


作者熊璟,香港大学一年级博士生,师从黄毅教授和孔令鹏教授。已在 ICLR、ICML、NeurIPS、ACL、EMNLP、TMLR等顶级会议/期刊发表论文,研究方向为高效大语言模型推理与自动定理证明。担任NAACL、EMNLP、ACL、ICML、ICLR、NeurIPS、COLING等会议审稿人。个人主页: https://menik1126.github.io/
引言:大模型长文本推理的瓶颈与突破
随着大语言模型(LLMs)能力日益提升,AI 对超长文本的理解和处理需求也变得前所未有地重要。然而,目前主流 LLM 虽然依赖旋转位置编码(RoPE)等机制,在训练阶段能高效处理 4K-8K tokens 级别的上下文,但一旦推理阶段外推遇到如 128K 以上长度的长文本时,模型往往受到显存瓶颈的限制和注意力下沉 (attention sink) 等问题影响,采用常规的文本截断方案容易出现信息遗失,这极大限制了大模型在实际场景中的应用拓展。
业界目前尝试的处理长文本的高效推理主要的瓶颈有两个, 一个是位置编码的长度外推, 再一个是长度外推中的内存瓶颈。
目前的位置编码包括两类:一是基于频率区分的 NTK 插值方法,为不同频段位置编码设计专属策略以试图拓展长度上限;二是各种分块(chunking)方法,将文本切分、块内复用位置编码,避免重新训练的高昂成本。 在处理超长上下文(>128K)外推时, 两种方案的优劣仍是未知的。
在解决显存瓶颈时 , 普遍采用了KV cache压缩的方案 , 并且一些方案发现在传统自回归场景下的注意力普遍遭遇了 “注意力下沉”(Attention Sink)现象影响 —— 模型的注意力极易集中在文本首尾 , 如果加以合理利用可以提升模型性能,但在并行注意力下的注意力下沉的机制是仍待探索的。
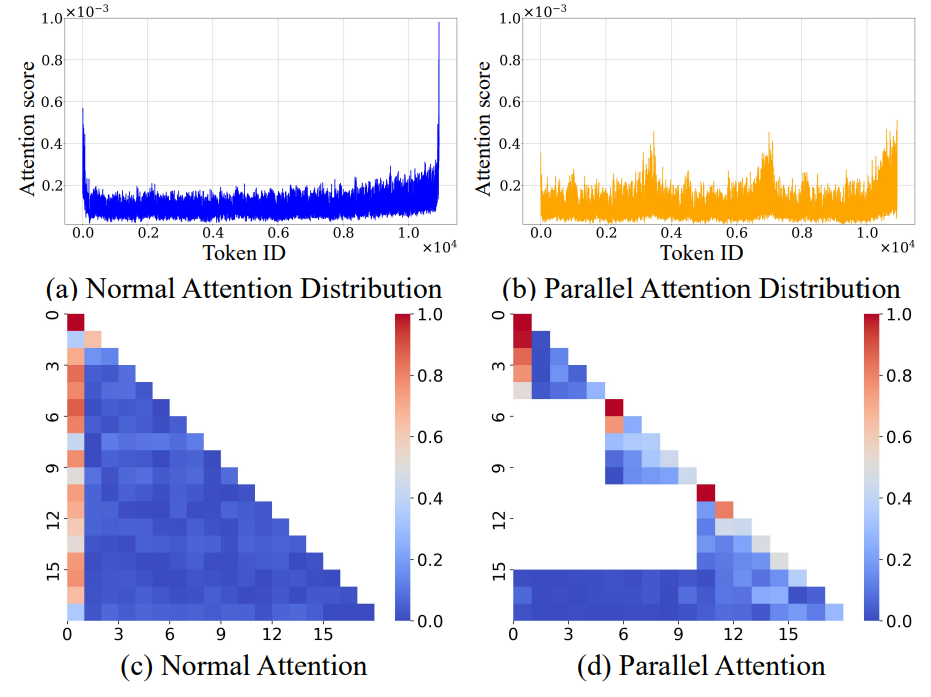
