

VLOG Lab 投稿
量子位 | 公众号 QbitAI
还在靠“开盲盒”选择大模型?
来自弗吉尼亚理工大学的研究人员推出了个选型框架LensLLM——
大幅提升选型效果的同时,成本却降低近90%。

众所周知,在大模型如雨后春笋般爆发的时代,选型成了AI工程师和研究员最大的痛点之一:
-
模型多如牛毛,怎么选才不会“踩坑”? -
微调代价高昂,怎么预测谁能表现最优? -
资源受限,怎么才能用最少成本跑出最优解?
而使用LensLLM框架,不仅可以预测微调后的性能走势,还通过全新理论解释了大模型微调中一直难以理解的“玄学现象”。
按照团队的说法,LensLLM=用理论看清大模型未来+用极小代价选出最优解。
该研究被ICML 2025收录。
下面具体来看。
首度揭示:LLM微调中的“相变”动力学
近几年,大语言模型(LLM)从学术走向产业,从GPT到LLaMA,再到Mistral、DeepSeek,光是名字就让人眼花缭乱。
但选错模型不仅会浪费GPU资源,更可能拖慢产品迭代速度,甚至导致项目失败。
现有方法依赖经验、调参和“玄学”,在成本和效果之间很难找到平衡。
而LensLLM正是在这个背景下诞生,其目标是终结LLM选型“靠感觉”的时代。
展开来说,LensLLM的理论基础来自一项全新的PAC-Bayes泛化界限推导,首次从数学上揭示了LLM在不同数据规模下微调表现的非线性变化规律,具体表现为:
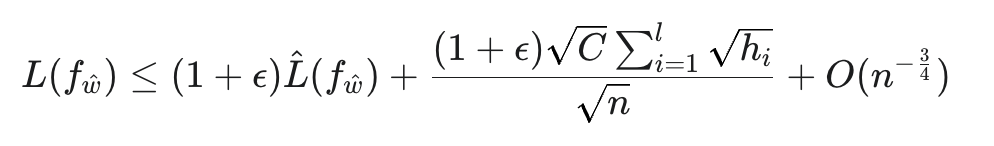
其中,n是训练样本量,ℎ𝑖与模型参数的Hessian矩阵(衡量损失函数曲率和参数敏感性)紧密相关。
在此基础上,研究团队进一步推导出推论1,将泛化界限简化为:
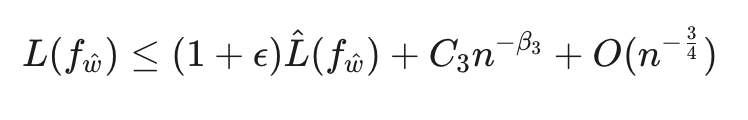
其中C3和𝛽3都是模型/任务相关的参数。
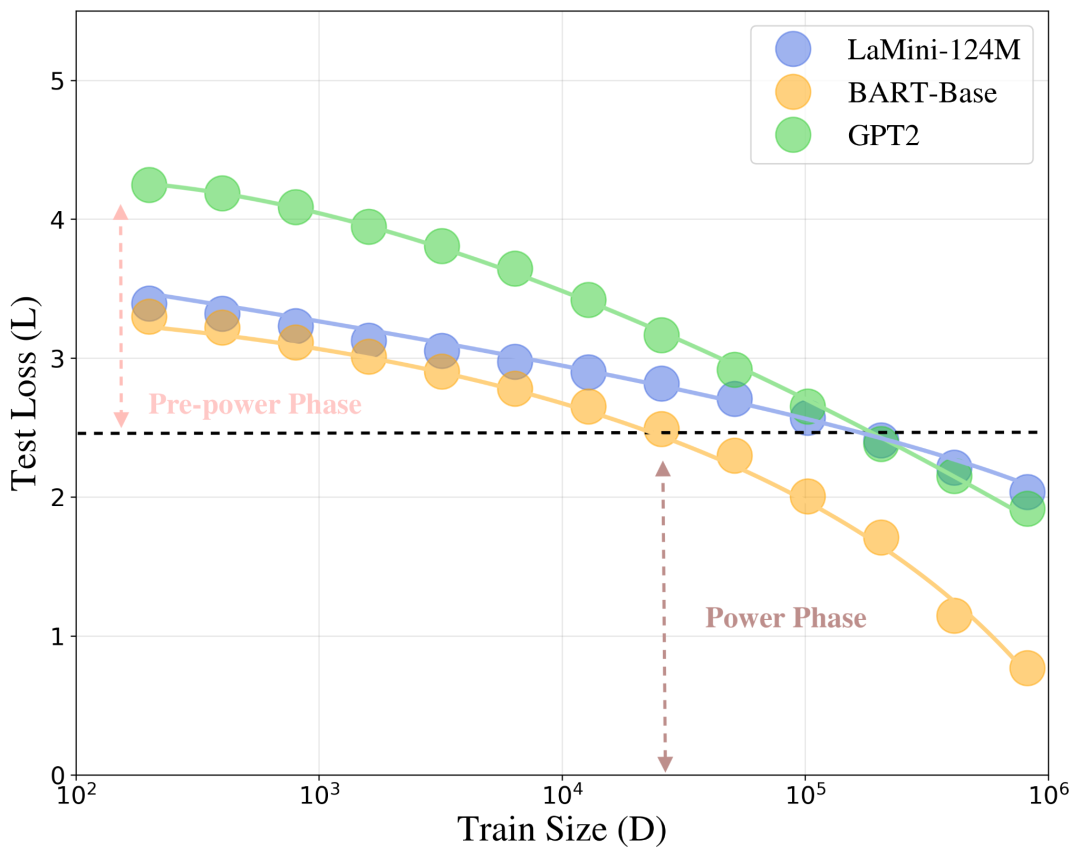
“预幂律相”→“幂律相”的相变现象
在数据量较小时,模型处于“预幂律相”,此阶段参数对损失非常敏感,表现极不稳定,性能提升有限;而当训练数据量超过某个临界点后,模型进入“幂律相”,此时误差收敛明显,调参也更有效率。
这一“从不确定到稳定”的过渡,首次在理论上得到了严谨解释,并被写进了LensLLM的预测逻辑中。
下图反映了LLM微调过程中测试损失L随训练数据量D变化的相变现象。低数据量阶段为预幂律相,高数据量阶段为幂律相,两者之间存在明显的转折点。
实锤LensLLM:用NTK模拟微调,用极小代价选出最优模型
理论解释只是开始。更重要的是——LensLLM还能算准。
研究团队构建了一个基于神经切线核(NTK)增强的缩放律模型,能够在只微调极少量数据的前提下:
-
精确拟合整个微调曲线(如图2和表2所示) -
预测最终测试性能 -
排出最优模型排名
下图2显示了,LensLLM(蓝色方块)在FLAN、Wikitext和Gigaword数据集上对OPT-1.3b、GPT-2和T5-base模型性能的曲线拟合效果。
