


作者:田小幺
编辑:李宝珠
转载请联系本公众号获得授权,并标明来源
哈佛医学院、波士顿儿童医院、纽约大学及 MIT-IBM 沃森实验室的跨学科团队,共同构建了一个专业级医学推理基准测试数据集,并提出了一种临床思维图谱模型,能够通过临床知识引导的思维图谱提示来模拟诊断过程,将特定领域的临床知识作为视觉和文本输入纳入其中,从而显著增强 LVLMs 的预测能力。
在人工智能技术突飞猛进的当下,大型视觉-语言模型(LVLMs)正以惊人的速度重塑多个领域的认知边界。在自然图像与视频分析领域,这类模型依托先进的神经网络架构、海量标注数据集与强大算力支持,已能精准完成物体识别、场景解析等高阶任务。而在自然语言处理领域,LVLMs 通过对 TB 级文本语料的学习,在机器翻译、文本摘要、情感分析等任务上达到专业级水准,其生成的学术摘要甚至能精准提炼医学文献的核心结论。
然而当技术浪潮涌向医学领域,LVLMs 的落地进程却遭遇显著阻力。尽管临床场景对智能化辅助诊断的需求极为迫切,这类模型的医学应用仍停留在初级探索阶段。核心瓶颈源自医学数据的独特属性:受患者隐私保护法规、医疗数据孤岛效应及伦理审查机制的多重制约,公开可用的高质量医学数据集规模仅为通用领域的万分之一量级。现有医学数据集大多采用基础视觉问答架构,聚焦「这是哪个解剖结构」等初级模式识别任务——如某公开数据集包含 20 万张 X 光片标注,但 90% 的标注内容停留在器官定位层面,无法触及病变严重程度分级、预后风险评估等临床核心需求。
这种数据供给与实际需求的错位,导致模型在面对新生儿缺氧缺血性脑病(HIE)MRI 图像时,虽能识别基底节区异常信号,却无法整合孕周、围产期病史等多维度信息进行神经发育预后预测。
为了突破这一困境,来自波士顿儿童医院联合哈佛医学院、纽约大学及 MIT-IBM 沃森实验室的跨学科团队,收集了 133 名与缺氧缺血性脑病(HIE)相关的个体十年 MRI 图像及专家解读,构建了一个专业级医学推理基准测试数据集,旨在精准评估 LVLMs 在医学专业领域的推理表现。研究团队还提出了一种临床思维图谱模型(CGoT),能够通过临床知识引导的思维图谱提示来模拟诊断过程,可将特定领域的临床知识作为视觉和文本输入纳入其中,从而显著增强 LVLMs 的预测能力。
相关研究成果以「Visual and Domain Knowledge for Professional-level Graph-of-Thought Medical Reasoning」为题,已成功入选 ICML 2025。
研究亮点:
* 创建全新 HIE 推理基准测试,首次将临床视觉感知与专业医学知识结合,模拟临床决策流程,精准评估 LVLMs 在医学推理中的专业表现。
* 全面对比先进通用和医学 LVLMs,揭示其在医学领域知识方面的局限性,为模型改进提供方向。
* 提出 CGoT 模型,融合医学专业知识与 LVLMs,模仿临床决策过程,有效增强医学决策支持。

论文地址:
https://openreview.net/forum?id=tnyxtaSve5
关注公众号,后台回复「临床思维图谱」获取完整 PDF
更多 AI 前沿论文:
https://go.hyper.ai/owxf6
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
HIE-Reasoning:多模态数据集构建与专业推理任务体系创设