图 1: 标准 Attention 和并行 Attention 机制下的注意力分布虽然有所不同,但都容易陷入这种 “塌缩” 状态。而并行注意力机制在极长文本中产生的多峰新型 “sink” 现象,尚缺乏系统剖析与有效解决之道。
我们的创新:ParallelComp,高效超长文本推理新范式
针对上述问题,我们提出了一种全新的训练免调(Training-Free)长文本处理方案 ——ParallelComp,其核心包括并行 Attention 分块、KV 缓存智能淘汰与注意力偏差校准三大技术创新。

-
论文标题:ParallelComp: Parallel Long-Context Compressor for Length Extrapolation
-
论文链接: https://arxiv.org/abs/2502.14317
-
代码链接: https://github.com/menik1126/ParallelComp
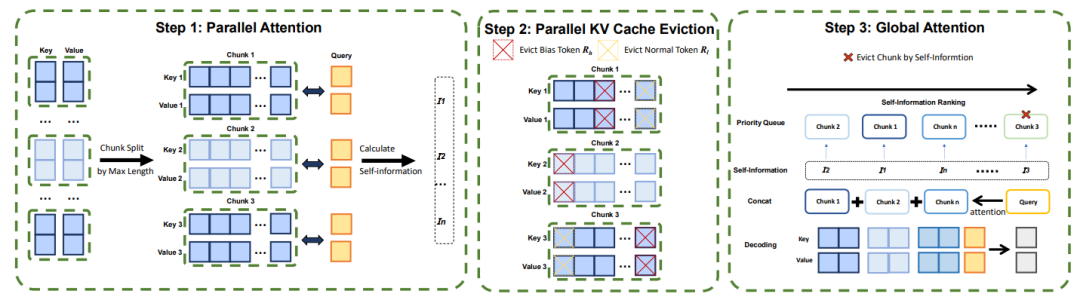
图 2:ParallelComp 整体流程示意图
1. 并行分块注意力,让超长文本 “轻松分段消化”
首先,ParallelComp 借鉴并拓展了分块思想,将输入长文本按模型最大处理长度自动切分为若干块(chunk),并与查询一起并行输入模型进行本地 Attention 计算。这样不仅可以获得块内的注意力分布,还可以通过块的位置编码重用机制可以让模型灵活外推至 128K 级别的序列长度而性能无明显损失。(见图 2)
2. 双重淘汰机制,极致压缩显存消耗
-
分块淘汰(Chunk Eviction): 基于每个块内部 token 对查询的 “自信息量” 进行在线打分,仅保留信息量最高、对当前任务最相关的一部分文本块,极大缩减内存开销。
-
KV 缓存淘汰(Parallel KV Cache Eviction): 采用高效的 FlashAttention 推断算法,动态评估每个 token 在 Attention 计算中的全局重要性,自动驱逐影响较小的 token,实现了分块粒度的 KV 缓存智能压缩。
