

前几天,纳米开了一场发布会,老周演示了「超级搜索智能体」
“2025 年新能源汽车补贴政策取消后,汽车行业格局预计会发生哪些变化?”
一段时间后,30页报告完成:带图、注释、引用

放在几年前,这是:「未来已来」
放在现在,这是:「Agent 默认感」
正是这种默认感,让我意识到
我们已经很久,没自己找过信息了
本文非教程,来聊:「搜索演化史」
目录系统
在今天,查资料不过是「搜一下」
在过去,查资料确是难如登天

想象一下,你回到上世纪初
如果找一份关于「辛亥革命」的材料
该怎么办?
你可能会想:
走进图书馆,跟管理员说:「清末革命,讲武昌起义那场」
想得美…找资料没那么简单
档案管理,资料浩如烟海,层层叠叠
正确的流程,是这样:
一、先去查卡片柜:这里一整柜小卡片,记录着书名、作者、主题、馆藏位置
二、再去找索引:「清末」-「民国初年」-「辛亥革命」
三、记录下编号和位置:2楼,3排,5号书架,6层,编号 114514
四、跑过去,看看在不在:如果被借走了,那就明儿再来
图书馆目录卡系统,是那个时代的「搜索引擎」:结构化、可查找,但完全依赖人工。

这东西,所有卡片都是人来维护,可用性,取决于执行者的专业性

这种方法,虽然效率低,但却是当时唯一能让知识「被找到」的方法
1918年,北大图书馆
有位图书管理员,在整理各种刊物《申报》《京报》《大公报》,还有英文日文刊物…
他熟悉报刊种类,清楚时效来源,知道如何摆放检索
他广泛阅读各种刊物,博闻强识,为广大师生提供服务
这个人是毛主席

文本检索
时间到了二战后
东西角力,科技爆发
知识、论文、报告爆炸增长
信息膨胀,人工整理跟不上了
还是查「辛亥革命」
不用翻抽屉了
而是通过计算机,输入类似:
"辛亥革命" AND "武昌起义" NOT "北洋军阀"(当然,这并不是 SQL)
这是早期的「机器搜索」
用逻辑表达式、布尔运算、关键词精确匹配来匹配信息,让机器成为信息的入口
进一步的突破,来自 Gerard Salton,现代搜索技术之父

他在 60 年代开发出了 SMART,真正的文本检索系统:
-
• 把每篇文档看成一串词语的集合 -
• 计算关键词的出现频率(TF)和稀有程度(IDF) -
• 用数学方法把文本转成”向量”,算出文档和查询的”距离”
换句话说
SMART 不是筛选匹配,而是寻找「哪篇最相近」
比如你搜「辛亥革命」,返回可能包括:清末史教科书、清政府财政困境论文、张之洞思想访谈
标题看上去可能没啥关系,但内容上相似度极高
现代的各类搜索引擎,其底层原理都可以追溯到 SMART
自此,信息不再是被存起来的档案,而是可以被算出来的资源