在数据构建层面,该研究聚焦缺氧缺血性脑病(HIE)这一新生儿重症,历时 10 年收集了 133 例 HIE 患儿从出生 0-14 天内的高质量 MRI 影像,同步获取经多学科专家(包括拥有 30 年经验的资深神经放射科医生)临床验证的解读报告,形成纵向追踪的核心数据集。
如下图所示,研究人员定义了 6 项任务供 LVLMs 执行专业临床推理:
* 任务 1:病变分级(Lesion Grading)。该任务通过估算受HIE病变影响的大脑体积百分比以及评估病变的严重程度来量化大脑损伤。
* 任务 2:病变解剖学(Lesion Anatomy)。该任务识别受病变影响的大脑特定区域。
* 任务 3:罕见部位病变(Lesion in Rare Locations)。该任务识别由 HIE 引起的病变,并将受影响区域分为常见或不常见,帮助确定患者是否需要额外关注。
* 任务 4:MRI 损伤评分(MRI Injury Score)。该任务输出 MRI 的整体损伤评分,提供一个标准化的损伤严重程度衡量标准,以指导治疗和预测结果。
* 任务 5:2 年神经认知结果(Neurocognitive Outcome)。该任务预测患者 2 年后的神经认知结果,帮助临床医生预测长期影响并计划适当的干预措施。
* 任务 6:MRI 解读总结(MRI Interpretation)。该任务基于放射科医生推荐的新生儿 MRI 总结模板,能够为患者生成全面的 MRI 解读。
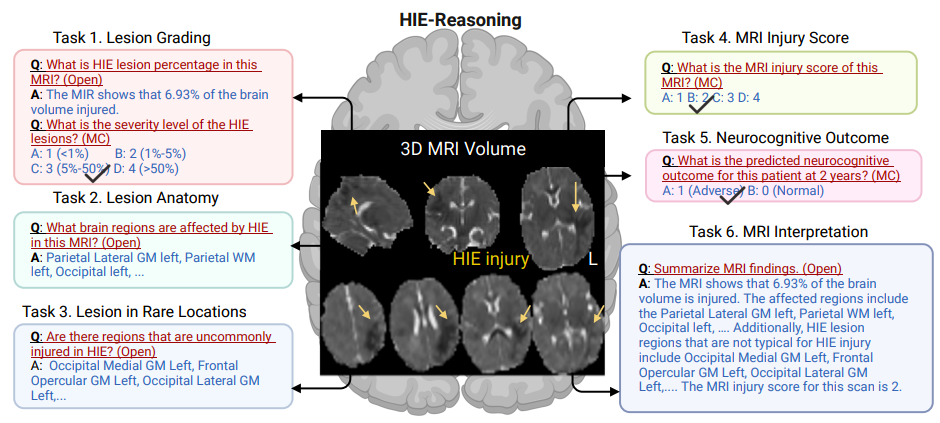
HIE-Reasoning 数据集和任务概述
最终,研究人员构建了全球首个公开的 HIE 数据集 HIE-Reasoning,含 749 对问答和 133 个 MRI 解读总结。与VQAmed、OmiMed-VQA 等传统医学数据集聚焦成像方式识别、器官定位等基础问题不同,该数据集首次将临床专家的深度推理过程转化为可计算的评估体系,其数据结构创新采用三层架构——患者级原始影像与任务文件、跨案例元知识推理模板、个体病变概率图谱,既保留医学数据的完整性,又为模型提供包含病理机制的显性知识输入。
尽管样本量仅 133 例,但通过长达 17 年(2001-2018年)的多中心回顾性收集,结合 HIE 在三级医院 1-5‰ 的低发率特征,该数据集成为首个整合影像-临床-预后多模态信息的HIE专用基准,其标注精度与临床深度足以弥补规模限制,为 LVLMs 突破「基础识别」瓶颈、进入诊疗决策深水区提供了不可或缺的标尺。
CGoT 模型:临床思维图谱驱动,构建可解释分层医学推理新框架
为突破传统大型视觉-语言模型(LVLMs)在医学推理中的解释性瓶颈(如下图 A 所示),研究团队提出了临床思维图谱模型(CGoT),如下图 B-C 所示,通过整合临床知识引导语言模型模拟医生诊断流程,从而显著提升预测神经认知结果的可靠性。该模型创新性地采用结构化「推理思维图谱」,将医学专家的诊断步骤转化为分层推理管道,通过逐步累积知识解决复杂任务。
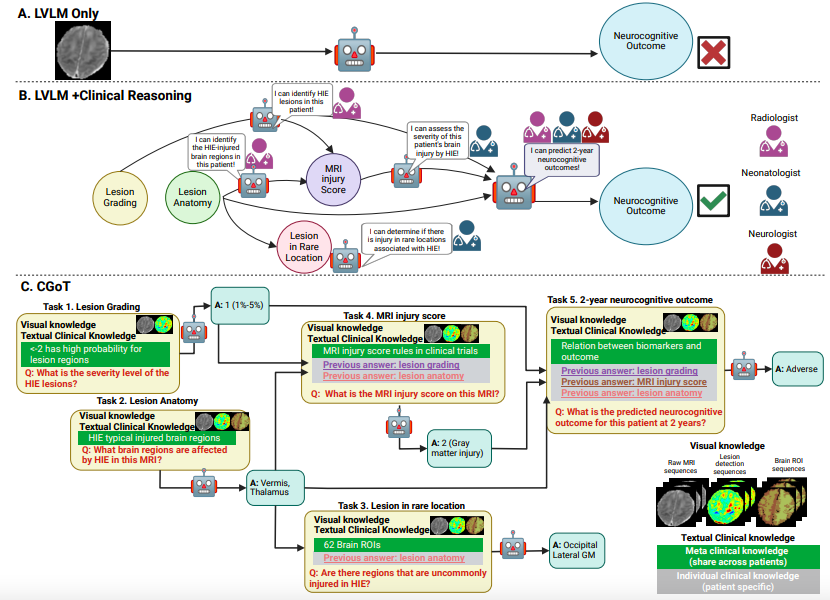
LVLM 与 CGoT 的推理图
CGoT 的核心是 6 个层级递进的关键任务,涵盖病变分级、解剖定位、损伤评分及两年预后预测,每个步骤均建立在前序任务基础上,形成与临床评估一致的推理链条。例如,在解剖定位任务中,模型通过模拟放射科医生角色识别特定脑区损伤,并通过自洽陈述表达推理过程。这种设计使模型能够像医生一样,通过逐步累积信息完成精准诊断。