通过这两项机制,全流程推理所需显存可以压缩到 64G,且基于并行预填充过程即可完成高达 128K 长度推理任务,显著提升 Batch inference 和多 GPU 设置下的推理效率。
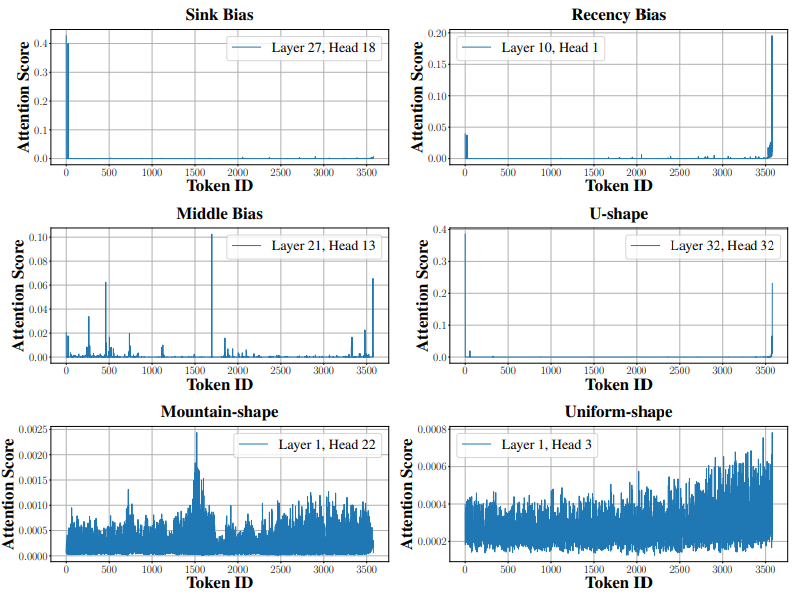
图 3:三类典型注意力偏置分布案例(U 型、山峰型、均匀型)
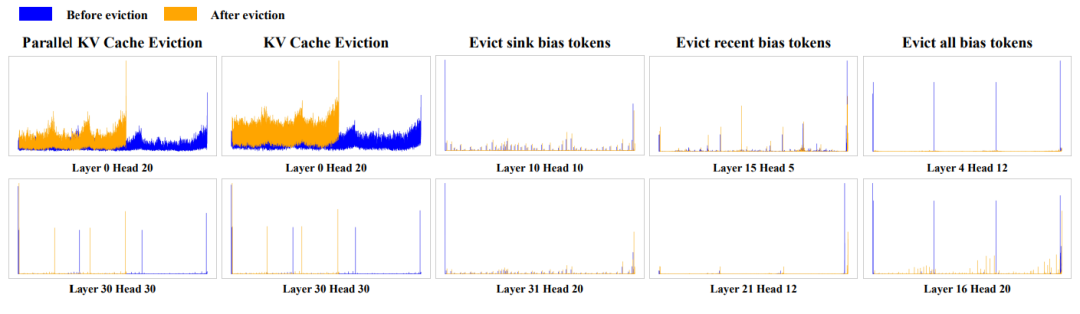
图 4: 几种 KV cache 驱逐策略后的模型的分布
3. 注意力偏差校准,攻克并行下的多峰 “sink” 现象
通过理论分析与大量可视化实证,我们发现并行分块机制下,不同于经典的 U 型 Attention Sink,容易出现多峰、区域性异常(见图 3、图 4)。为此,我们提出在 Attention 分布中对异常高分 token 实施 “偏差校准”—— 分层驱逐被极端关注的 token,使 Attention 分布趋于平滑,极大降低了模型关注 “死角” 和信息遗漏风险。
进一步的分层实验揭示,不同类型注意力偏差(“首段偏置”“尾段偏置”“中部塌缩”)可分别通过不同深度层的 token 淘汰策略加以缓解,为长文本推理设计提供了细致化的实操指引。
一个有趣的观察是有些特定层的注意力偏差对模型的上下文学习能力和推理能力至关重要。
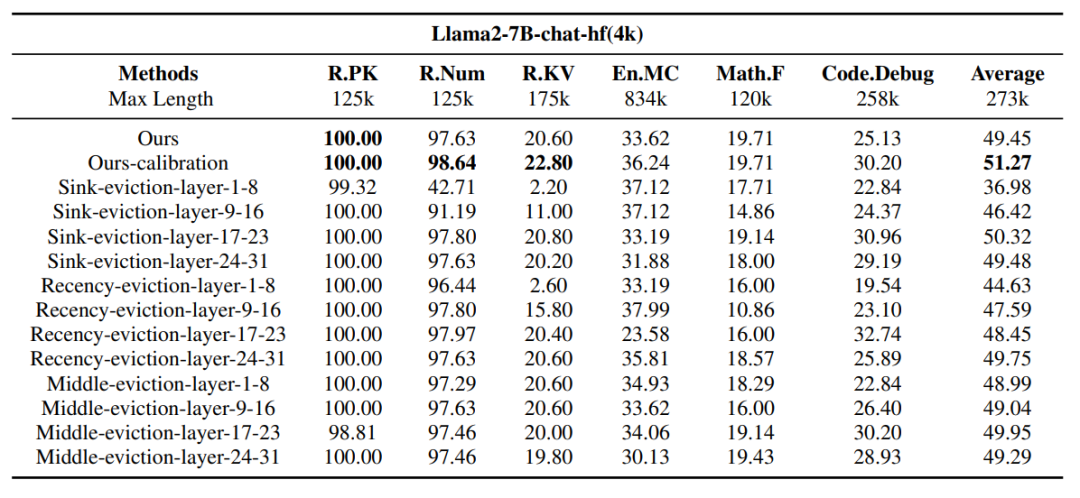
表 1 : 不同层的 bias token 对特定任务的影响
i) 浅层(第 1-8 层)的首段偏置对于检索类任务至关重要。去除这些 token 会显著削弱模型性能。
ii) 深层(第 9-16 层)的尾段偏置在模型推理能力中起到关键作用。淘汰这些 token 会导致编码和数学任务的性能下降。
iii) 浅层的中部偏置(第 1-8 层)会损害模型的理解能力,淘汰这些 token 反而能够提升模型表现。而深层的中部偏置(第 24-31 层)有助于模型在阅读理解任务(如 En.MC)中的能力,去除它们会降低模型表现。
