

FVDM & Pusa 一作:刘耀芳目前在香港城市大学攻读博士学位,导师为著名数学家 Prof. Raymond Chan (陈汉夫) 及 Prof. MOREL Jean-Michel。他也曾在腾讯 AI Lab 实习,主导 / 参与 EvalCrafter , VideoCrafter 等工作,其研究兴趣包括扩散模型,视频生成等;项目主管:刘睿,香港中文大学 MMLab 博士,华为香港研究所小艺团队技术负责人。
扩散模型为图像合成带来了革命,其向视频领域的延伸虽潜力巨大,却长期受困于传统标量时间步对复杂时序动态的束缚。我们去年提出的帧感知视频扩散模型 (FVDM),通过引入向量化时间步变量 (VTV),赋予每一帧独立的时间演化路径,从根本上解决了这一难题,显著提升了时序建模能力。
然而,范式的转变需要更多实践的检验和普及。为此,我们与华为香港研究所小艺团队合作进一步推出了 Pusa 项目。Pusa 不仅是 FVDM 理论的直接应用和验证,更重要的是,它探索出了一条极低成本微调大规模预训练视频模型的有效路径。

-
论文标题:Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach
-
FVDM 论文:https://arxiv.org/abs/2410.03160
-
Pusa 主页 / 代码库: https://github.com/Yaofang-Liu/Pusa-VidGen
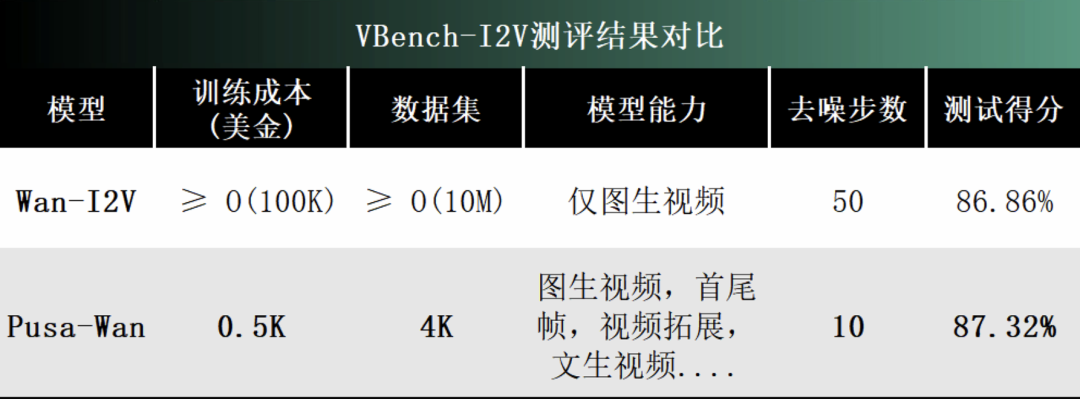
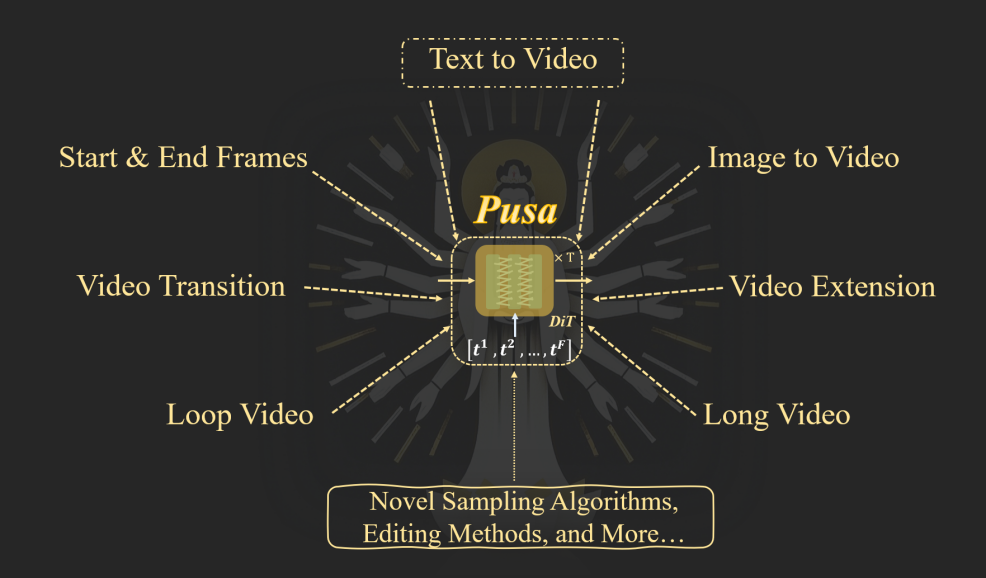
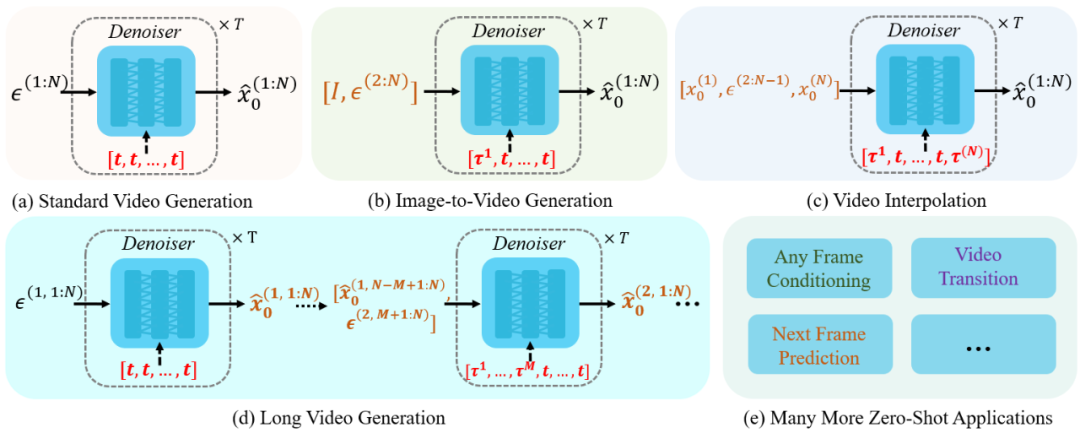
具体而言,Pusa 通过对预训练模型如 Wan-T2V 14B 进行非破坏性微调,仅需 500 美金训练成本即可达到比 Wan 官方 I2V(至少O(100k)美金的训练成本)更好的效果,成本降低超 200 倍,数据更是减少超 2500 倍!不仅如此,Pusa-Wan 同时解锁了图生视频、首尾帧、视频过渡、视频拓展等广泛应用并且还保留了文生视频能力。
Vbench 图生视频测试样例
文本指令:一只大白鲨在海里游泳(a great white shark swimming in the ocean)

文本指令:一个戴着墨镜坐在汽车驾驶座上的男人(a man sitting in the driver’s seat of a car wearing sunglasses)

文本指令:一头棕白相间的奶牛正在吃干草(a brown and white cow eating hay)

