


新智元报道
新智元报道
【新智元导读】刚刚过去的618,罗永浩又创下炸裂新纪录——被自己的AI分身打败了!在百度电商直播间,罗永浩数字人强势登场,不仅爆梗频出、神似度拉满,还一举打破老罗本人首秀纪录,成交额破5500万。这背后,大模型已成为幕后操盘手!
爆了爆了,罗永浩直播间又爆了。
就在刚刚过去的618,老罗在百度电商直播破了纪录——
观看人次超过1300万,商品交易总额破了5500万!
你以为是真人打败了真人?错了,这一次,是老罗真人被他的数字人打败了。
这次带货单量,直接超越了老罗真人百度电商首秀的同期数据。
这个纪录,甚至惊动了外国媒体。
看看直播间这个老罗,随便一张口就能爆个金句,那味儿简直太正了。
「人到中年还能靠颜值吃饭,也是一种本事。」
「弹幕上问我怎么辨别茅台真假,简单喝一口,心疼就是真的,肝疼就是假的。」
「有人问方便面好不好吃,买回去尝尝,好吃就分给朋友一点,不好吃就全分给朋友。」
旁边的助播——朱萧木数字人,也是跟真人傻傻分不清。
而部分3C、食品等核心品类商品带货单量,老罗的数字人也直接吊打真人,超越了老罗本人5月份在百度电商直播首秀的同期数据,用户平均观看直播的时长也超过了5月真人首秀。

为什么我们看到的「老罗」,无论是长相、微表情、声音,还是口中爆出的梗,都如此酷似真人,形神兼备,模仿出了老罗的「灵魂」?
是老罗本人都吓到的程度
这背后,就是百度研制的多模协同数字人技术了。
该技术方案重点包含剧本驱动的数字人多模协同、融合多模规划与深度思考的剧本生成、动态决策的实时交互、文本自控的语音合成、高一致性超拟真数字人长视频生成五项创新技术,实现了数字人「神、形、音、容、话」的高度统一。
最终,呈现出一个具备高表现力,内容吸引人,人-物-场可自由交互的超拟真数字人。

