


本文由中国人民大学高瓴人工智能学院李崇轩团队和字节跳动Seed团队共同完成。第一作者郑晨宇是中国人民大学高瓴人工智能学院二年级博士生,主要研究方向为基础模型的优化、泛化和可扩展性理论,导师为李崇轩副教授,论文为其在字节跳动Seed实习期间完成。第二作者张新雨是字节跳动研究员,主要研究方向为视觉生成模型。李崇轩副教授为唯一通讯作者。
近年来,diffusion Transformers已经成为了现代视觉生成模型的主干网络。随着数据量和任务复杂度的进一步增加,diffusion Transformers的规模也在快速增长。然而在模型进一步扩大的过程中,如何调得较好的超参(如学习率)已经成为了一个巨大的问题,阻碍了大规模diffusion Transformers释放其全部的潜能。
为此,人大高瓴李崇轩团队和字节跳动Seed团队的研究员引入了大语言模型训练中的μP理论,并将其扩展到diffusion Transformers的训练中。μP通过调整网络不同模块的初始化和学习率,实现不同大小diffusion Transformers共享最优的超参,使得小模型上搜到的超参可以直接迁移到最终大模型上进行训练,从而极大地减小了超参搜索的耗费。
团队在DiT,PixArt和MMDiT(Stable Diffusion的基座)上进行了系统的大规模实验验证。在MMDiT的实验中,0.18B小模型上搜得的超参成功被用在18B大模型的训练中,并击败了人工专家的手调基线。其中,小模型超参搜索的计算量(FLOPs)仅是专家手调的3%左右。
团队已在近期开放在线论文,并开源代码。

-
论文链接:
https://arxiv.org/abs/2505.15270
-
代码仓库:
https://github.com/ML-GSAI/Scaling-Diffusion-Transformers-muP