信息检索,也从人工经验变成了数学计算
网络搜索
最早的网上冲浪,没有搜索,纯靠翻阅。
门户网站是当时的主流,Yahoo 是当时的王者。国内也有所谓「三大门户」:网易、新浪、搜狐。
用户翻栏目、点频道,一层层进去
最开始还能维护,但内容一多就难办了:
更新不及时、分类不统一、死链泛滥
搜索引擎因此而生,最知名的便是谷歌:
你说关键词,获得相关的网页
搜索方法也很暴力:
关键词匹配,后面还加了 PageRank 等方法,让排序更加准确
真正的变化发生在 2010 年前后:搜索开始理解人话了
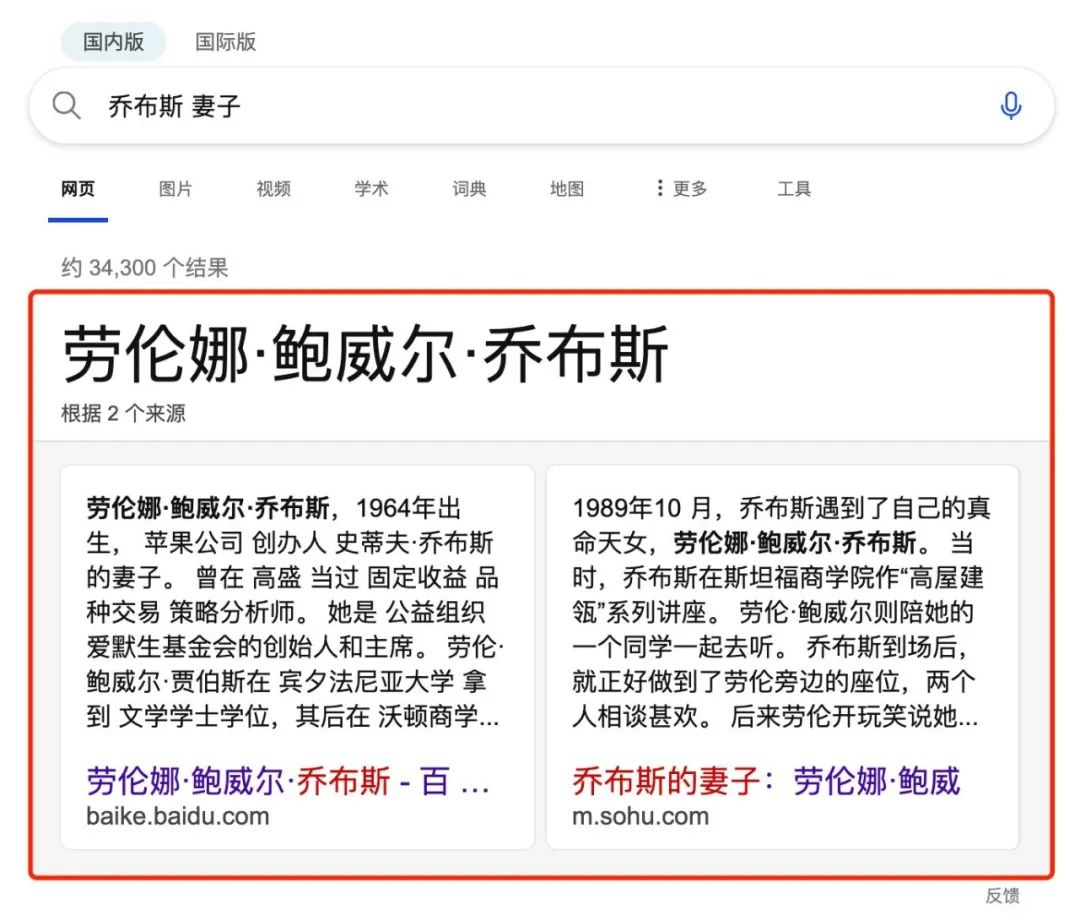
Google 上线了 Knowledge Graph,可以直接显示答案
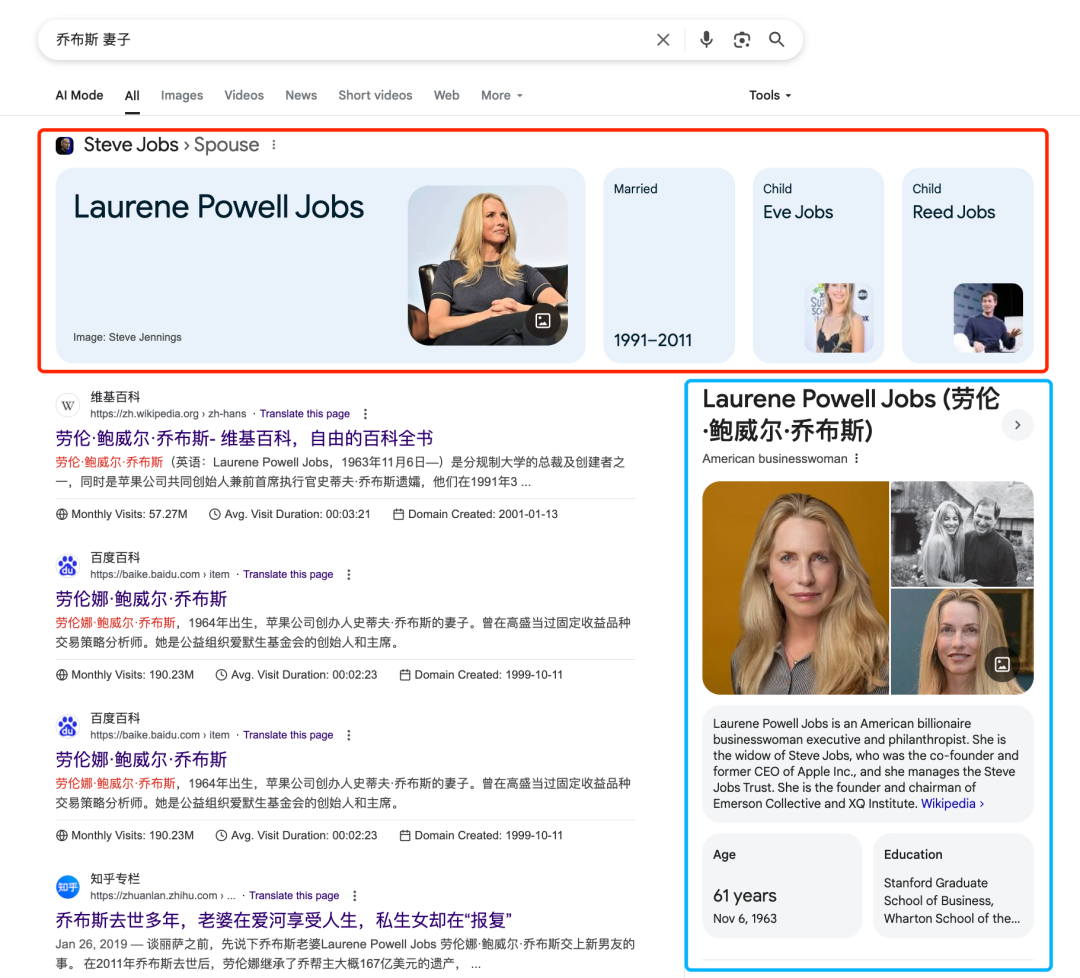
你搜“乔布斯 妻子”,它不光返回网页,还在顶部给出了”摘要”
微软的 Bing 也做了类似尝试,百度那时候也开始引入问答卡片
都在尝试告诉”你想知道的答案”
这一阶段也出现了不走寻常路的产品