为实现这一目标,CGoT 融合了视觉知识与临床文本知识两大知识来源。视觉知识端融合表观扩散系数(ADC)原始影像、ZADC 标准化病变概率图以及基于 62 个大脑感兴趣区域(ROIs)的个体解剖图谱,其中 DRAMMS 工具将标准解剖空间映射至患者个体化空间,赋予模型放射科医生的解剖定位能力。
文本知识端则分为元临床知识(含大脑解剖图谱、病变分布规律、MRI 生物标志物预后关联等通用医学背景)与个体临床知识(通过前序任务输出动态生成的患者特异性诊断线索),两类知识以 Prompt Engineering方式结构化输入,引导 LVLM 按照「临床指南-影像特征-个体病史」的逻辑链逐步推导。
这种设计使 CGoT 能够模拟医生阅读 MRI 报告时的分层推理过程:首先基于 ADC 图识别异常信号区域,借助 ZADC 图量化病变概率,再结合 62 区解剖图谱定位损伤部位,继而依据 NRN 评分系统整合损伤体积与解剖位置信息生成整体评分,最终结合元知识中的预后模型与个体临床特征预测神经发育结局。
整个框架通过临床图结构化提示与跨模态知识融合,将隐性的医学诊断逻辑转化为可计算的模型输入,既保留了 LVLMs 的跨模态处理能力,又通过临床知识锚定避免了推理过程的随机性。
CGoT 临床推理效能评估,在关键任务上实现突破性提升
为验证 HIE-Reasoning 基准测试与 CGoT 模型的有效性,研究团队设计了多维度实验体系。
首先,研究人员对 6 个大型视觉语言模型进行了零样本评估,选取了 3 类通用 LVLMs(Gemini1.5-Flash、GPT4o-Mini、GPT4o)与 3 类医学 LVLMs(MiniGPT4-Med、LLava-Med、Med-Flamingo)作为基线模型,针对病变分级、解剖定位、预后预测等 6 大临床任务,采用准确率、MAE、F1 分数、ROUGE-L 等任务特异性指标进行评估,其中两年神经认知结果预测采用类别间平均准确率以平衡标签分布偏差。
实验结果揭示了传统 LVLMs 的显著局限性:当直接输入 MRI 切片与任务描述时,所有基线模型在专业医学推理任务中表现不佳,部分模型因缺乏临床知识出现回答幻觉或保守拒答,例如 Med-Flamingo 在解剖定位任务中生成无意义重复内容,GPT4o 系列因对齐策略无法处理高不确定性问题。
与之形成鲜明对比的是,如下表所示,CGoT 模型通过整合临床思维图谱与跨模态知识,在关键任务上实现突破性提升——尤其在两年预后预测这一核心临床需求上,其性能较基线模型提升超过 15%,病变分级、损伤评分等任务的准确率与一致性也显著优于对照组。
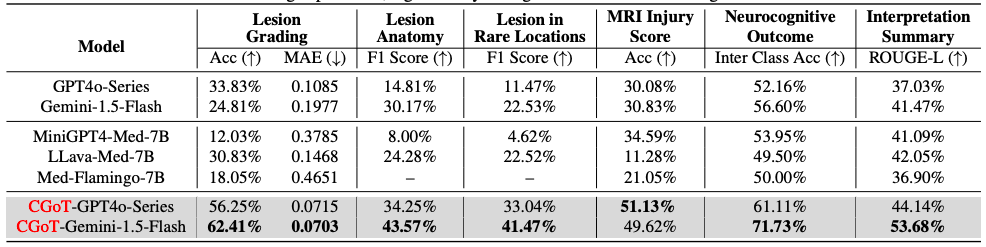
各种模型在 HIE-Reasoning 基准上的性能比较
如下图所示,定性分析显示,CGoT 能够生成可解释的中间推理步骤,如「右侧基底神经节病变伴 MRI 损伤评分 2 级」,为临床决策提供透明化的关键生物标志物支持。
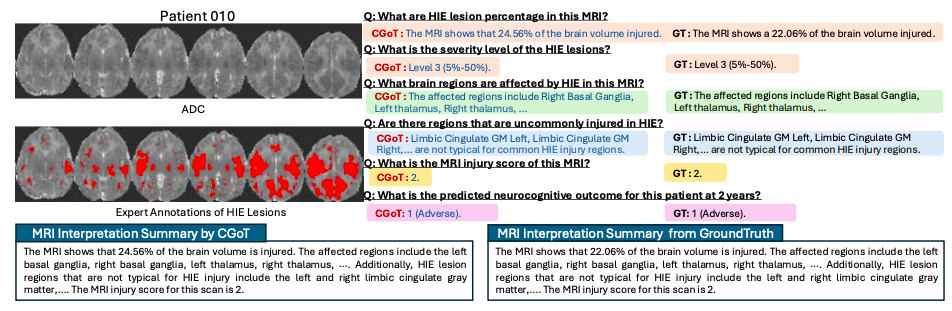
CGoT 定性结果
消融研究进一步拆解了 CGoT 的核心组件价值:移除临床知识输入或推理图谱结构均导致性能大幅下降,其中推理图谱缺失使准确率降幅最大,验证了结构化临床逻辑对医学推理的必要性;完整性测试表明,MRI 损伤评分等关键任务的缺失会破坏预测链条,突显多任务整合对预后评估的重要性。
