跳至内容


今年,字节跳动旗下AI应用豆包的交互方式迎来多次升级,从春节期间的实时语音通话,再到5月份新增的视频通话功能,如今,豆包已经能像真人一样通过多模态交互实现无缝沟通。
打开视频通话功能,随手对准一个欧洲小国的国旗,豆包便能结合音视频信息,瞬间给出正确答案。
通话过程中,用户可以随意地停顿、思考、改变话题,豆包能准确地把握回复的时机;而在豆包说话时,可以随时打断,向它提出新的要求。
在地铁站、电梯、地下车库等较为复杂的网络环境下,豆包的实时交互能力也不会大打折扣。下方案例中,豆包的响应速度没有出现明显的问题,给出的回答也正确、清晰。
要实现这种近乎直觉性的体验,并在一款国民级AI应用中稳定提供实时音视频交互,豆包需要攻克不少挑战。
除了提升模型能力之外,实时音视频交互要如何将摄像头捕捉的画面高清呈现,如何将AI的视觉推理和搜索反馈同步,又如何在疯狂丢包的弱网环境中依旧维持高质量通信?
豆包最终选择的方案,是火山引擎的RTC(Real Time Communication,实时音视频)技术。目前,真人用户间的音视频通话几乎都依赖RTC技术,火山引擎智能互动产品负责人杨若扬向智东西透露,他认为,未来的人机音视频通话也必将全面进入RTC时代。
RTC是一项专门为低延迟互动设计的技术,能降低通信延迟、确保实时性和质量,让用户与用户、用户与系统间实现近乎“面对面”般的无缝音视频交互体验。
这项技术涉及多个模块,比如音视频的采集与编解码、网络传输、网络自适应等,这些模块协同工作,保证了用户从摄像头、麦克风采集的数据能清晰流畅的传送至接收方,而用户也能及时收到对方的音视频反馈。
虽然RTC并不是目前业内唯一的实时交互方案,但与基于TCP协议实现的另一大主流方案WebSocket相比,RTC拥有显著的优势。
协议方面,RTC底层采用UDP传输,避免了传统TCP必须完整接收再传给应用层的机制。RTC允许一定程度丢包但保证速度,因此延迟非常低,特别适合实时音视频通话和互动。
理想情况下,RTC和WebSocket的语音延迟差异不大。但现实世界的网络情况复杂多变,WebSocket对丢包比较敏感,网络波动时延迟明显升高,不如RTC流畅。
RTC技术具有较强的抗弱网能力。线上实测数据清晰印证,在20%丢包环境下,WebSocket方案已出现严重卡顿、断连,并且线上已有高达15%的用户不可用;而RTC即使在80%极端丢包下,不可用率也仅为1%,体验稍有滞后(延时4.6s)。
在视频场景,RTC技术还可以利用其带宽估计、前向纠错(FEC)和丢包重传等抗拥塞能力与端到端传输优化,有效降低移动网络或拥挤WiFi下画面花屏与卡顿的风险。
火山引擎的RTC技术于2021年随品牌发布上线,但其研发始于2017年,用于满足抖音直播连麦等需求。此后,这一技术陆续在字节内部的音视频通话、社交娱乐、游戏、在线会议等场景落地。
2021年火山引擎成立后,其RTC技术逐渐产品化,承载能力也不断提升。而生成式AI的爆发,给RTC技术带来了新的发展机遇,2024年初,火山引擎推出了基于RTC的对话式AI技术方案,这便是豆包交互体验升级背后的重要支撑。
我们已在文章开头的案例中,看到了RTC支持下豆包语音交互、视频电话的流畅、即时性体验。在智东西与火山引擎智能互动产品负责人杨若扬的沟通中,我们了解到了这一效果背后的具体实现。
豆包首先充分利用了火山引擎RTC方案的既有优势,实现了低延迟、高质量和抗弱网的音视频交互体验。
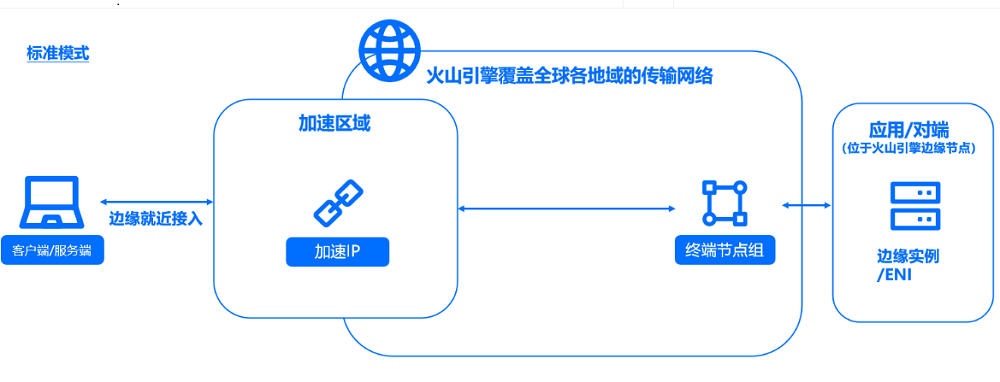
在网络层面,火山引擎拥有覆盖全球的边缘节点和骨干网络,这能有效缩短数据传输物理路径,减少中间节点,降低延迟和丢包风险。同时,智能路由技术可实时感知链路状态和拥塞情况,动态选择最优路径,确保数据传输高效流畅。
