



领域增量学习(Domain Incremental Learning, DIL)要求模型在动态数据流中持续适应新领域(如风格变化、环境扰动),同时保留历史知识。传统 DIL 方法面临两难困境:一方面,重放历史数据存在隐私风险;另一方面,正则化约束又抑制了模型对新知识的充分学习。
近年来,基于提示(Prompt)的技术虽通过学习和存储领域专用提示缓解遗忘,并且发现在测试阶段融合不同域的提示可提高模型的泛化性能。但是提示内部的语义知识错位容易导致跨域提示融合时产生冲突,导致模型性能受限。
为了克服上述问题,北京大学王选计算机研究所团队提出提示知识对齐框架 KA-Prompt,通过加强域间提示的语义知识对齐,一方面增强了历史域知识对新域学习的指导作用,另一方面也加强了域间提示的语义一致性,提升了模型在测试阶段的泛化能力。
为了推动 DIL 领域研究的进步,KA-Prompt 已在 Github 开源,相关论文也已被 AI 顶会 ICML 2025 接收。

论文标题:
Componential Prompt-Knowledge Alignment for Domain Incremental Learning
论文地址:
https://arxiv.org/abs/2505.04575
开源地址:
https://github.com/zhoujiahuan1991/ICML2025-KA-Prompt

在传统的机器学习中,模型通常在固定的数据集上进行训练和测试,缺乏对新环境的适应能力。而在实际应用中,数据分布往往是动态变化的,模型需要不断地学习新知识,同时保持对旧知识的记忆。这就是持续学习的核心目标。