同时,鲁棒性实验显示,即使在 10%-30% 的中间任务结果中引入 ±1 级评分扰动,模型性能仅呈现渐进式下降,证明其对临床实践中常见数据噪声的适应能力。这些发现共同表明,CGoT 通过模拟临床诊断的分层推理过程,既突破了传统模型的知识盲区,又构建了贴近真实诊疗场景的可靠决策支持体系。
医学 LVLMs 的双轮驱动,学术界与企业界的创新实践与趋势
在全球范围内,医学领域的大型视觉-语言模型(LVLMs)研究与应用正经历范式变革,学术界与企业界的创新实践共同推动着这一领域的突破。
在学术研究层面,上海人工智能实验室联合华盛顿大学/莫纳什大学/华东师范大学等多所科研单位共同发布的 GMAI-MMBench 基准测试,整合了 284 个临床任务数据集,覆盖 38 种医学影像模态与 18 项核心临床需求(如肿瘤诊断、神经影像分析等)。该基准通过词汇树分类系统,将病例按科室、模态与任务类型精准归类,为评估 LVLMs 的临床推理能力提供了标准化框架。
* 点击查看完整报道:含284个数据集,覆盖18项临床任务,上海AI Lab等发布多模态医疗基准GMAI-MMBench
此外,埃默里大学、南加州大学、东京大学和约翰霍普金斯大学联合开发的 Med-R1,针对传统监督式微调(SFT)方法的局限性,创新性地引入群体相对策略优化(GRPO),无需复杂的价值模型即可通过规则奖励和群体比较稳定策略更新。香港科技大学推出的 MedDr 等开源 LVLMs 在特定任务(如病变分级)上的表现已接近商业模型,证明了开源生态在医学 AI 领域的潜力。
企业界则以技术落地为核心,加速推动 LVLMs 的临床转化。例如,微软 Azure 医疗云平台通过整合 AI 工具与临床数据,实现了医学影像分析、电子病历自动化等功能的深度融合。其与多家医院合作开发的智能放射学系统,能够通过 LVLMs 快速识别 MRI 影像中的异常区域,并生成结构化报告,辅助医生完成病变分级与解剖定位任务。
谷歌推出了开源医疗模型 MedGemma,基于 Gemma3 架构,专为医疗健康领域设计,旨在通过无缝结合医学图像和文本数据的分析,来增强医疗健康应用,提升医疗诊断与治疗的效率。
* 点击查看详细报道:谷歌发布MedGemma,基于Gemma 3构建,专攻医学文本与图像理解
这些实践共同揭示了医学 LVLMs 发展的两大趋势:一是临床知识与模型架构的深度融合,例如本文所述研究的 HIE-Reasoning 基准测试中通过专家标注构建的任务体系,以及 CGoT 模型引入的临床思维图谱;二是跨学科协作与数据治理的创新,如 GMAI-MMBench 通过统一标注格式与伦理合规流程整合全球数据集,为解决医学数据稀缺性提供了范例。未来,随着联邦学习、合成数据生成等技术的进一步应用,学术界与企业界有望在更复杂的临床场景(如多模态预后预测、实时手术导航)中实现突破,真正推动 AI 从辅助工具向智能决策伙伴的角色转变。
参考文章:
1.https://blog.csdn.net/Python_cocola/article/details/146590017
2.https://mp.weixin.qq.com/s/0SGHeV8OcXu8kFk68f-7Ww



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)