如何解决?让我们详细看下这套多模协同的数字人技术。

1. 语言模型为核心的剧本生成
这套方案中,剧本生成是核心环节。
这是一个复杂的多维联动的过程,包括台词、多模驱动和动态交互三部分。

· 台词
剧本生成的核心是台词,这是一个融合了多模规划和深度思考的过程。
这次老罗直播的反响之所以如此热烈,一大原因就是两位主播老师活灵活现的台词。
而做到这一点,有三大关键问题要解决。
首先,台词本身是有多样化风格的,需要配合主播本人去打造,因此百度团队开展了风格建模,能够实现对不同风格的生成和定制。
第二,就是打造拟真化的人设,进行不同人设的建模和还原,面对直播间存在多位主播的情况还要在台词生成阶段就考虑不同角色之间的协同。
第三,直播间讲品时,在讲述有吸引力内容的同时要杜绝幻觉出现,因此要平衡内容的创造力和真实性,需要引入深度思考和知识增强等。
具体到老罗数字人的实际技术实施中,百度基于文心大模型4.5 Turbo,投入了他真人直播数据,依托转录挖掘、优质提炼、仿写合成与自动评估等四个环节不断优化训练语料,使模型学习两位主播的语言特点与思维习惯。
同时引入多角色协同机制,对不同主播的表达逻辑进行建模,使对话在语义推进、节奏控制和风格调性上保持协调一致,带给直播观众流畅、自然的观看体验。
· 多模驱动
多模驱动,是指大语言模型基于任务目标与主播人设生成基础台词,并同步输出视觉与语音的多维标签。
比如在语音合成的时候,会利用剧本当中的段间标签,来完成语音段间语调的协调一致,而文本内容也能驱动TTS完成细颗粒度语调的协调一致。
有了语音合成的数据,和剧本对视频的要求之后,在视频的合成和生成时,就能够对高表现力的动作进行对齐,对唇动、表情生成进行对齐,最终实现「声、形、意」三模态的统一。
· 动态交互
动态交互是数字人能够像真人一样,与用户互动的关键能力,也是体现数字人真实性的关键因素。
百度团队设计了丰富的动态交互模式,还通过视频断点设计,让动态视频片段能够在视频流中顺畅衔接。
2. 文本自控的语音合成
在数字人场景中,语音合成也有一系列难点和挑战。
在以前,语音合成很多都是朗诵式的,非常字正腔圆,但在直播间里,说话就要更加自然、流畅,在特定场景时,主播还要非常有激情。
我们在老罗数字人直播间里看到的两位数字人主播自然流畅、抑扬顿挫的语音,百度是如何通过技术手段实现的呢?
这就要归功于文本自控的语音合成技术了。
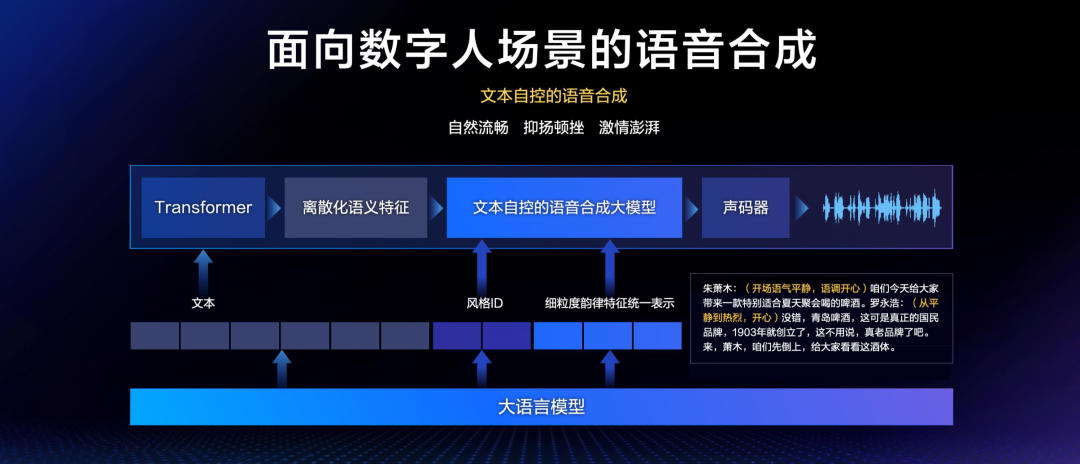
比如下面这段,首先朱萧木在开场时,会语气平静地说:「咱们今天给大家带来一款特别适合夏天聚会喝的啤酒。」
然而老罗的语气就会从平静到热烈,开始激情澎湃:「没错,青岛啤酒,这可是真正的国民品牌,1903年就创立了,这不用说,真老品牌了吧。来,萧木,咱们先倒上,给大家看看这酒体。」
可以看出,这个过程中的难点,就在于语音的高度还原,以及双人配合中时常会出现的打断说话、附和说话。
通过文本自控的语音合成大模型,实现字级别指令遵循的合成能力,控制声音效果的平滑流畅,再结合直播文本及发音人信息,合成风格恰当、自然流畅的声音。
而为了解决老罗和朱萧木这种老搭档式的双人配合,团队还加入了「对话上下文解码器」,将历史对话和当前对话的信息来统一进行合成时的推理计算,最终顺利实现了大量打断、复说的场景。
3. 数字人长视频,超拟真,高一致性
在直播间,要实现数字人本身的形象生成和驱动,挑战也非常大。
首先就是上文提到的多模协同,需要做到多向的对齐,从而实现「音、容、话」三者的一致性。
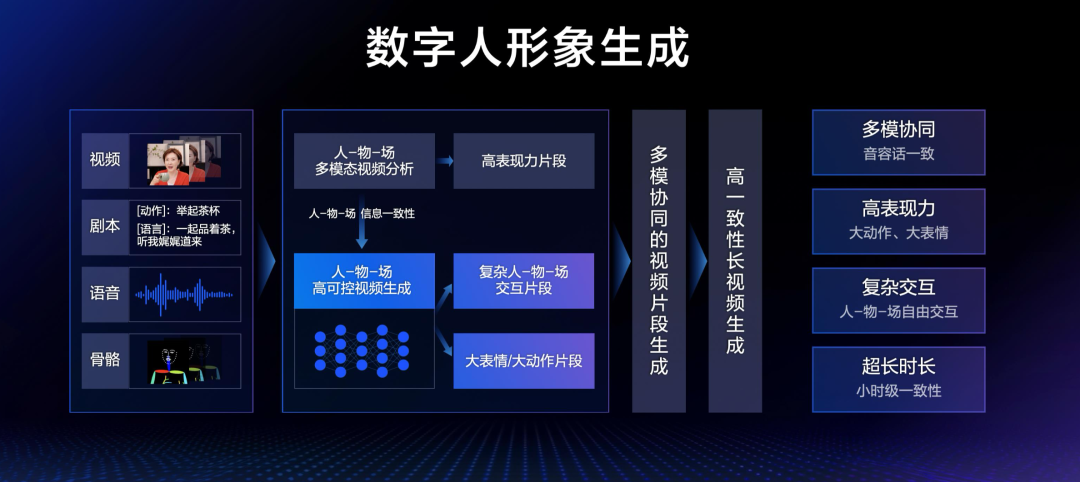
另外,看到两位主播在带货过程中有大量讲品的动作跟手势,这种高表现力的动作和标签,能给用户更强的感染力,但对技术的要求极高。
而且,直播间中还有一个复杂交互的问题,主播本人、面前商品以及背后场景的自由交互,都需要符合物理世界规律,不能出错。
比如一个数字人举起茶杯,嘴里说出「一起品着茶,听我娓娓道来」,此外还有语音和动作的配合,这就必须做到人-物-场的信息一致性,才能生成对应的高可控视频。
最后一个挑战,就是超长时长了。现在的一场直播动辄七八个小时,如何在这么长的时间里保持这种高度的一致性,也是很大的挑战。
在数字人形象生成以及驱动方面,百度通过结合多模态视频理解、跨模态信号生成、视频生成等技术,克服了高可控交互,高精度、长时间一致性保持等难点,实现了高一致性超拟真罗永浩数字人长视频生成。
而且在此过程中,能保证语音、口型、表情与动作始终保持高度同步,从而实现真正的「音、容、话」一致。
而具体到老罗直播间,因为整场直播的商品都非常丰富,不仅品类繁多,体积、位置、用途也各异,为了实现超长视频的一致性,团队对人的ID和商品ID都进行了专门的建模。
这样,就做到了在很长的讲品时间内,数字人都体现出了令人惊叹的高可控交互、人和物品的双高精度,以及长时间的一致性。
罗永浩数字人直播的成功,是文心大模型持续迭代的最新成果。
作为国内最早投入大模型产研的企业之一,百度在芯片、框架、模型、应用四层技术栈上全面布局,并构建起一套从技术到应用的完整战略打法。
作为百度AI技术的核心,文心大模型在过去几年时间已从1.0连续迭代至4.5,再到最新4.5 Turbo和思考模型X1 Turbo的推出,恰为数字人直播提供了强大的支撑。