在算法层面,火山引擎RTC技术拥有网络、音频和视频多类算法。网络侧通过动态带宽、自适应传输、前向纠错、智能重传等机制提升弱网适应能力;音视频侧结合神经网络编解码、分层和感知内容编码等技术,动态优化编码参数,有效缓解“最后一公里”网络不确定性,保障用户端音视频传输的清晰度与稳定性。
杨若扬认为,在豆包这样的“对话式AI”场景,RTC技术所服务的对象已从人和人之间的交流,转变为人与机器的交流。火山引擎RTC技术针对新场景的特点,在音视频处理层面做了针对性的升级和优化。
视频流与大模型在输入输出形式上存在明显差异:视频由一帧帧图片组成,而当前的多模态大模型以理解单张图片为主,这要求模型能分析帧间联系与时序,保证语义连续,因此必须不断优化视频理解与关键帧提取算法,以提升模型对动态场景的感知与处理能力。
在人与AI的对话中,AI如何准确断句,选择接话、插话的时机也是一大挑战。人类能凭语境判断对方话语结束时间,并凭音色识别说话者、滤除无关噪声,而大部分AI系统仅依赖停顿时长判断,往往不够准确,这就需要引入智能语义判停与声纹降噪算法。
智能语义判停技术可以根据语义判断用户话语是否完整,让模型不会过早回复。下方案例中,用户可以停顿,思考,而不会被豆包插话。
而声纹降噪算法能在嘈杂环境中聚焦目标说话者,屏蔽环境人声及噪声干扰,将误打断率降低15%-20%。
这些改进让AI在音视频通话中展现出更接近人类的特征,也让用户在与豆包对话时能获得更加流畅、自然、贴近真实互动的使用感受。
随着大模型与AI应用的日渐成熟,音视频已成为新一代AI交互中不可或缺的一部分,这些模态所提供的沉浸式体验对用户天然有吸引力和亲近性。
在虚拟陪伴、智能玩具、智能家居、智能教育等广阔场景中,用户对于低延时、高质量、自然流畅的人机对话需求与日俱增,而火山引擎RTC这样能够支撑复杂场景实时音视频交互的底层传输技术正是保障用户体验的关键。
在多Agent、多人场景中,RTC技术还展现出较好的可扩展性,相较传统WebSocket实现语音方案,RTC在网络层和算法层都更为成熟,原生支持房间管理、多流控制、音视频混音与优先级策略,可应用于多人娱乐、企业办公等场景。
火山引擎基于RTC的对话式AI技术,不仅仅是“豆包专属”,而是能为所有AI时代的产品提供重要价值。作为火山引擎的核心音视频技术之一,RTC 已广泛应用于字节各大业务场景,在真实用户环境中反复打磨与优化。
同时,火山引擎提供的RTC服务与其内部业务完全同源,换句话说,企业通过火山引擎接入RTC,使用的就是与抖音、飞书、豆包同款的算法、架构与策略。
当然,RTC技术也存在行业共性难题:一方面,自建集成方案门槛较高,需要专门的网络传输与音视频处理能力,另一方面,云服务资源消耗也不可小觑,此外深度音频算法调优也需大量投入。
杨若扬观察到,上述难题导致许多企业不得不选择实现成本相对低廉、门槛较低的WebSocket,一定程度上牺牲用户体验,等待用户规模扩展后再考虑换用更成熟方案,这无形中限制了产品的成长与竞争力。
针对这些痛点,火山引擎对话式AI一站式方案提供了低门槛、高质量的接入途径。开发者无需从零开始搭建复杂架构,即可实现用户与AI的实时音视频互动,构建契合业务场景的AI实时对话能力。
▲火山引擎对话式AI官网:
https://www.volcengine.com/product/veRTC/ConversationalAI
火山引擎还为开发者提供了每月10000分钟的免费额度,进一步降低了开发者的前期验证与迭代成本。
在对话式AI场景中,RTC正在成为企业的优选方案,这种整合方案让企业能更加专注业务创新,以更低成本、更快速度落地语音与音视频能力,从一开始就为用户带来高品质的交互体验,为下一代智能应用赢得先机与口碑。
火山引擎的对话式AI一站式方案,让实时音视频从“难点”变成“标配”,为各类AI应用与智能体生态拓展广阔空间,让未来的人机互动更加顺畅、高效、有温度。
杨若扬称,在多模态音视频技术上,火山引擎希望让人和AI之间的对话越来越接近人与人之间的真实沟通,这也是他们未来持续努力的方向。
(文:智东西)