领域增量学习作为持续学习的一个重要分支,要求模型能够在不同领域的数据流中持续学习。然而,随着新领域的加入,模型容易出现“灾难性遗忘”(Catastrophic Forgetting),即新知识的学习导致旧知识的丢失。
此外,不同领域之间的知识差异也会引发“知识冲突”,使得模型难以有效巩固多领域的知识。
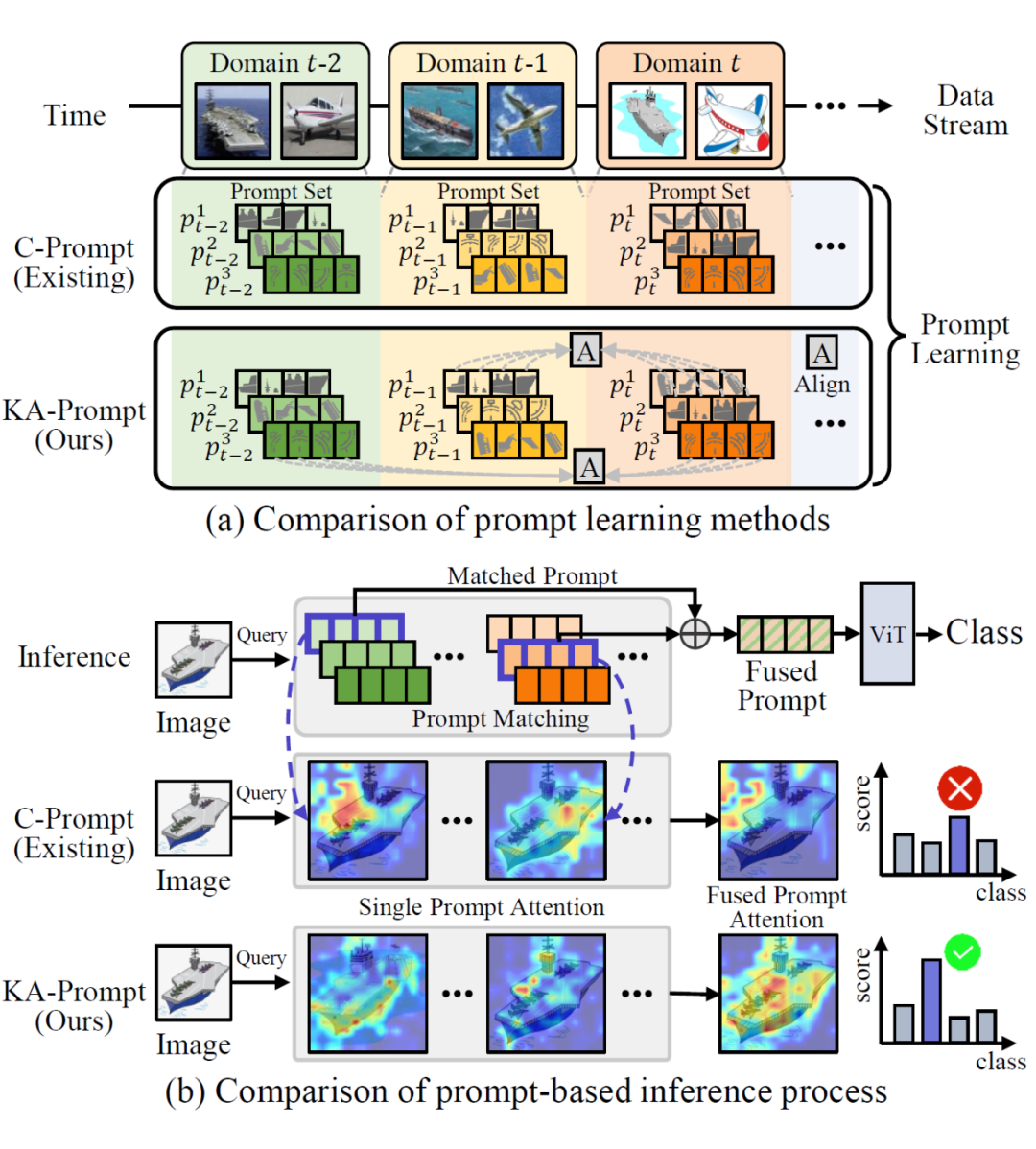
近年来,提示学习(Prompt Learning)作为一种新兴的学习范式,受到广泛关注。通过在预训练模型中引入提示,模型可以更好地适应下游任务,在域增量学习、类增量学习等任务中均取得了领先的性能。
最新的域增量学习方法 C-Prompt 发现,通过融合不同域提示进行推理,可以提升模型测试性能。这是因为处于域分布边界的样本往往与多个域存在关联特征,通过融合与样本相关性高的跨域提示,可以提升模型的泛化能力。
然而,现有的提示学习方法往往对每个域的提示独立训练,忽视了不同领域提示之间的语义结构关联。
提示参数是领域知识的主要载体,目标知识可以被划分为多个语义部分,并存储在提示参数的各个组成部分中。
由于语义部分在提示参数内的初始化位置是随机的,导致不同领域的提示在融合时出现“语义错位”,即相同位置的提示参数组成部分可能代表不同的语义信息。这种错位会引发知识冲突,降低模型的性能。
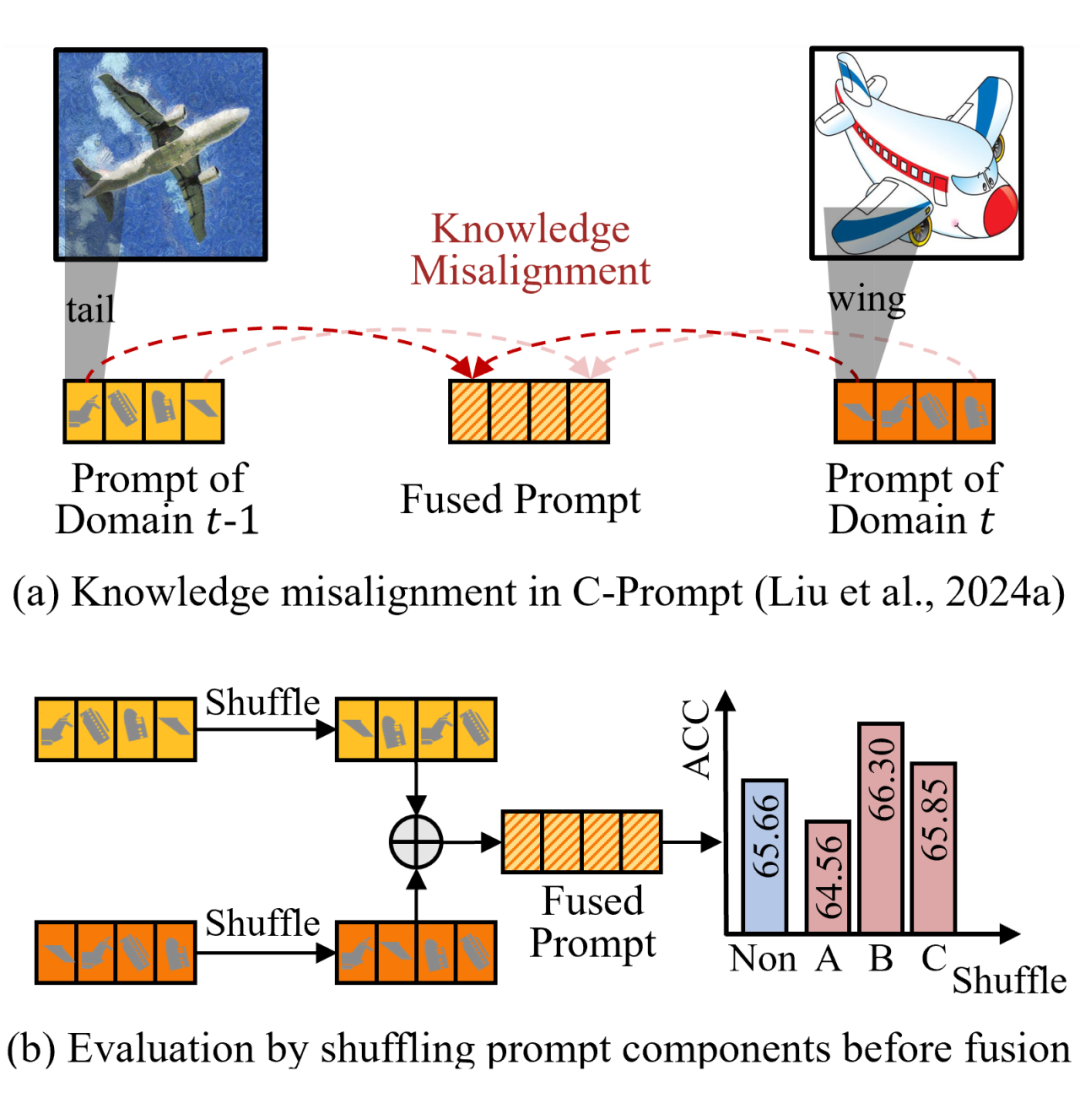