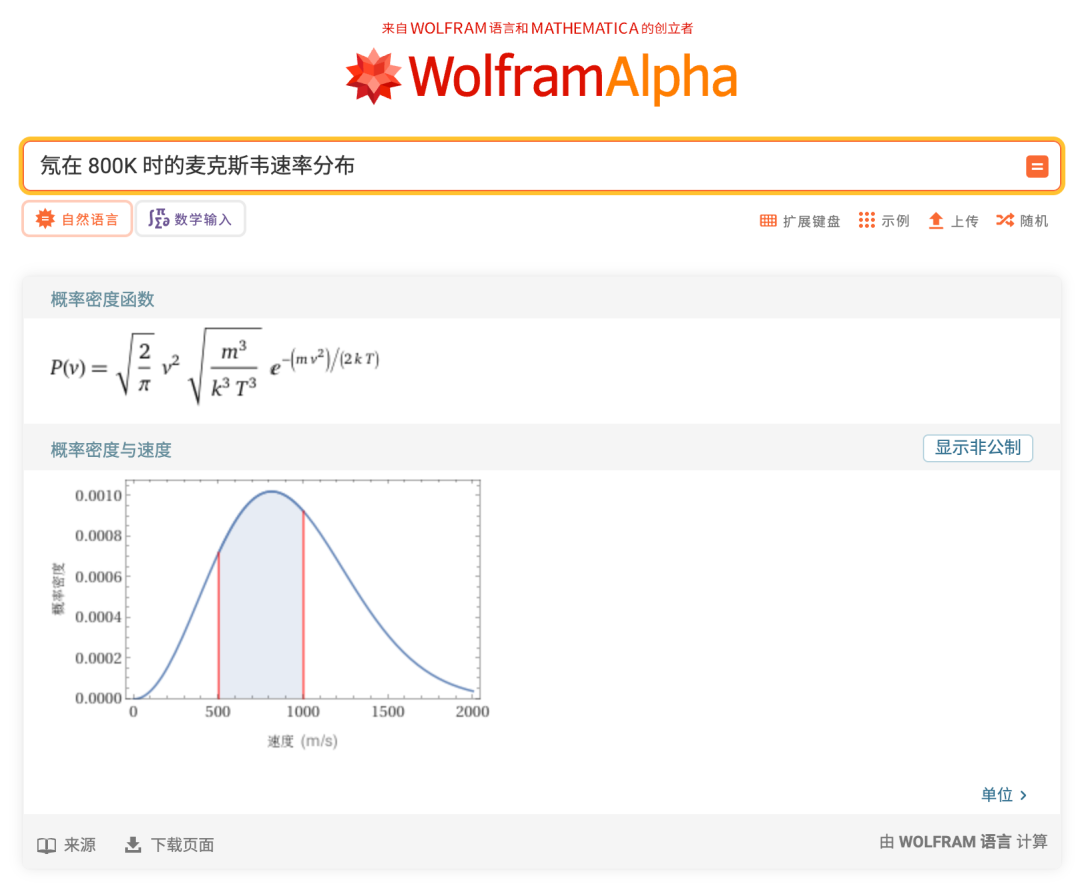
比如 Wolfram Alpha,它不是去找网页,而是从知识库里直接算。你问它”光速是多少”,它不会推荐百科,而是返回一个公式计算出来的结果
不是搜索,是推导
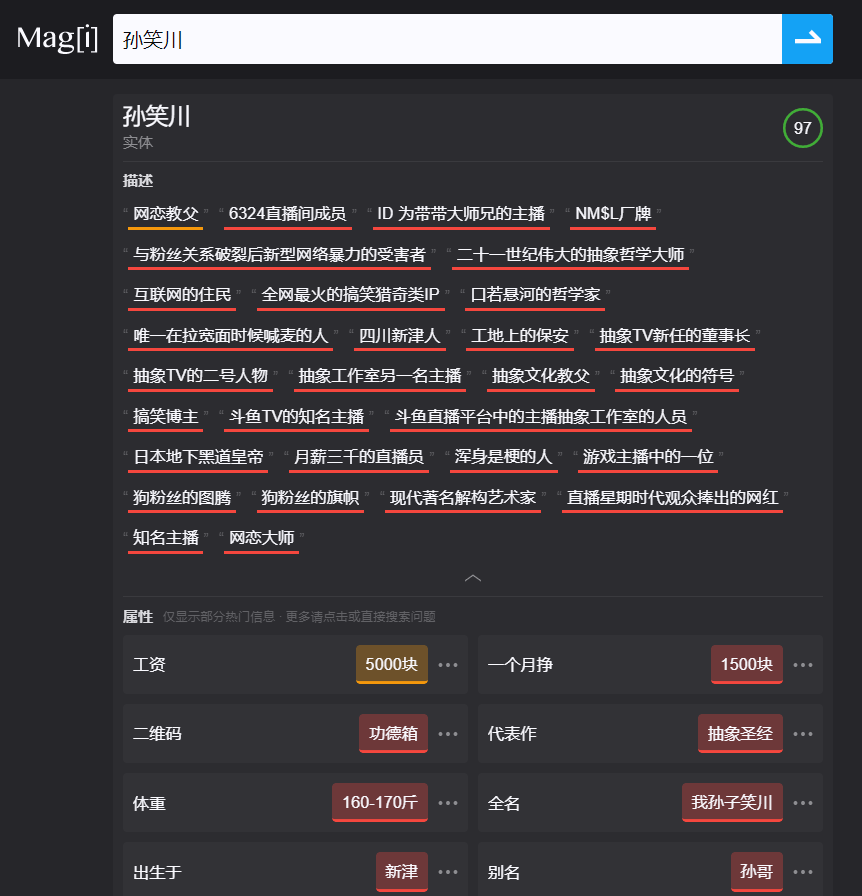
Manus 的联合创始人季逸超(Peak),之前做了个项目叫 Magi 并成功被收购,方法也是从网页中抽取结构化知识,并进行结构化展示
须知:每一代技术都有它的局限
门户能让你看到内容,搜索能让你找到内容,语义理解能提炼内容。
它们都还只是”告诉你”,还没有”替你去做”
AI 时代
2022年11月30日,ChatGPT上线。
几天后,朋友圈、知乎、即刻开始试着「让它写点什么」
写年终总结、写邮件模板、写开场白、写月报
语气自然、段落清楚,确实不错
人们开始问它各种问题
“光速是多少?”
“哥白尼是哪国人?”…
都答得上来,逻辑清晰,用词贴切
问题很快浮现:胡言乱语
“这些数据有出处吗?”
GPT 会开始自信地胡编乱造:打不开的网页,不存在的文献…