百度集团副总裁吴甜用了一个生动的比喻:数字人直播就像拍电影,剧本——语言模型提供整体框架,而演员——语音和视觉模型在理解剧本的基础上进行个性发挥。
另一方面,技术和产品永不分家。体验好不好,是要从这两个角度同时考虑。
直播间直播时,数字人的回应如何照顾用户感受,将体验效果极大化,模型本身又触发的逻辑和策略,但还需要综合考虑产品体验。
这种技术架构,不仅提升了直播的真实感,也为未来千人千面个性化奠定了基础。
老罗数字人直播的核心优势,在于成本和效率的领先。
如今,数字人直播的制作已控制在千元级别,远低于真人主播的费用。
未来随着AI迭代,生成制作和在线服务成本,将会进一步下降为规模化应用铺平道路。
百度计划,在未来三个月到半年内,进一步优化技术降低成本,推动数字人直播的市场化。
文心大模型的泛化能力和迁移能力,使得数字人技术不仅适用头部主播,也能快速适配中长尾主播。
即便是数据量较少的普通主播,模型也能通过其他主播数据,实现个性化数字人的生成。
这种普惠化策略,将推动数字人直播在电商、教育、旅游等领域的广泛应用。
据预测,数字人市场规模将在2026年突破百亿。而百度凭借先发优势,已经处于行业领先地位。
数字人直播的长期价值,在于对直播生态的重塑。它不仅是技术的胜利,更是市场接受度和生态融合的起点。
未来,当数字人从直播间走向产业纵深,一场静默的技术渗透早已悄然展开——它们不再是替代人类的「打工人」,而是进化成撬动行业升级的新杠杆。
从带货直播间到文旅场景,从在线客服到虚拟讲师……数字分身正在重新定义「生产力」的新边界。


(文:新智元)