那么“语义错位”现象是否真的存在,又是否对模型推理具有影响呢?作者通过一个简单实验验证了这个问题。他们在 SOTA DIL 方法 C-Prompt 的推理阶段,对提示的组成部分顺序进行随机打乱,观察融合后的性能变化。
实验结果显示,某些打乱顺序的组合反而比原始顺序更优,说明原始训练时形成的语义结构是“次优的”,存在的错配现象。这一发现表明现有提示训练策略没有充分考虑结构对齐的重要性,也为 KA-Prompt 中引入提示知识对齐机制提供了实验依据。

为了解决以上的问题,作者提出一个KA-Prompt(Componential Prompt-Knowledge Alignment)提示学习框架,其核心目标是在跨域持续学习中,实现提示的语义结构对齐,同时促进历史域知识对新域学习的指导和提升模型在测试阶段的泛化能力。它包含两个核心阶段:
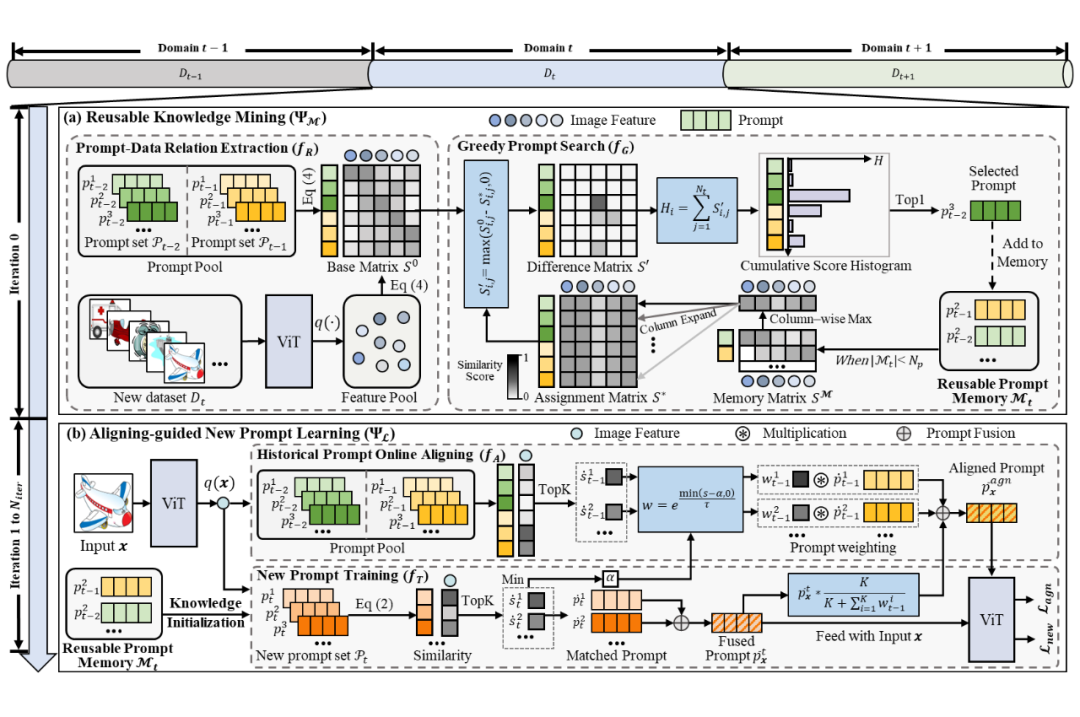
1. 可复用知识挖掘(Reusable Knowledge Mining)
面对新领域数据,KA-Prompt 不再随机初始化提示,而是从所有历史提示池中选取出一组与新域共享知识最大化的提示。这些提示参与构成“可复用提示存储器”,用于初始化新域提示。
该设计可以最大程度挖掘旧域中已学习的新域共享知识,指导新域高效学习,并且直接保证新旧域提示之间的语义结构一致性。
这一策略依赖于两个子模块:
提示-数据关系提取:度量历史提示与新域样本之间的相关性,获得基础矩阵 :
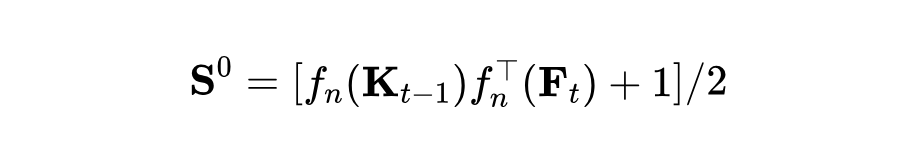
