跳至内容


月之暗面开源Kimi-VL-A3B-Thinking-2506。
智东西6月23日报道,月之暗面今日开源多模态模型Kimi-VL-A3B-Thinking-2506,这是其首个开源多模态推理模型Kimi-VL-A3B-Thinking发布两个月后的更新版本,可凭借2.8B激活参数(16B总参数)在多项测评中超越GPT-4o、Qwen2.5-VL-7B等模型。
▲Hugging Face截图
https://huggingface.co/moonshotai/Kimi-VL-A3B-Thinking-2506
与之前的版本相比,2506版本提供了多项全新或改进的功能:
1、它在消耗更少tokens的同时思考得更聪明:2506版本在多模态推理基准上达到了更好的准确率:MathVision上得分为56.9(+20.1),MathVista上为80.1(+8.4),MMMU-Pro上为46.3(+3.2),MMMU上为64.0(+2.1),而平均需要减少20%的思考长度。
2、思考过程更清楚可见:与之前的思考版本不同,2506版本在一般的视觉感知和理解上也能达到相同甚至更好的能力,例如MMBench-EN-v1.1(84.4)、MMStar(70.4)、RealWorldQA(70.0)、MMVet(78.4),超越或匹配其非思考模型(Kimi-VL-A3B-Instruct)的能力。