AI并不是查到了信息,而是基于训练数据生成了看似合理的答案。
为解决这个问题,AI被接入了搜索功能
方法相当粗暴:提取关键词、调用搜索API、获取网页片段、掺入对话正式生成
本质是在大模型的生成能力上,叠加了传统搜索的信息获取
虽然粗暴,这种叠加的效果确实不错
从检索到理解
真正的变化始于2023年中,AI搜索开始向智能体(Agent)方向演进:尝试进行任务规划。这里顺道说一下,任务规划这东西,有两种实现方式:直接做到模型中(比如 OpenAI 的 o1/o3…),或者通过外部工程化的方式,坐在产品里(比如 Manus)
如果说传统搜索是单次查询,智能体则会将复杂需求拆解成任务树,再加上点 React,最知名的当属「OpenAI DeepResearch」
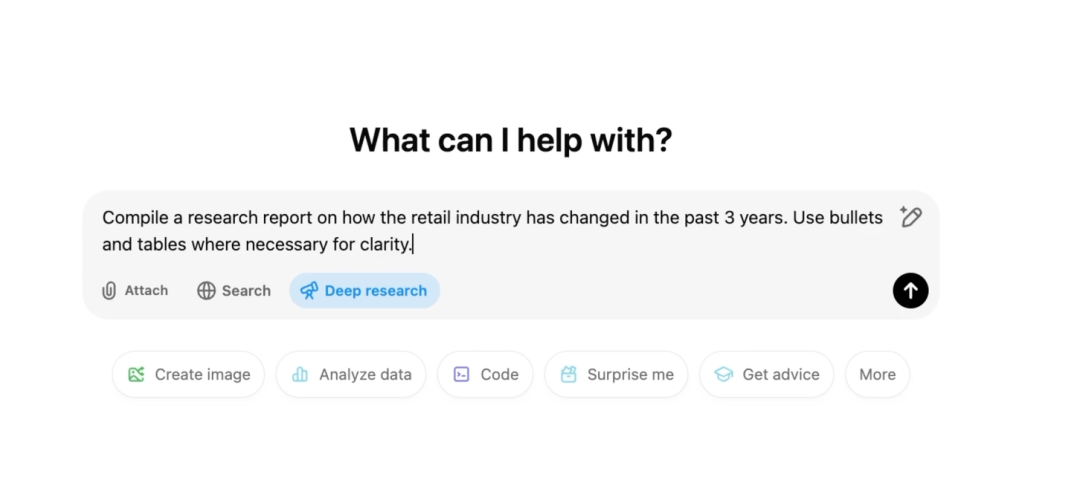
比如「分析新能源车市场」,会被拆解为:市场规模数据、主要厂商份额、技术路线对比、政策影响分析等多个子任务。
至于其它示例,以「纳米 AI 超级搜索智能体」为例
每个子任务不是孤立的,而是相互关联,甚至是能回退&重新规划的
当发现「2024年销量数据」存在多个版本时,系统会启动新的验证任务:
查找官方统计口径、对比不同数据源、分析差异原因
循环推理机制,让搜索有了初步的思考能力
它不再是机械地返回结果,而是会判断信息的完整性、可信度,以及是否需要进一步挖掘。
跨越信息孤岛
网络上的信息,是一个个孤岛
学术论文在专业数据库,用户评价在电商平台,真实反馈在社交媒体,专业讨论在垂直论坛