可以看到,LensLLM的RMSE值显著低于Rectified Scaling Law(红色三角形),误差带更窄,表明其预测更稳定准确。
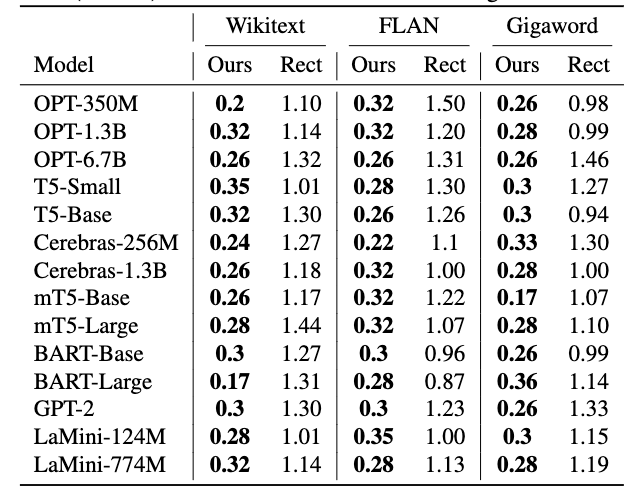
下表2为预测测试损失与实际测试损失方面的均方根误差(RMSE)对比(×)。
不需要完整训练,不需要大规模试错,就像提前“看穿”一个模型的未来走向。
在FLAN、Wikitext、Gigaword三大数据集上,LensLLM预测准确度远超基线方法(如Rectified Scaling Law),RMSE误差最小可低至原来的1/5。
下图3为LensLLM在FLAN、Wikitext和Gigaword数据集上的Pearson相关系数和相对准确率表现。
LensLLM(最右侧深蓝色条形)在所有数据集上均显著优于Rectified Scaling Law、NLPmetrics、SubTuning、ZeroShot和ModelSize等基线方法,展现了其在模型选型中的卓越能力。
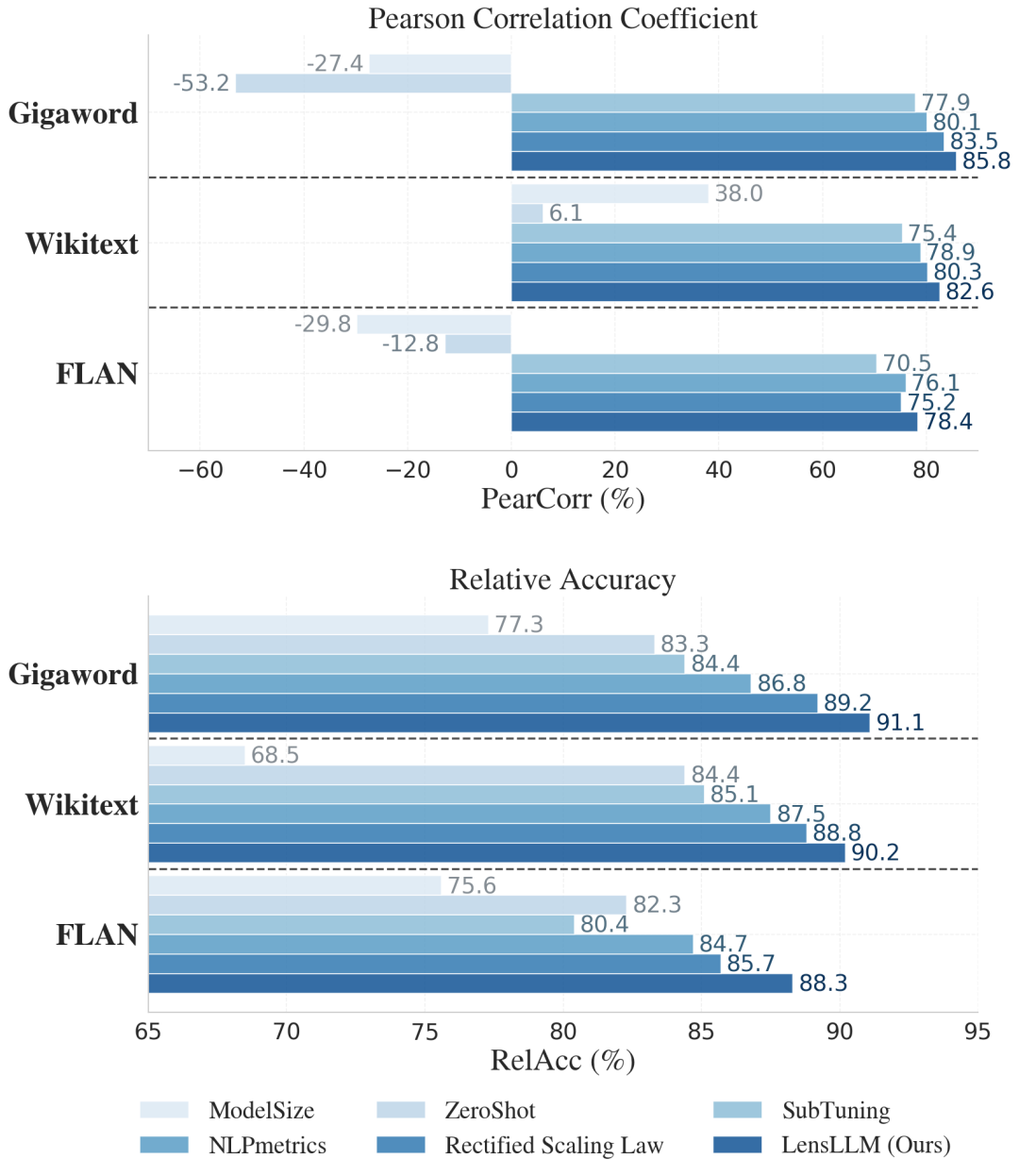
大幅提升选型效果,成本却降低近90%
选得准是一方面,选得快也是关键。
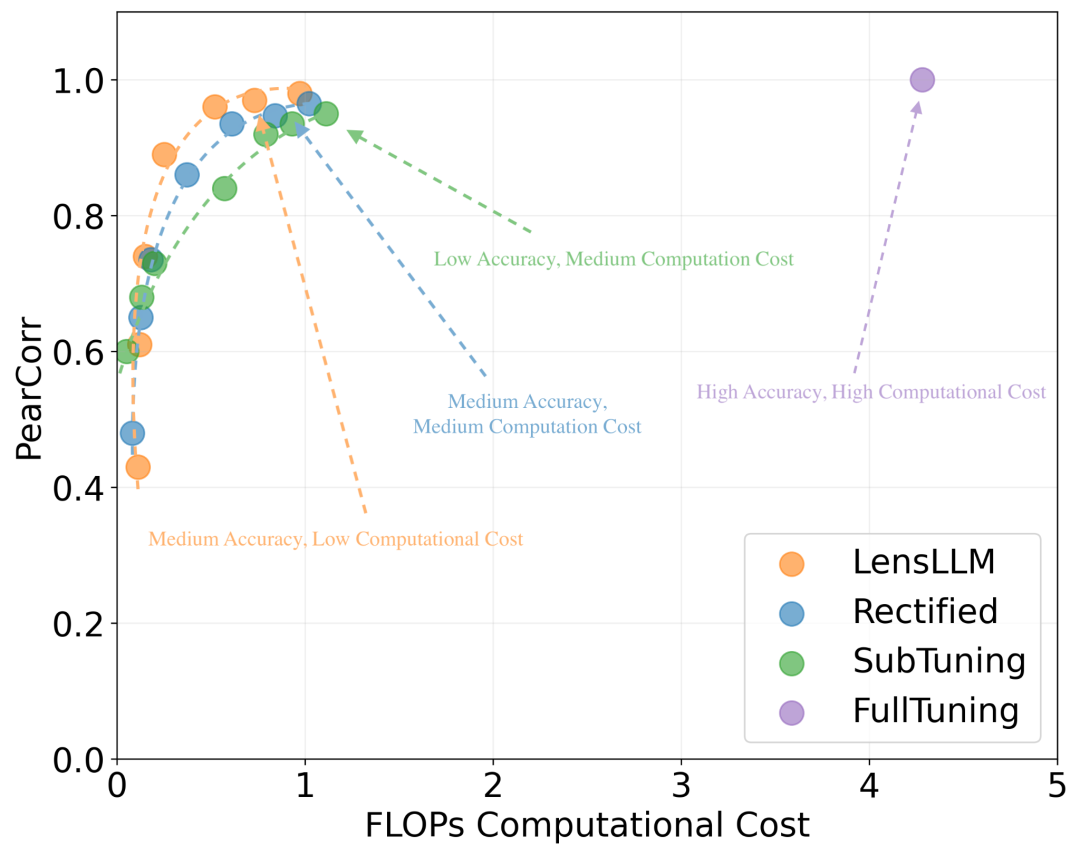