3、扩展至视频场景:2506版本在视频推理和理解基准方面也有显著提升。它在VideoMMMU上为开源模型刷新记录(65.2),同时在通用视频理解方面也保持了良好的性能,在Video-MME上达到71.9,与Kimi-VL-A3B-Instruct相当。
4、分辨率进一步提升:2506版本支持单张图像320万像素(1792×1792),比上一版本提升了4倍。这在高分辨率感知和OS-agent基准测试中带来了显著提升:在V* Benchmark(未使用额外工具)上得分为83.2,在ScreenSpot-Pro上得分为52.8,在OSWorld-G上得分为52.5。
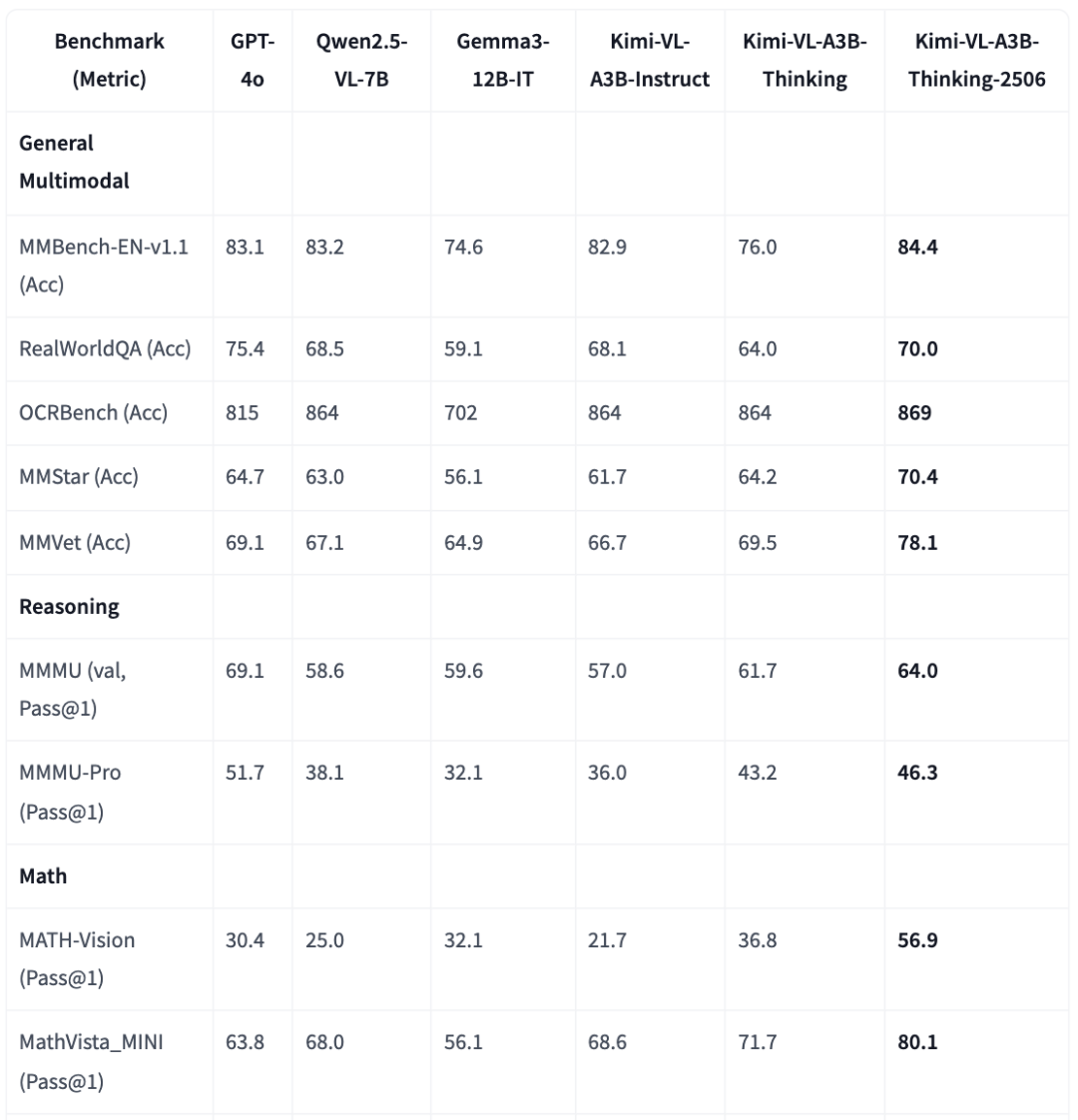
具体来看,与业界顶尖模型和Kimi-VL的两个先前版本的比较,2506版本测试性能明显提升:
在通用多模态方面,2506版本在MMBench-EN-v1.1(Acc)、OCRBench(Acc)、MMStar(Acc)、MMVet(Acc)多项测评的得分超过OpenAI的GPT-4o。
在推理能力方面,2506版本在MMMU(val,Pass@1)、MMMU-Pro(Pass@1)上的测试成绩超过Qwen2.5-VL-7B、Gemma3-12B-IT,不如GPT-4o,但差距有所缩小。