共享提示贪心搜索:循环搜索构建可复用提示存储器 ,在每次迭代中,首先将已存储的历史知识转化成相关性分配矩阵 ,将基础矩阵与相关性分配矩阵计算差分后得到 ,进而获得每个提示的累计相关性分数直方图 。
将 中 Top-1 值对应的提示加入到 中,循环进行该过程直至 容量达到新域中提示的数量。

2. 在线对齐引导的新域提示学习
虽然新域提示被初始化为与旧域提示相同的结构,但在训练过程中仍可能出现“结构漂移”。为此,KA-Prompt 引入一个在线对齐约束机制。
每次训练时,首先基于输入图像匹配多个新域提示并记录最低匹配分数 ,将匹配提示计算均值得到新域组合提示 , 和输入图像一起经过预训练网络得到类别预测并计算分类损失,记为新域提示学习损失 。
另外,输入图像从历史提示池中匹配一组旧域提示,根据每个旧域提示的匹配分数 ,提示权重:
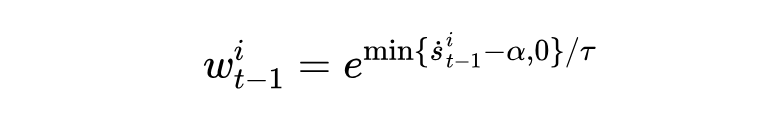
然后,将新域组合提示与历史提示进行加权融合,得到对齐提示:
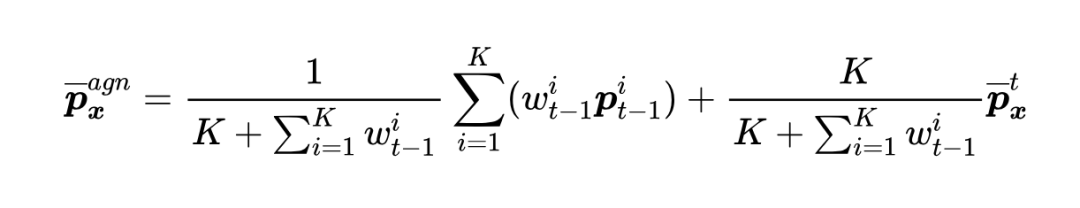
其中,K 为匹配的提示数量。 和输入图像一起经过预训练网络得到类别预测并计算分类损失,记为对齐损失 。
网络的总体损失为 ,其中, 约束新旧域提示保持语义结构一致性。
上述两个阶段结合,使得 KA-Prompt 不仅在提示初始化阶段实现知识复用,更在训练过程中实现提示结构持续对齐,确保跨域融合的兼容性。