μP的背景和问题
μP全称为最大更新参数化(Maximal Update Parametrization),是Tensor Program无穷宽网络理论系列中的里程碑之作,相关结果已被理论证明适用于标准的Transformer架构。μP的算法实现简洁,对于应用最为广泛的AdamW优化器而言,μP只需要调整隐藏层权重的学习率,和输出层权重的系数以及初始化。μP在实际中被广泛发现能够实现不同大小的标准Transformer共享最优的超参,使得小模型上搜到的超参可以直接迁移到大模型,极大地减小了超参搜索的耗费。由于μP带来了稳定的超参迁移性质,它近年来已经被成功使用在大语言模型(标准Transformer)的预训练中。
然而,diffusion Transformers和标准Transformer存在较大的差异。从架构上来看,diffusion Transformers引入了额外的模块来处理并整合文本信息,如DiT中的adaLN block。从任务目标上来看,diffusion Transformers处理的是视觉的扩散学习任务,而标准Transformer主要处理的是语言的自回归学习任务。这两点差异意味着已有的μP形式及其超参迁移律在视觉diffusion Transformers中不一定成立。针对这一问题,团队从理论和实践上进行了系统的研究。
Diffusion Transformers的μP形式
团队首先从理论上研究了主流diffusion Transformers的μP形式,包括DiT,U-ViT,PixArt-α和MMDiT。Tensor Program理论系列中的结果表明,如果网络架构能够被Tensor Program中定义的算子表示,那么现有的μP形式就能成立。基于这个理论技术,我们证明了:即使主流diffusion Transformers的结构不同于标准Transformer,它们也能够被Tensor Program表示,因此现有的μP理论和相关实践可以被无痛迁移到这些主流diffusion Transformers上。我们的证明技术也可以被迁移到其它的diffusion Transformers做类似的分析。