此外,Pusa-Mochi 更是只要 100 美金训练成本便可实现如下效果。
图生视频效果对比
首尾帧效果对比
更多首尾帧样例

T2V 结果与基础模型 Mochi 对比

目前,Pusa 的完整代码库、训练数据集和训练代码已全面开源,旨在推动整个领域的共同进步。
方法:FVDM 的帧感知核心与 Pusa 的巧妙实现
FVDM 方法
沿袭自图像扩散模型,当前的视频扩散模型也采用一个标量时间变量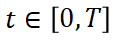 ,该变量统一应用于正在生成的视频的所有帧。在视频生成的背景下,这种方法无法捕捉视频序列中各帧间的动态关系。为了解决这个限制,我们引入了一个向量化时间步变量
,该变量统一应用于正在生成的视频的所有帧。在视频生成的背景下,这种方法无法捕捉视频序列中各帧间的动态关系。为了解决这个限制,我们引入了一个向量化时间步变量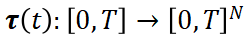 ,定义为:
,定义为:
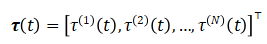
其中 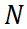 是视频帧数,
是视频帧数,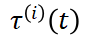 表示第
表示第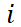 帧的独立时间变量。这种向量化允许对每一帧进行独立的噪声扰动,从而实现更灵活、更细致的扩散过程。
帧的独立时间变量。这种向量化允许对每一帧进行独立的噪声扰动,从而实现更灵活、更细致的扩散过程。
我们将传统的前向随机微分方程 (SDE) 扩展以适应我们的向量化时间步变量。每一帧 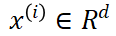 经历由其特定的
经历由其特定的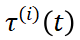 控制的独立高斯分布的噪声扰动过程,可表示为:
控制的独立高斯分布的噪声扰动过程,可表示为:
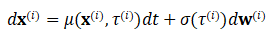
继而,我们可将所有帧的 SDE 集成为整个视频的单个 SDE。我们将视频定义为 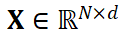 。我们可以将视频表示为一个矩阵整个视频
。我们可以将视频表示为一个矩阵整个视频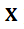 的集成前向 SDE 为:
的集成前向 SDE 为:
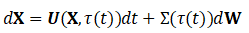
其中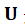 是整个视频的漂移系数,
是整个视频的漂移系数,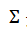 是扩散系数的对角矩阵。
是扩散系数的对角矩阵。
在反向过程的背景下,我们定义了一个集成的反向 SDE 来封装跨联合帧的依赖关系:
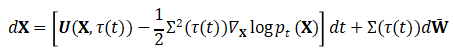
基于分数的模型 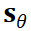 被设计为在整个视频序列上操作。模型的学习目标是近似分数函数:
被设计为在整个视频序列上操作。模型的学习目标是近似分数函数:

模型参数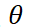 的优化问题表述为
的优化问题表述为
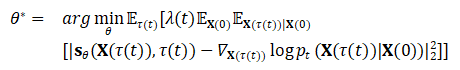
其中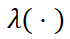 是一个正权重函数。
是一个正权重函数。
模型实现
-
网络架构适配
我们以 Mochi1 及 Wan 这类先进的开源视频模型作为基础。为了引入向量化时间步,我们对其原始的标量时间步输入机制进行了扩展。
具体而言,原先接受 (B)(批量大小)形状标量时间步的模块,被修改为能够处理 (B, N)(批量大小,帧数)形状的向量化时间步。通过正弦位置编码,这些 (B, N) 的时间步被转换为 (B, N, D) 的嵌入表示,并通过 adaLN-Zero 等条件化机制作用于 Transformer 的注意力和 MLP 层。
关键在于,这种改造是「非破坏性的」:当所有帧的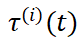 都被设置为相同时,模型的行为与基础模型完全一致,从而完整保留了其强大的基础生成能力。
都被设置为相同时,模型的行为与基础模型完全一致,从而完整保留了其强大的基础生成能力。
-
训练策略与惊人效率
在 FVDM 论文中我们以及发现,由于各帧拥有独立噪声,整体组合空间爆炸(以 16 帧为例,组合共有 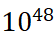 种),训练极难收敛。
种),训练极难收敛。
FVDM 独创的概率性时间步采样训练策略 (PTSS) 成功解决了这个问题:在训练时,我们以概率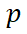 为每帧采样随机独立的时间步,以概率
为每帧采样随机独立的时间步,以概率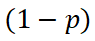 为所有帧采样相同的时间步,如此解耦时序动态与基础生成能力的学习。
为所有帧采样相同的时间步,如此解耦时序动态与基础生成能力的学习。
FVDM 论文实验结果表明该策略可大大加速收敛且取得较原模型 Latte 更好的效果。
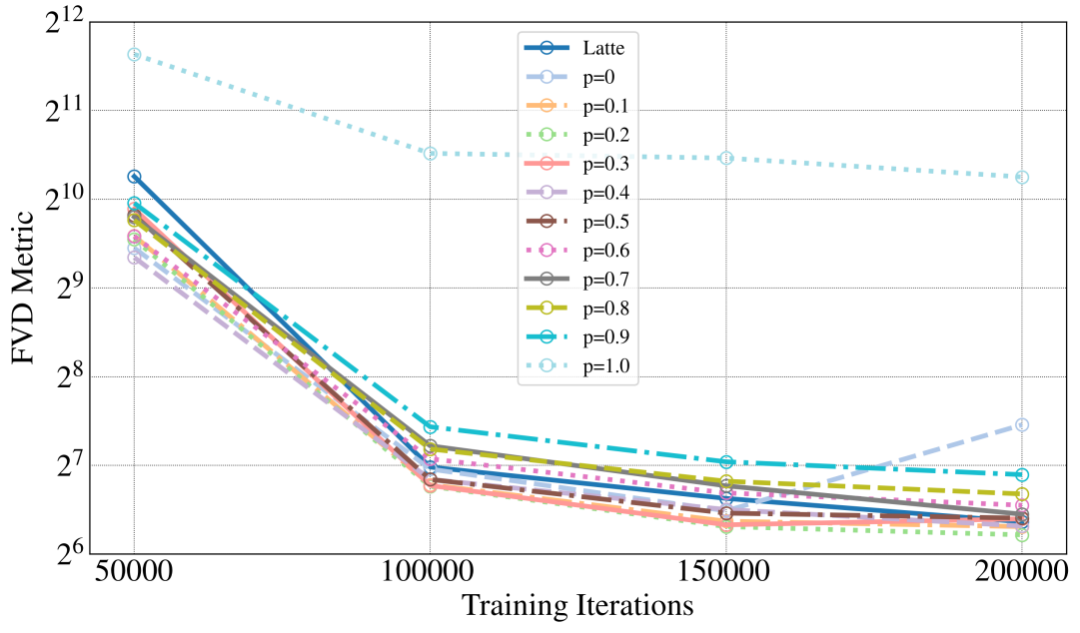
而对于 Pusa,我们还可以简化策略,得益于对基础模型的非破坏性改造,在训练初始模型已经具备充足基础能力,我们只需在此基础上进行少量独立时间步微调便可掌握时序动态控制能力。
Pusa 的「十八般武艺」:零样本解锁多样化视频任务,效果惊艳
基于 FVDM 的 VTV 机制和 Pusa 的高效微调,Pusa 能够通过在 VTV 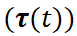 中为不同帧设置不同的时间策略来控制噪声扰动以实现多样化的视频生成任务如可将输入图像作为任意帧,
中为不同帧设置不同的时间策略来控制噪声扰动以实现多样化的视频生成任务如可将输入图像作为任意帧,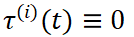 不加噪或
不加噪或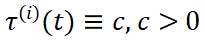 加少量噪声(某些情况下会减少输入图像与生成内容间差异),其余帧保持 T2V 噪声来进行图生视频。 Pusa 的 VTV 机制为更多样的帧级控制采样算法和更细致的视频生成任务打开了大门。
加少量噪声(某些情况下会减少输入图像与生成内容间差异),其余帧保持 T2V 噪声来进行图生视频。 Pusa 的 VTV 机制为更多样的帧级控制采样算法和更细致的视频生成任务打开了大门。
总结与展望:Pusa 引领视频生成进入低成本、高灵活新时代
FVDM 理论通过其核心的向量化时间步变量 (VTV) 为视频生成带来了根本性的变革。而 Pusa 项目则以其惊人的低成本和高效的微调策略,成功地将这一理论付诸实践,并将其推广到强大的预训练模型之上。我们热切欢迎社区的贡献与合作,共同提升 Pusa 的性能,扩展其能力,并探索更多可能性。
©
(文:机器之心)