
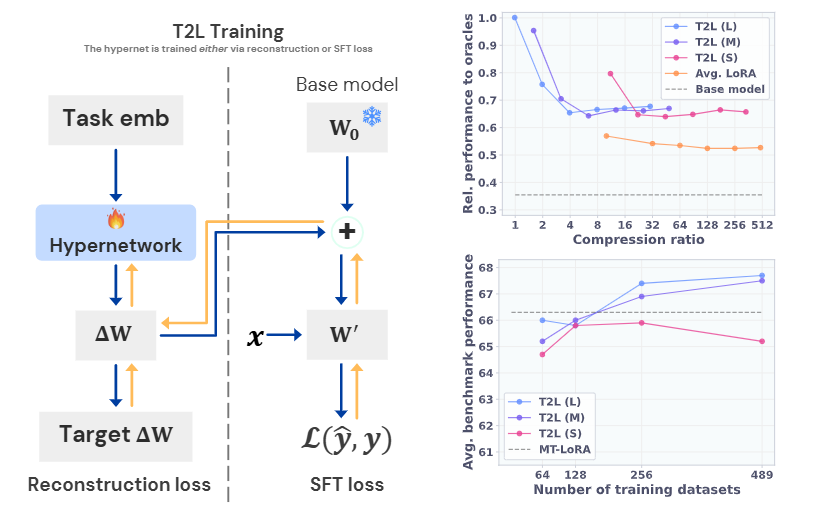
Text-to-LoRA (T2L) 框架概述,展示了通过重建或监督微调 (SFT) 损失进行的训练过程,以及在不同压缩比和训练数据集大小下的性能分析。
Text-to-LoRA (T2L) 通过允许基于自然语言指令对 Transformer 模型进行即时、动态适配,引入了范式转变。T2L 不再需要维护预训练适配器库或进行特定任务的微调,而是完全基于对所需任务的文本描述动态生成适当的 LoRA 适配器。这种基于超网络的方法有望通过以最小的计算要求提供强大的定制功能来普及 LLM 专门化。
核心架构与设计
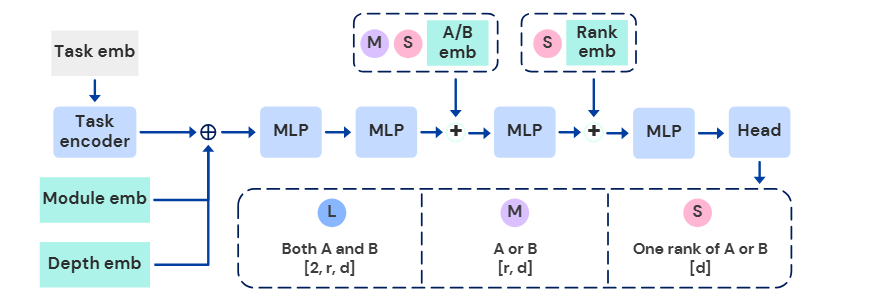
Text-to-LoRA 框架围绕一个超网络构建,该超网络将自然语言任务描述映射到 LoRA 适配器参数。该系统将组合了三个关键组件的连接表示作为输入:任务描述的向量表示、目标模块类型的可学习嵌入以及层索引的可学习嵌入。
-
T2L-L(大):直接同时输出 A和 B矩阵,需要最大的输出头部,其缩放比例为 2×r×d。 -
T2L-M(中):对 A或 B矩阵使用共享输出层,并使用专用嵌入来区分它们,其缩放比例为 r×d。 -
T2L-S(小):一次生成一个低秩矩阵的秩,具有最强的归纳偏置,其缩放比例为 d,并需要额外的特定秩嵌入。
训练方法
T2L 采用两种不同的训练方法,每种方法在不同的部署场景中都具有独特的优势。
LoRA 重建训练 代表了更直接的方法,其中 T2L 学习重建预训练 LoRA 适配器库。目标是最小化生成 LoRA 权重与目标 LoRA 权重之间的 L1 距离:
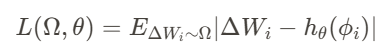
此方法利用现有 LoRA 库及其相关的任务描述,使其适用于已经存在此类库的场景。
监督微调 (SFT) 训练采取了一种更具抱负的端到端方法,直接根据下游任务性能优化 T2L。与重建现有适配器不同,此方法优化超网络以生成最大化基础 LLM 在实际微调数据集上性能的适配器:
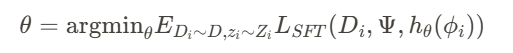
这种方法允许 T2L 学习隐式任务聚类并生成更有效的适配器,而不会受到潜在次优预训练 LoRA 的限制。