iv) 早期层(第 1-8 层)的尾段偏置对于模型的上下文学习能力同样非常重要。
理论与实验分析
我们的理论分析表明,并行 Attention 下 “稀疏性” 与 “有效信息量” 之间存在量化可控的门槛。随着 chunk 数量增多和长度变长,Attention 大概率只会专注于极少数 token。合理选择稀疏参数、分层校准策略,可在计算效率与信息保真度之间取得最优平衡。
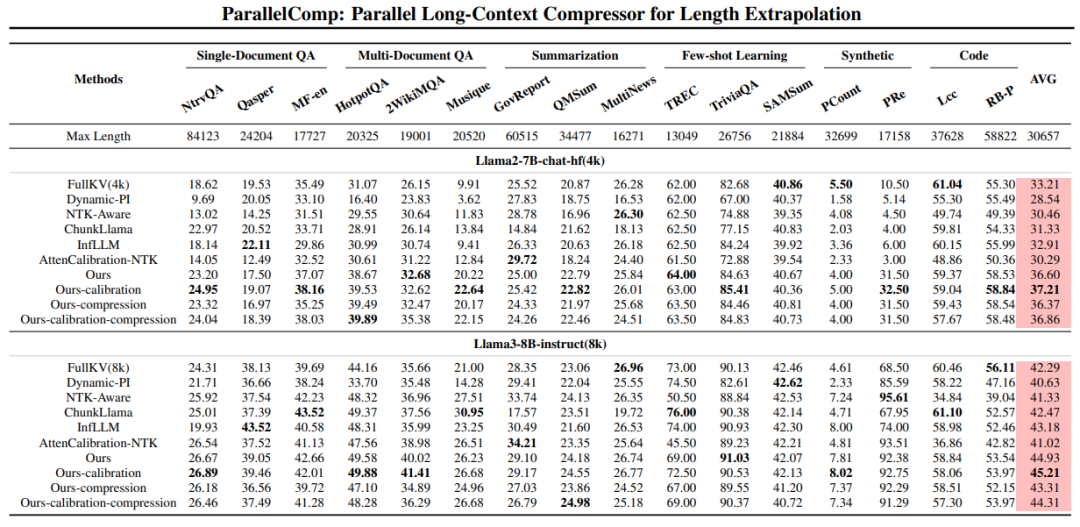
表 2: 在 longbench 上的性能。

表 3: 在 infinitebench 上的性能。
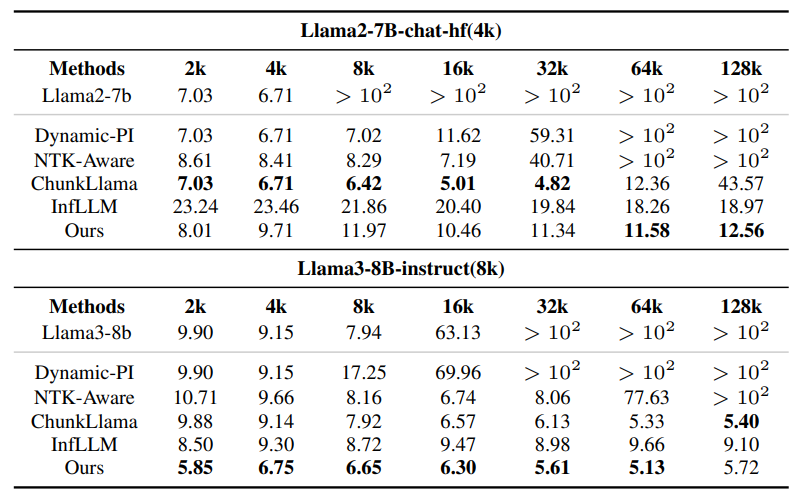
表 4: PPL 的性能
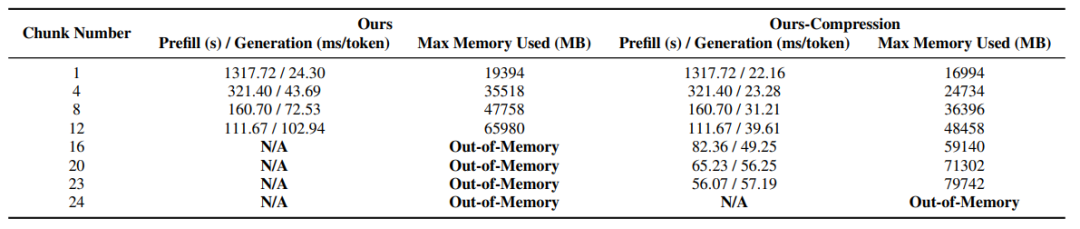
表 5: 加速比和性能分析
大规模实验显示,ParallelComp 在 A100-80GB 单卡环境中,模型推理长度从 8K 无缝外推至 128K,prefilling 阶段加速高达 23.5 倍;使用仅 8B 参数、且仅在 8K 上下文训练的小模型即可在超长文本任务中整体性能达到 GPT-4o 性能的 91.17% , 在特定任务下可以超过GPT-4o的性能,甚至超过 Claude-2 和 Kimi-Chat 等高参数闭源大模型。这一成果充分证明,我们的方法不仅适用于算力受限场景,更为 LLM 实际落地部署带来了崭新范式。
结论与展望
ParallelComp 为长文本推理时代的 LLM 结构创新带来了 “多快好省” 的系统级跃升 —— 无需新训练、仅借助智能分块和淘汰机制,即可极大提升处理长度、效率,并摆脱原有的注意力失衡难题。我们期待该方法未来在法律文档、医学文献、长篇小说等需求复杂的产业应用中进一步开花结果。

©
(文:机器之心)