作者在四个主流 DIL 基准上对 KA-Prompt 进行了系统性评估,分别是:
-
DomainNet(六类风格域,345 类图像,风格变化大)
-
ImageNet-R(15 类图像风格域)
-
ImageNet-C(15 种图像质量域)
-
ImageNet-Mix(融合 ImageNet-R 的风格和 ImageNet-C 的图像质量扰动,共 30 个域)

从结果来看,与现有方法相比,KA-Prompt 不仅在样本风格变化大(如 DomainNet)、图像质量劣化严重(如 ImageNet-C)场景下取得稳定的性能提升,而且在综合性最强的 ImageNet-Mix 上依然取得超过 5% 的绝对提升,充分体现出其跨域提示对齐机制在多种复杂数据分布下的适应能力和有效性。
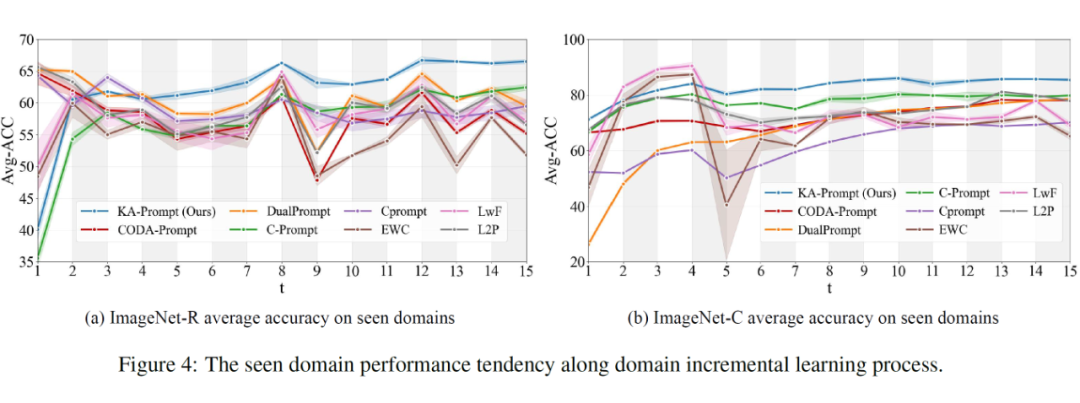
除了最终模型分类准确率指标,KA-Prompt 还通过动态性能曲线呈现了模型在持续学习过程中的性能变化,以观察不同方法在多阶段学习中对已学知识的巩固能力。可以看出,与现有方法相比,KA-Prompt 在第 5 个域后保持明显的性能优势。

本次被 ICML 2025 接收的 KA-Prompt 工作,聚焦于领域增量学习中一个被忽视但极其关键的问题,提示语义错位,并针对该问题提出了一种结构对齐的新范式。
通过在提示初始化与训练阶段引入语义结构对齐机制,KA-Prompt 有效解决了多域提示融合冲突的问题和旧域知识难以指导新域学习的问题,并在多个测试基准上取得了领先的性能。
(文:PaperWeekly)