总之,diffusion Transformers的μP方法论可以由下图总结。我们首先基于μP理论,调节不同权重的系数、初始化和学习率。然后,我们在一系列小模型上搜索得到最优的超参。最后,我们将最优的超参直接迁移到大模型的训练。
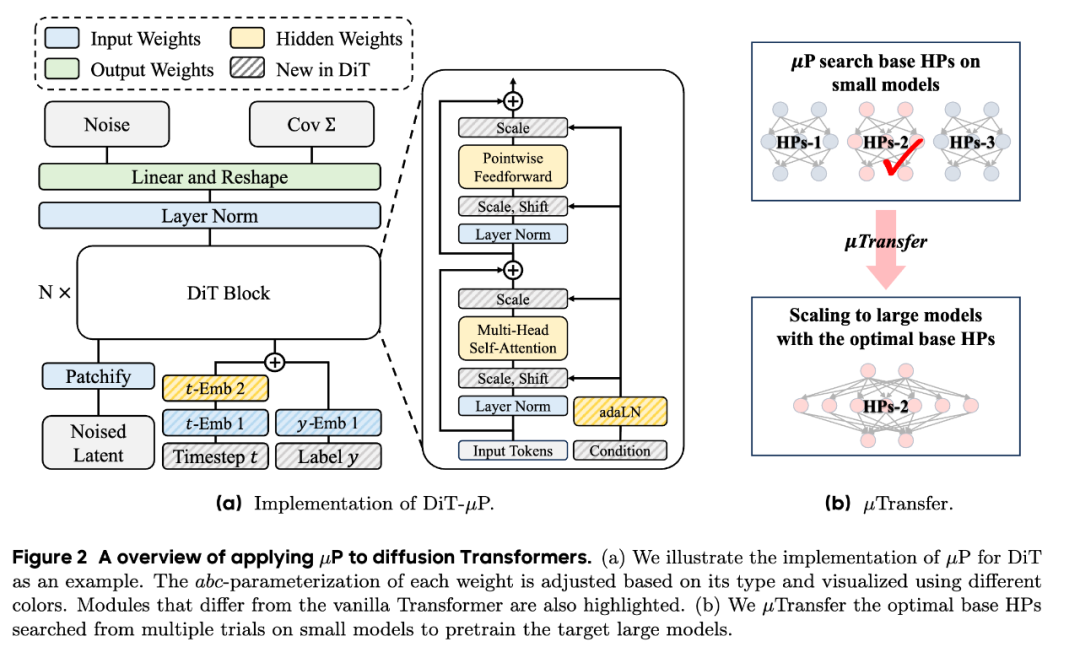
基于μP扩展Diffusion Transformers:初探
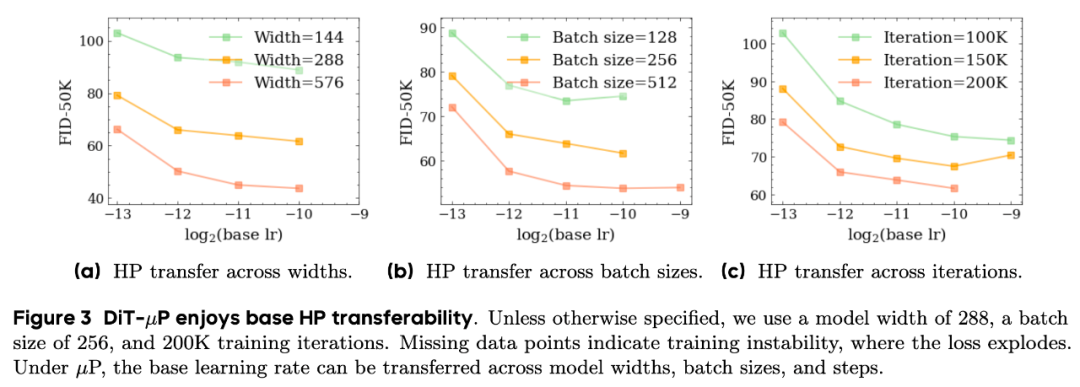
首先,我们使用DiT网络在ImageNet数据集上系统地验证了:当网络宽度,数据批量大小和训练步数足够大时(如宽度达到144,批量大小达到256),超参便可以较为稳定地沿着不同的网络宽度,数据批量大小和训练步数进行迁移。这意味着我们能在网络宽度,数据批量大小和训练步数都更小的代理任务上搜索超参,然后迁移到最终大网络大数据的训练。
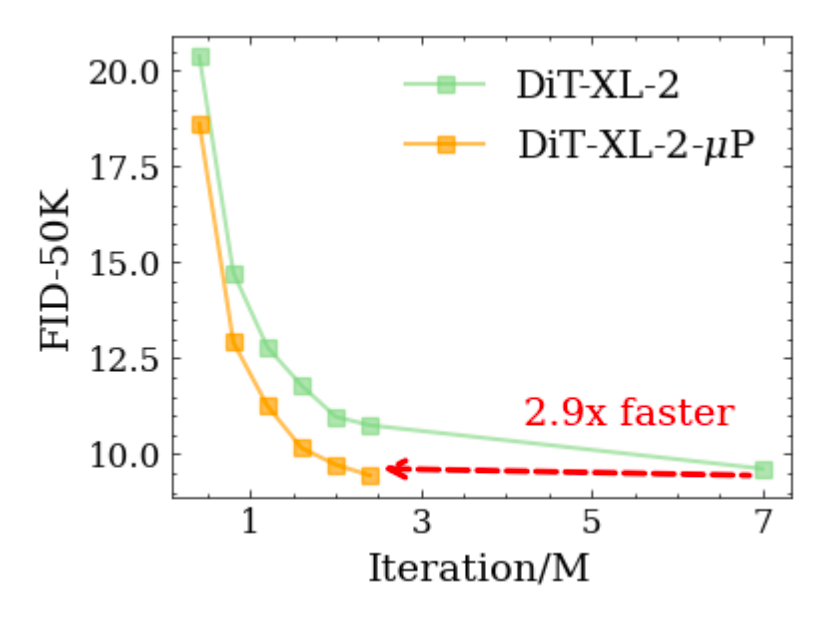
然后,为了验证μP超参迁移的有效性,我们将最优的超参(学习率2^-10)直接迁移到DiT-XL-2的训练中,我们发现,当模型训练到2.4M步时,FID-50K就已经超过了原论文7M步最终的FID-50K结果,DiT-XL-2-μP的收敛速度是原论文的2.9倍。这向我们展现了利用μP迁移超参做扩展的良好前景。
基于μP扩展Diffusion Transformers:大规模验证
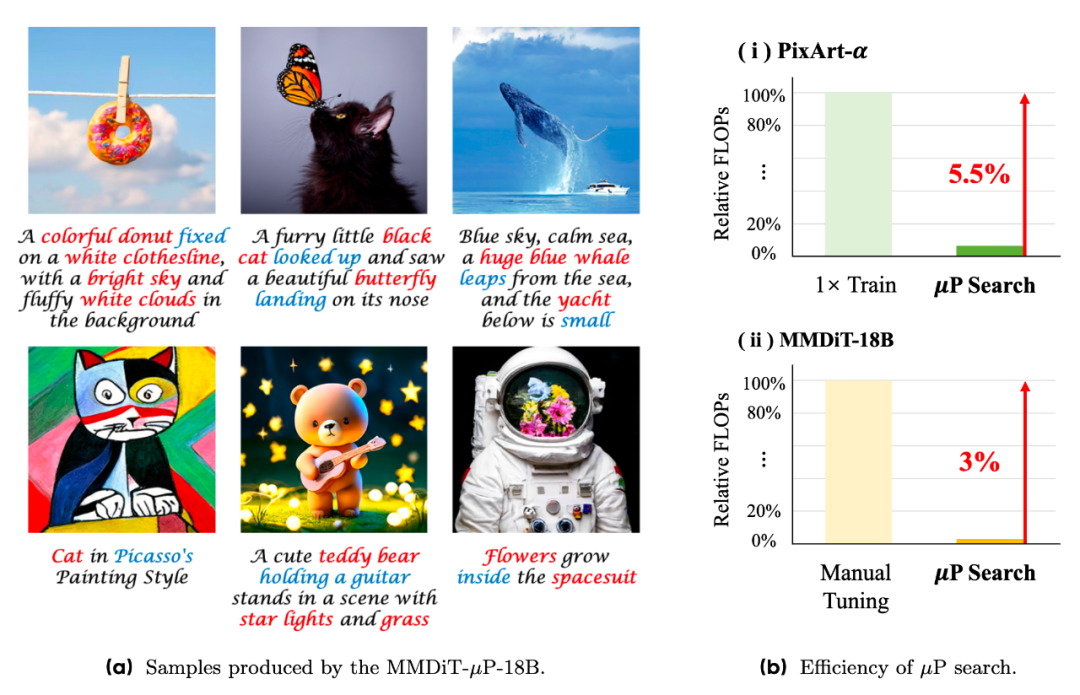