实验结果与性能分析
实验评估表明 T2L 在多个维度上都表现出有效性,从 LoRA 压缩到对未见任务的零样本泛化。
训练误差与性能之间的关系,显示了 T2L 即使在显著压缩伪影下也能保持可观的性能。

LoRA 压缩能力:当通过重建在 9 个基准特定 LoRA 上进行训练时,T2L 成功恢复了所有架构变体中 Oracle 任务特定适配器的全部性能。值得注意的是,T2L 在多个基准上通常优于原始适配器,作者将此归因于有损压缩的正则化效应,防止了过拟合。
零样本泛化:SFT 训练的 T2L 最重要的发现是它能够为完全未见的任务生成有效的适配器。在评估 10 个涵盖推理、数学、科学和编码的 Diverse 基准时,SFT 训练的 T2L 始终优于包括多任务 LoRA 适配器和最先进的零样本路由方法(如 Arrow Routing 和 Hyperdecoders)在内的强大基线。
结果表明,T2L 在真正的零样本设置下,弥补了与 Oracle 任务特定 LoRA 之间的大部分性能差距。在 PIQA 和 Winogrande 等基准上,T2L 甚至超越了 Oracle 适配器,展示了其生成更优任务特定修改的潜力。
跨模型泛化:T2L 的有效性不仅限于主要的 Mistral-7B-Instruct 基础模型,它在 Llama-3.1-8B-Instruct 和 Gemma-2-2B-Instruct 上也显示出可比的性能改进。这种跨模型的一致性表明 T2L 学习的是任务特定适应的可迁移原则,而非模型特定的伪影。
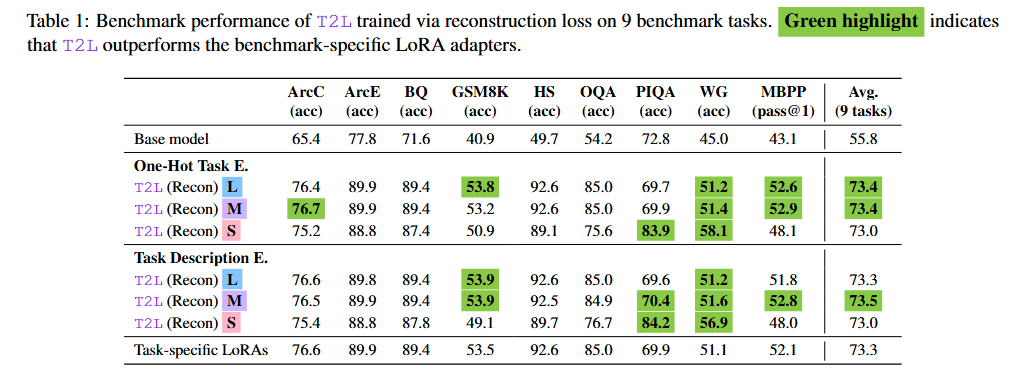
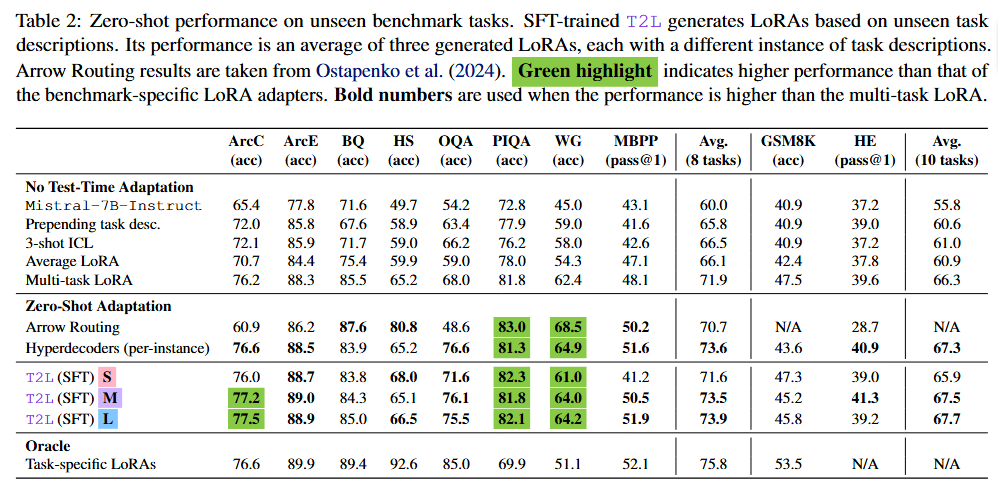
任务理解与语义聚类
T2L 功能的一个重要方面在于它能够学习任务及其相应适应的有意义表示。作者通过可视化和相关性分析提供了 T2L 发展出任务关系语义理解的证据。
定性示例,展示了同一问题的不同任务描述如何导致生成响应中截然不同的推理方法和呈现风格。

https://arxiv.org/abs/2506.06105https://github.com/SakanaAI/Text-to-LoraText-to-LoRA: Instant Transformer Adaption
(文:PaperAgent)