

Stream-Omni 是中国科学院计算技术研究所、中国科学院人工智能安全重点实验室及中国科学院大学联合推出的类似 GPT-4o 的大型语言–视觉–语音模型,能够同时支持文本、图像和语音等多种模态的交互。
 一、项目概述
一、项目概述
Stream-Omni 是一个基于大型语言模型(LLM)的多模态交互模型,能够同时处理文本、图像和语音三种模态的输入,并生成相应的文本和语音输出。该模型通过序列维度拼接和层维度映射的方式,实现了视觉与文本的对齐,以及语音与文本的对齐,从而在视觉理解、语音交互和视觉引导的语音交互任务上表现出色。Stream-Omni 的训练仅需少量全模态数据,训练效率高,适合在资源有限的环境中部署。
二、技术原理
1. 基于 LLM 的骨干架构
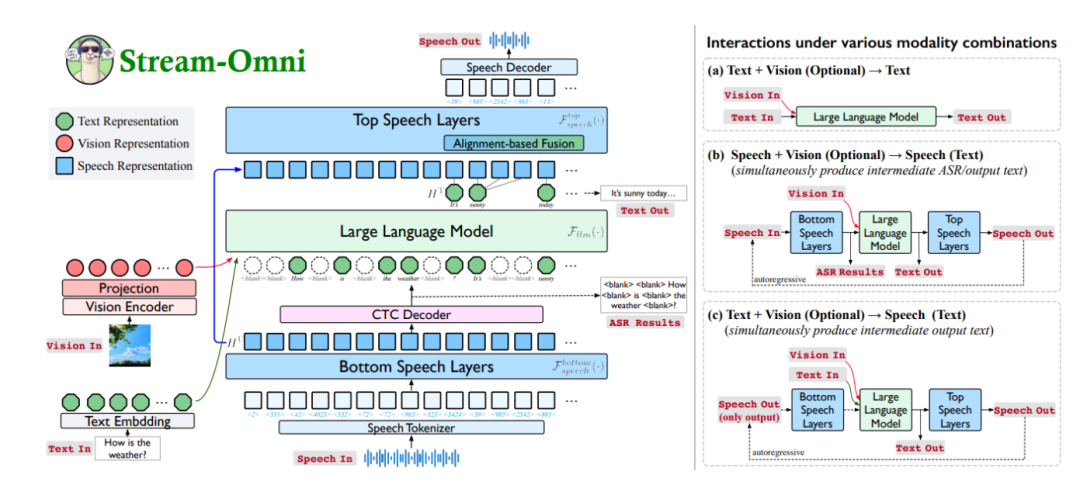
Stream-Omni 的核心是基于大型语言模型(LLM)的骨干架构。LLM 作为模型的核心,提供了强大的语言理解和生成能力,为多模态交互提供了基础支持。通过将 LLM 与视觉和语音模态进行对齐,Stream-Omni 实现了跨模态的交互能力。
2. 视觉文本对齐
为了实现视觉与文本的对齐,Stream-Omni 使用序列维度拼接的方式,将视觉编码器提取的视觉特征与文本输入进行拼接,再共同输入到 LLM 中,实现视觉和文本模态的对齐。这种方式使得模型能够更好地理解图像内容,并生成与之相关的文本信息。
3. 语音文本对齐
对于语音与文本的对齐,Stream-Omni 引入了基于 CTC(Connectionist Temporal Classification)的层维度映射。在 LLM 的底部和顶部添加语音层,实现语音到文本的映射和文本到语音的生成,从而将语音模态与文本模态对齐。这种对齐方式使得模型能够在语音交互过程中实时生成语音输出,提供流畅的交互体验。
4. 多任务学习
Stream-Omni 采用多任务学习策略,同时训练视觉文本、语音文本及全模态(视觉+文本+语音)的任务,让模型更好地理解和生成多模态内容。这种策略不仅提高了模型的泛化能力,还增强了其在不同任务上的适应性。
5. 实时语音生成
基于特殊的语音层设计和层维度映射,Stream-Omni 在生成文本的同时,实时生成对应的语音输出,实现流畅的语音交互。这种能力使得用户在语音交互过程中能够同时看到文本和听到语音,从而获得更全面的交互体验。
6. 数据驱动与监督学习结合
Stream-Omni 依赖少量多模态数据进行训练,基于精心设计的对齐机制和多任务学习,能在有限的数据上实现高效的模态对齐和交互能力。这种设计使得模型在数据稀缺的情况下仍能保持良好的性能。
三、主要功能
1. 多模态输入与输出
Stream-Omni 支持文本、图像和语音等多种模态的输入,并能同时生成文本和语音输出。这种能力使得模型能够处理复杂的多模态交互任务,满足不同场景下的需求。
2. 无缝“边听边看”体验
在语音交互过程中,Stream-Omni 能实时输出中间文本结果(如自动语音识别 ASR 转录和模型响应),为用户提供更丰富的交互体验。这种无缝的交互体验类似于 GPT-4o 的高级语音服务,提升了用户的交互满意度。
3. 高效训练
Stream-Omni 仅需少量全模态数据(如 23000 小时语音数据)进行训练,对数据需求量小,训练效率高。这种高效训练能力使得模型能够在资源有限的环境中快速部署和使用。
4. 灵活的交互模式
Stream-Omni 支持多种模态组合的交互,包括文本+视觉→文本、文本+视觉→语音、语音+视觉→文本、语音+视觉→语音等,满足不同场景下的交互需求。这种灵活性使得模型能够适应各种应用场景,提高其适用性。
5. 视觉理解与语音交互