我们进一步在大规模的文生图任务上验证了μP扩展diffusion Transformers的有效性。我们首先考虑了流行的开源文生图模型PixArt-α,我们在0.04B的代理模型上搜索学习率,并迁移到最终0.61B大小PixArt-α的训练。其中,小模型搜索超参的计算量总和(FLOPs)仅为一次训练的5.5%。利用搜索得到的学习率,PixArt-α–μP在训练的过程中稳定地取得了比基线更好的效果。
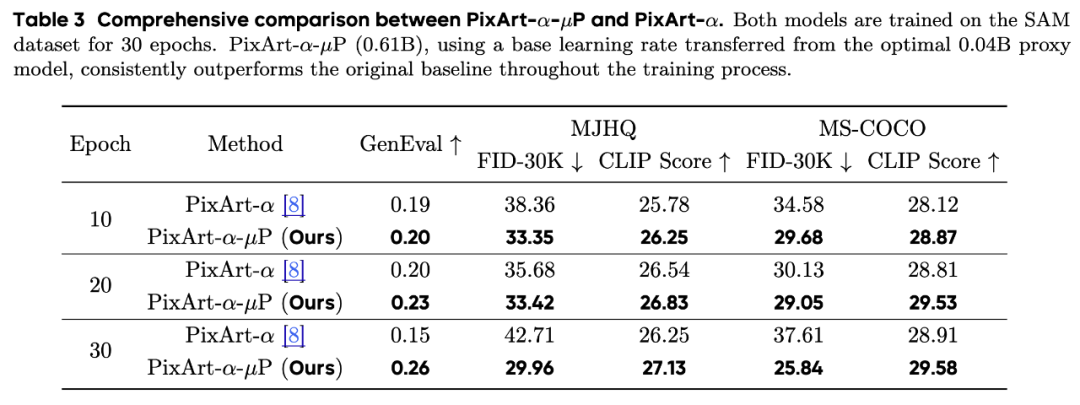
最后,我们考虑了SD3的基座模型MMDiT,并将验证的规模提高到了18B的量级。为了能够给社区带来更多的可信的实践经验,我们在 4个超参(学习率,梯度裁剪值,REPA loss的权重以及warmup的步数)上进行了多达80次的随机搜索,总搜索计算量(FLOPs)约是人工手调的3%。在0.18B模型上的超参搜索结果表明,我们学习率,梯度裁剪值,REPA loss都对结果有影响,其中学习率的影响仍是最为关键的。而warmup的步数则对结果影响不大。
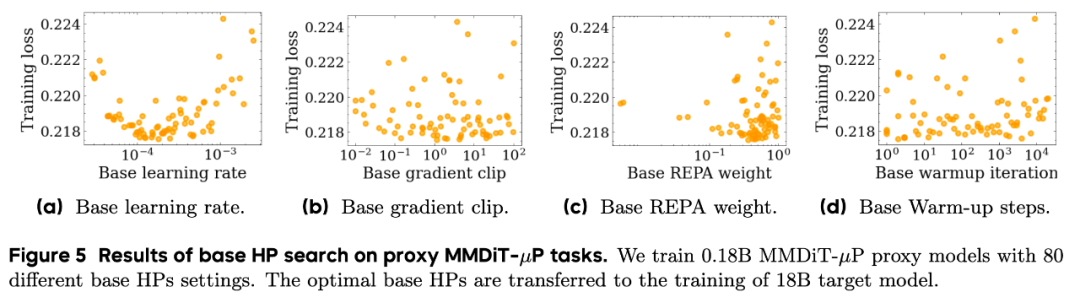
我们将0.18B模型上搜索的超参应用在了18B模型的训练上,不论从训练loss的变化还是从人工评测的结果,MMDiT-μP都稳定地超过了人工专家手调的基线,而μP的超参搜索FLOPs仅是人工手调的3%!

经过这一系列系统的实验探索,我们证明了μP是科学扩展diffusion Transformers的有效手段,我们也相信μP会是未来基础模型扩展的必备利器。通过本工作的大量努力,我们希望让社区了解μP理论,拥抱μP实践,思考理论上最优的智能扩展范式(模型大小,数据量,推理时间)。我们也相信,放眼人工智能的长远未来,类似μP的底层理论的发展仍然是必不可少的,也必将会在未来的大规模实践中有着不可或缺的一席之地。

©
(文:机器之心)