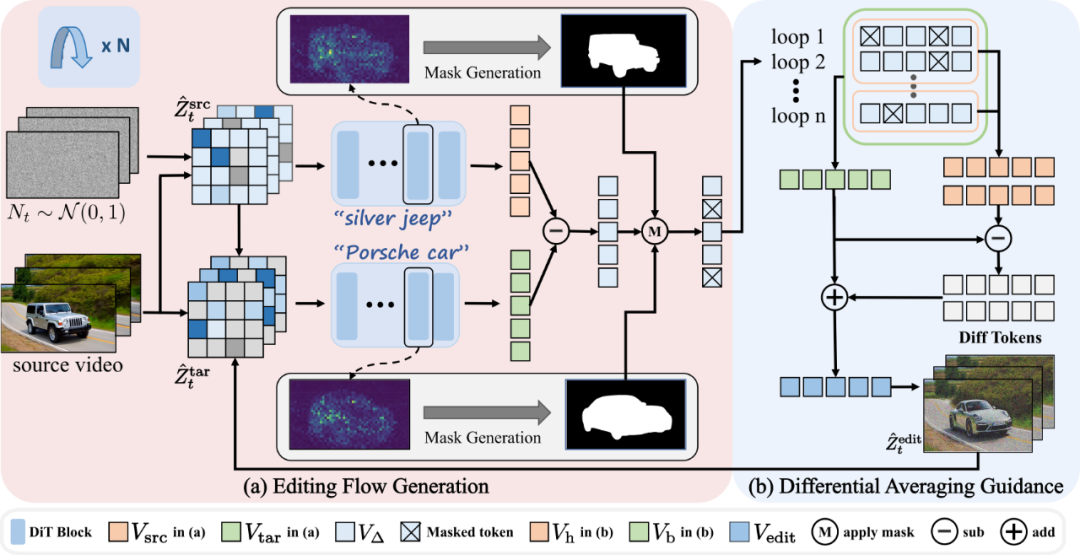
贡献一:直接流演化与空间矫正
FlowDirector 摒弃了传统先将视频映射到扩散模型潜在空间再编辑的繁琐流程,而是直接特征空间构建 “源视频→目标视频” 的演化路径。而这种直接演化路径产生的编辑流作用于全视频特征,会导致无关区域发生意外变化,严重影响编辑视频的保真度。为此,研究团队提出了空间感知流矫正 (Spatially Attentive Flow Correction, SAFC), SAFC 通过定位并限制编辑视频中关键对象所在的空间区域,来防止编辑流干扰无关区域。

具体措施为基于注意力热图生成二值掩码,仅在语义相关的区域(如要替换或修改的物体、人物)施加流演化,背景与非目标部分完全 “冻结”,保证编辑后视频的结构与纹理不受影响。
贡献二:差分平均引导:一种编辑流的自动引导优化方式
在无反演直接编辑的场景中,原始视频往往会对最终效果施加过强的 “控制信号”,导致修改后的视频中依然残留明显的原始物体轮廓或细节伪影。为此,作者团队提出了差分平均引导 (Differential Averaging Guidance, DAG),同时进行 “高质量采样” 和 “快速基线采样”,通过比对两者之间的差异来提炼出真正需要的编辑优化方向。
这样一来,系统不仅能保留足够的语义细节、确保目标区域与文本提示高度匹配,还能有效抑制原始视频多余信息的干扰。最终,DAG 让 FlowDirector 在保证高保真度的同时,不至于陷入冗长采样带来的算力瓶颈,实现了 “画质优先、效率优先” 的双重升级。核心思路如下:
1. 高质量采样与基线采样并行
在每一次扩散迭代中,首先对掩码校正后的差分速度场做多次高质量采样(例如 4 次),并将结果取平均得到一个精确且细节充足的速度估计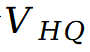 ;与此同时,用更少的采样次数(例如 2 次)生成一组基线速度
;与此同时,用更少的采样次数(例如 2 次)生成一组基线速度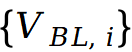 。
。
2. 算差分信号抑制原始残留
将每个基线速度与高质量速度相减,得到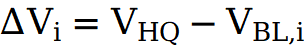 。这些差分信号准确指示了 “从原始视频到目标风格” 所需的增量变化方向,能够有效抑制原始帧中残留的强控制成分(即伪影)。
。这些差分信号准确指示了 “从原始视频到目标风格” 所需的增量变化方向,能够有效抑制原始帧中残留的强控制成分(即伪影)。
3. 融合微分指导生成最终速度
将所有差分信号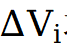 求平均得到
求平均得到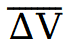 ,然后按一定权重与高质量速度
,然后按一定权重与高质量速度 进行线性融合:
进行线性融合:
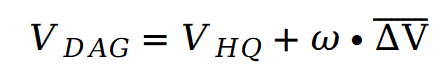
这个融合结果既保留了高质量采样带来的细节与语义对齐,又利用差分引导信号实现自动引导,进一步降低了原始视频残影的干扰。
实验亮点:不仅仅简单的 Replace,
支持任意添加、删除和替换视频中的对象或元素

FlowDirector 能够精准捕捉并反映提示中指定的关键风格属性(例如颜色、材质等),优先确保文本语义与视觉效果的高度对齐。同时,我们的方法在保证目标区域发生预期变化的前提下,也能确保输出视频的整体布局稳定与结构完整:无论是主体替换、属性修改,还是局部增删,背景纹理和时序连贯性都始终如一。

对比多种 SOTA 的视频编辑方法(如 FateZero、TokenFlow、VideoDirector 等),FlowDirector 在对象形变幅度、文本一致性、视觉细节与运动流畅度方面均表现突出,综合主观与客观评测指标均居领先水平。

在定量结果中,FlowDirector 在各种指标上均取得 SOTA(在 WarpSSIM 上并非最高,因为 FlowDirector 能够实现更大程度的语义变换,导致像素级的光流扭曲数值略低),超过了已有的视频编辑方法。
结语
FlowDirector 展示了视频编辑的新思路:无需反演的直接流编辑。我们期待这一框架在影视后期、短视频创作、AR/VR 内容生成等领域落地,并与社区共同探索更多可能。

©
(文:机器之心)