Stream-Omni 在视觉理解任务和语音交互任务上表现出色,能准确理解和生成与视觉内容相关的文本和语音信息。这种能力使得模型在智能车载系统、教育辅助工具、智能家居控制、医疗辅助诊断和智能客服服务等多个领域具有广泛的应用前景。
四、评测结果
1. 视觉理解能力
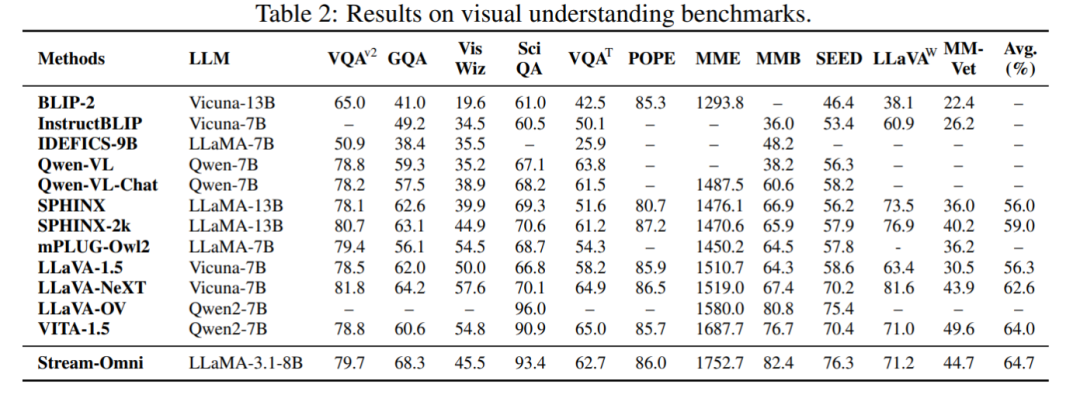
在多个视觉理解基准测试中,Stream-Omni 表现出色。例如,在 VQA-v2、GQA、VizWiz、ScienceQA-IMG、TextVQA、POPE、MME、MMBench、SEED-Bench 和 LLaVA-Bench-in-the-Wild 等基准测试中,Stream-Omni 的性能接近或超越了最先进的视觉导向 LMMs,如 LLaVA、BLIP-2、InstructBLIP、Qwen-VL、SPHINX 和 mPLUG-Owl2 等。
2. 语音交互能力
在语音交互任务中,Stream-Omni 也表现出色。在 Llama Questions 和 Web Questions 等基准测试中,Stream-Omni 的准确率分别为 76.3% 和 65.0%,在语音到文本(S→T)和语音到语音(S→S)任务中均优于其他模型。此外,Stream-Omni 在语音识别任务中的 WER(Word Error Rate)也优于其他模型,如 Whisper、SpeechGPT、Moshi、Mini-Omni、Freeze-Omni 和 GLM-4-Voice 等。
3. 视觉引导的语音交互能力
在视觉引导的语音交互任务中,Stream-Omni 也表现出色。在 SpokenVisIT 基准测试中,Stream-Omni 的评分分别为 3.93 分(视觉+文本→文本)和 3.68 分(视觉+语音→文本),在语音生成任务中也表现出色。这种能力使得模型在真实世界中能够更好地理解和生成语音信息。
4. 语音–文本映射质量
在语音–文本映射任务中,Stream-Omni 的表现也优于其他模型。在 LibriSpeech 基准测试中,Stream-Omni 的 WER 为 3.0%,在语音识别任务中的推理时间也优于其他模型。这种高质量的映射能力使得模型在语音交互任务中能够提供更准确的语音输出。
五、应用场景
1. 智能车载系统
在智能车载系统中,司机可以通过语音指令查询路线、获取路况,系统结合视觉信息(如导航地图、路况摄像头图像)实时显示文本提示和语音反馈,提升驾驶安全性和交互效率。
2. 教育辅助工具
在教育场景中,学生可以通过语音提问,系统依据教材视觉内容(如图表、图片)给出详细文本解释和语音回答,帮助学生更好地理解和学习知识。
3. 智能家居控制
作为智能家居助手,用户可以通过语音指令控制家电设备,系统结合视觉输入(如摄像头捕捉的环境信息)提供文本或语音反馈,实现更智能、便捷的家居控制。
4. 医疗辅助诊断
在医疗场景中,医生可以通过语音指令查询关键信息,系统结合视觉报告(如X 光片、CT 图像)提供详细的文本分析和语音解释,辅助医生更准确地做出诊断。
5. 智能客服服务
在客服领域,客服人员可以通过语音与客户交流,系统实时显示相关文本信息和视觉提示(如产品图片、操作流程图),帮助客服人员快速理解客户需求并提供准确解答,提升服务质量和效率。
六、快速使用
1. 模型下载
1)从这里下载 Stream-Omni 模型,放入 ${STREAMOMNI_CKPT} 。
https://huggingface.co/ICTNLP/stream-omni-8b
2)从这里下载 CosyVoice(分词器 & 流模型),放入 COSYVOICE_CKPT=./CosyVoice-300M-25Hz :
https://modelscope.cn/models/iic/CosyVoice-300M-25Hz/files