在数学能力方面,2506版本在MATH-Vision(Pass@1)、MathVista_MINI(Pass@1)中得分大超GPT-4o。
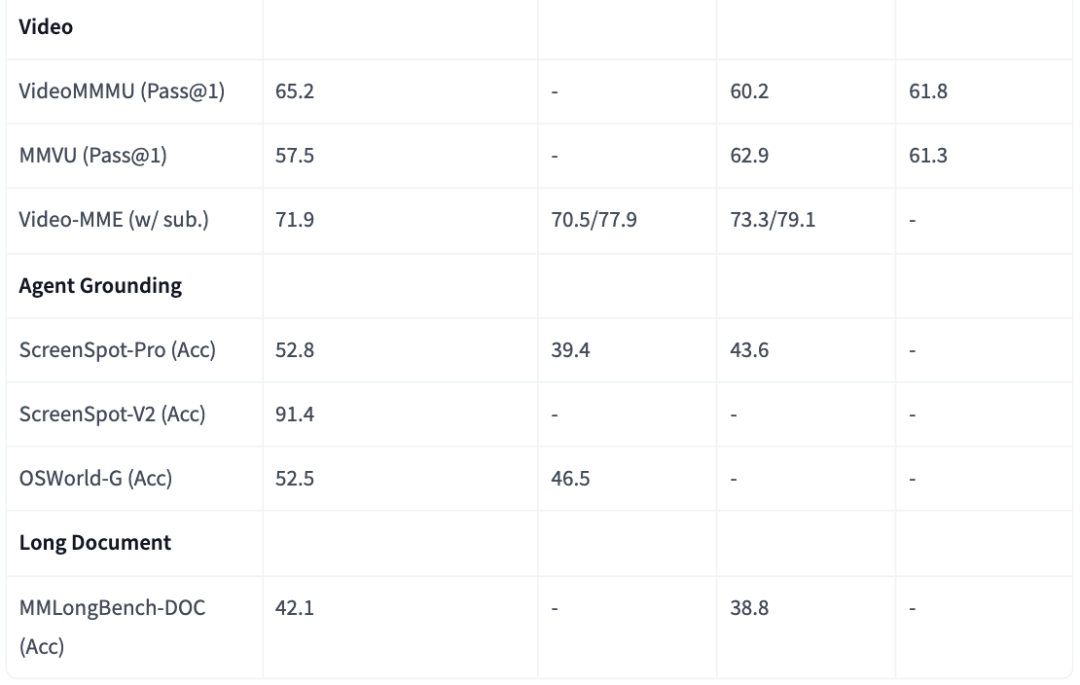
在视频能力方面,2506版本在VideoMMMU(Pass@1)、MMVU(Pass@1)、Video-MME(w/sub.)多项测评中超过Qwen2.5-VL-7B、Gemma3-12B-IT,与GPT-4o的差距缩小。
在Agent落地方面,2506版本在ScreenSpot-Pro(Acc)、ScreenSpot-V2(Acc)、OSWorld-G(Acc)测试中得分都超越Qwen2.5-VL-7B。
在长文本方面,2506版本在MMLongBench-DOC(Acc)测试中超越Qwen2.5-VL-7B,与GPT-4o接近。
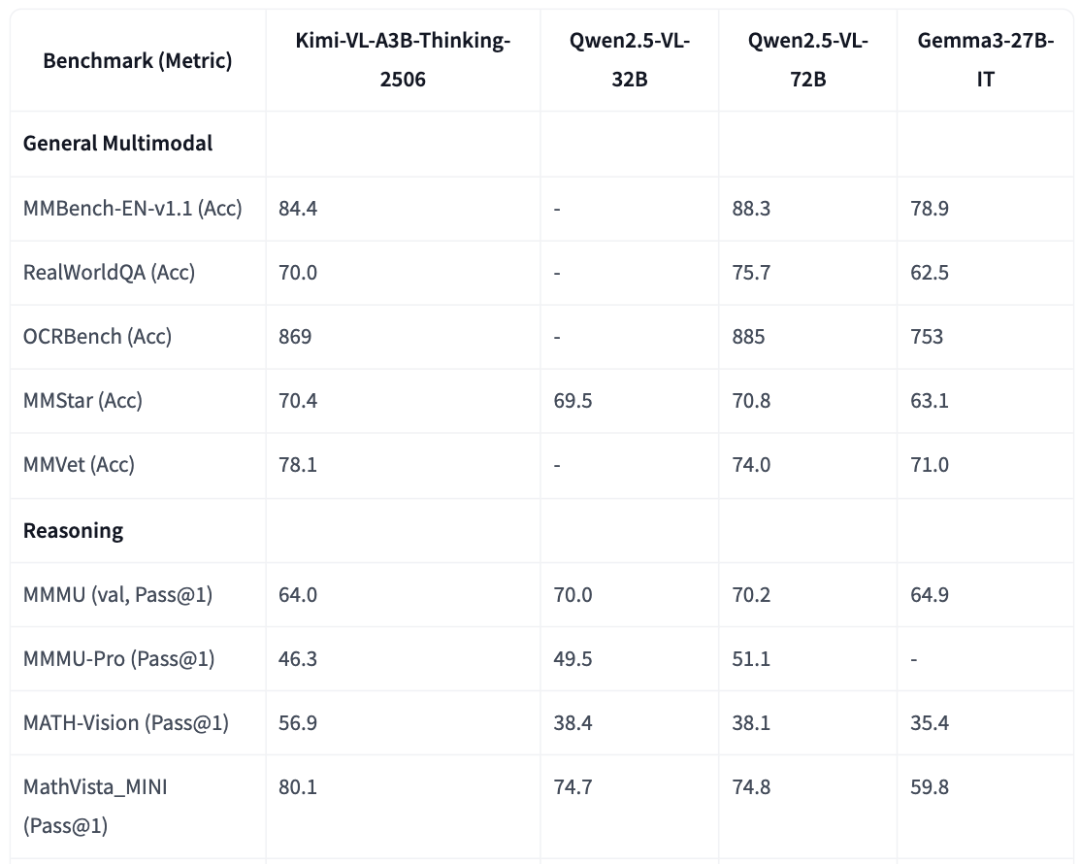
如下图所示,与30-70B的开源模型对比,2506版本的大部分测试已经超越Qwen2.5-VL-32B、Gemma3-27B-IT,看齐Qwen2.5-VL-72B。
(文:智东西)