LensLLM引入了渐进式采样机制,计算成本比FullTuning方法最多降低88.5%,且在模型排名任务中保持高达91.1%的选型准确率,真正实现成本低、精度高、泛化强。
图4显示了LLM选型性能与计算成本的Pareto-最优曲线。LensLLM(橙色点)在显著降低FLOPs(计算成本)的同时,保持了高水平的Pearson相关系数,相较于Rectified(蓝色点)、SubTuning(绿色点)和FullTuning(紫色点)展现出更优的效率。
就是说,在选型性能与计算代价之间,LensLLM达到显著的Pareto最优。
未来场景:边缘部署/模型迭代/个性化推荐
团队表示,LensLLM不只是选型利器,更有潜力成为模型评估与管理的核心组件:
-
资源受限部署场景:帮助边缘设备快速选出兼顾精度与效率的模型; -
A/B测试与快速迭代:缩短新模型上线周期,节省GPU试错成本; -
定制化微调:根据用户任务和数据量,找到最合适的预训练模型,从而达到最佳效果。
未来他们将探索将LensLLM拓展到多任务环境与MoE等复杂模型结构,构建更通用的智能模型选型系统。
论文:https://arxiv.org/pdf/2505.03793
开源地址:https://github.com/Susan571/LENSLLM
作者联系方式:xyzeng@vt.edu, zhoud@vt.edu
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)