

Datawhale干货
作者:koin
AI+安全的实践系列分享来了!

颁奖仪式:乌镇峰会热议AI反诈:国内首个AI大模型攻防赛收官,全球十强亮相
通过攻防双向赛道竞技,大赛最终角逐出全球十强。
赛后Datawhale邀请到了本届十强,为大家带来系列复盘分享。
今天,我们和防守方向的Top5团队聊一聊。

赛道二出题人代表点评
“康佬带我飞队”采用了层次化集成学习的思想,用多个不同类型的基模型和抽样的训练数据进行训练,再层次化混合推理结果及其相关预测标签作为B榜的伪监督数据进行模型调优。在数据和标签的融合策略上思路清晰且系统化,展现了团队良好的竞赛经验和工程化思维,最终也取得了赛道二的最佳效果。
复盘分享
写在前面
数据可视化
本次比赛数据集规模100w+ ,A榜测试集10w,B榜测试集10w ,大致数据可以分为生活类,证件类,海报类,其他。

数据清洗

数据去重
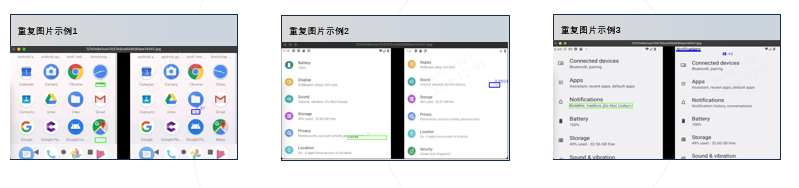
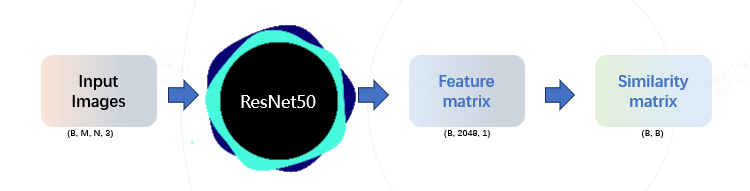
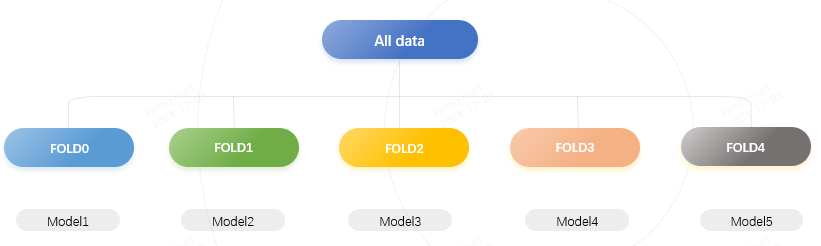
数据拆分
数据伪标签

模型选型

模型指标
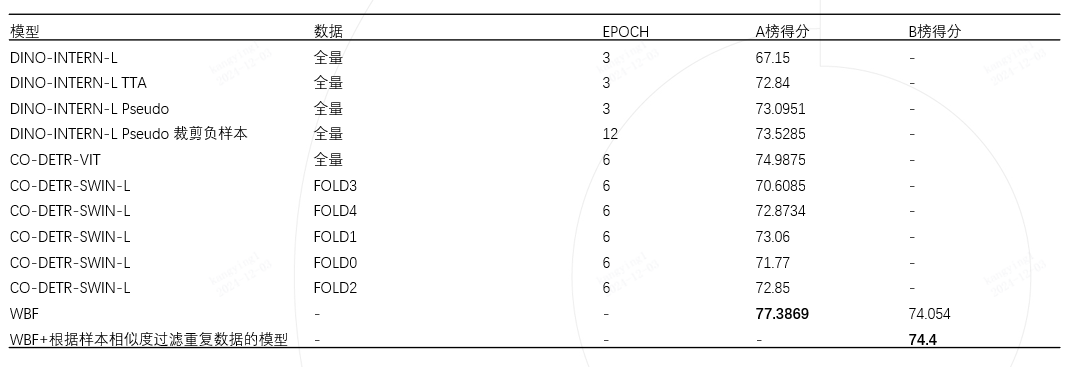
总结反思


(文:Datawhale)