2. 安装依赖
conda create -n streamomni python=3.10 -yconda activate streamomnipip install -e .pip install flash-attn --no-build-isolationpip install -r requirements.txtpip install -r CosyVoice/requirements.txt
3. 命令交互
运行这些脚本以进行基于视觉的语音交互:
export CUDA_VISIBLE_DEVICES=0export PYTHONPATH=CosyVoice/third_party/Matcha-TTSSTREAMOMNI_CKPT=path_to_stream-omni-8b# Replace the path of cosyvoice model in run_stream_omni.py (e.g., cosyvoice = CosyVoiceModel('./CosyVoice-300M-25Hz'))# add --load-8bit for VRAM lower than 32GBpython ./stream_omni/eval/run_stream_omni.py \--model-path ${STREAMOMNI_CKPT} \--image-file ./stream_omni/serve/examples/cat.jpg --conv-mode stream_omni_llama_3_1 --model-name stream-omni \--query ./stream_omni/serve/examples/cat_color.wav
你应该得到以下输出:
ASR Outputs:What is the color of the catLLM Outputs:The cat is gray and black.Speech Tokens:<Audio_2164><Audio_2247><Audio_671><Audio_246><Audio_2172><Audio_1406><Audio_119><Audio_203><Audio_2858><Audio_2099><Audio_1716><Audio_22><Audio_1736><Audio_1038><Audio_4082><Audio_1655><Audio_2409><Audio_2104><Audio_571><Audio_2255><Audio_73><Audio_760><Audio_822><Audio_701><Audio_2583><Audio_1038><Audio_2203><Audio_1185><Audio_2103><Audio_1718><Audio_2610><Audio_1883><Audio_16><Audio_792><Audio_8><Audio_8><Audio_535><Audio_67>Speech Outputs:Audio saved at ./output_893af1597afe2551d76c37a75c813b16.wav
七、结语
Stream-Omni 是一个强大的多模态交互模型,能够同时处理文本、图像和语音等多种模态的输入,并生成相应的文本和语音输出。其灵活的交互模式、高效的训练策略和广泛的应用场景,使其在智能车载系统、教育辅助工具、智能家居控制、医疗辅助诊断和智能客服服务等多个领域具有广泛的应用前景。
项目资料
论文地址:https://arxiv.org/pdf/2506.13642
GitHub仓库:https://github.com/ictnlp/Stream-Omni
(文:小兵的AI视界)