新一代搜索通过两种方式打破围墙:
一方面是数据突破:通过浏览器自动化、API集成、内容解析等技术,实现对不同平台的统一访问。系统能够理解网页结构、提取关键信息、处理动态内容。
一方面是语义理解:不同平台的信息表达方式差异很大——论文的严谨表述、社交媒体的口语化、电商评论的情绪化。AI需要理解这些差异,提取真正有价值的信息。
比如查询一个医疗问题,系统会综合:专业论文的研究结论、医生社区的临床经验、患者论坛的真实案例、药监部门的官方信息。不同来源相互印证,形成更全面的认知。
从信息到执行
搜索的演进不止于找到信息,更重要的是完成任务
这需要三个层次的能力:
理解层,准确理解用户意图:「帮我做个PPT」背后,可能是要做项目汇报、产品介绍或者是数据分析。不同场景需要不同的处理逻辑。
规划层,将意图转化为可执行的步骤:制作PPT需要:确定框架、收集素材、整理数据、设计版式、生成内容。每一步都可能需要不同的工具和数据源。
执行层:调用具体工具完成任务:这包括文档生成、数据可视化、图像处理等。关键是这些工具的调用是自动的、连贯的,用户无需逐步操作。
你会发现,思考的整个过程是透明的:用户能看到系统的推理过程、数据来源、执行步骤。这种透明性既保证了可控性,也便于用户理解和调整。
尾声
回到开头那个「默认感」
-
• 以前,我们默认要自己找 -
• 现在,我们默认有人帮我们做
从图书馆的卡片、到AI的理解
一百年来,我们都在回答一个问题:
怎么能最少动一下,就让知识为我所用、为我所动
这个门槛,每一代都会变得更低
现在的我们,不再说“拨号上网”、不再说“翻电话本”
或许未来的人们,也不会再说“搜一下”
他们会说什么?或许什么都不说
最好的技术,是看不见的技术
(文:赛博禅心)