

机器之心编辑部
这两天 Andrej Karpathy 的最新演讲在 AI 社区引发了热烈讨论,他提出了「软件 3.0」的概念,自然语言正在成为新的编程接口,而 AI 模型负责执行具体任务。

Karpathy 深入探讨了这一变革对开发者、用户以及软件设计理念的深远影响。他认为,我们不只是在使用新工具,更是在构建一种全新的计算范式。
回顾 LLM 的发展历程:自 2017 年 Transformer 架构问世以来,我们见证了 GPT 系列的一路高歌猛进,以及多模态能力和端侧应用的全面开花。整个领域正以前所未有的速度演进。
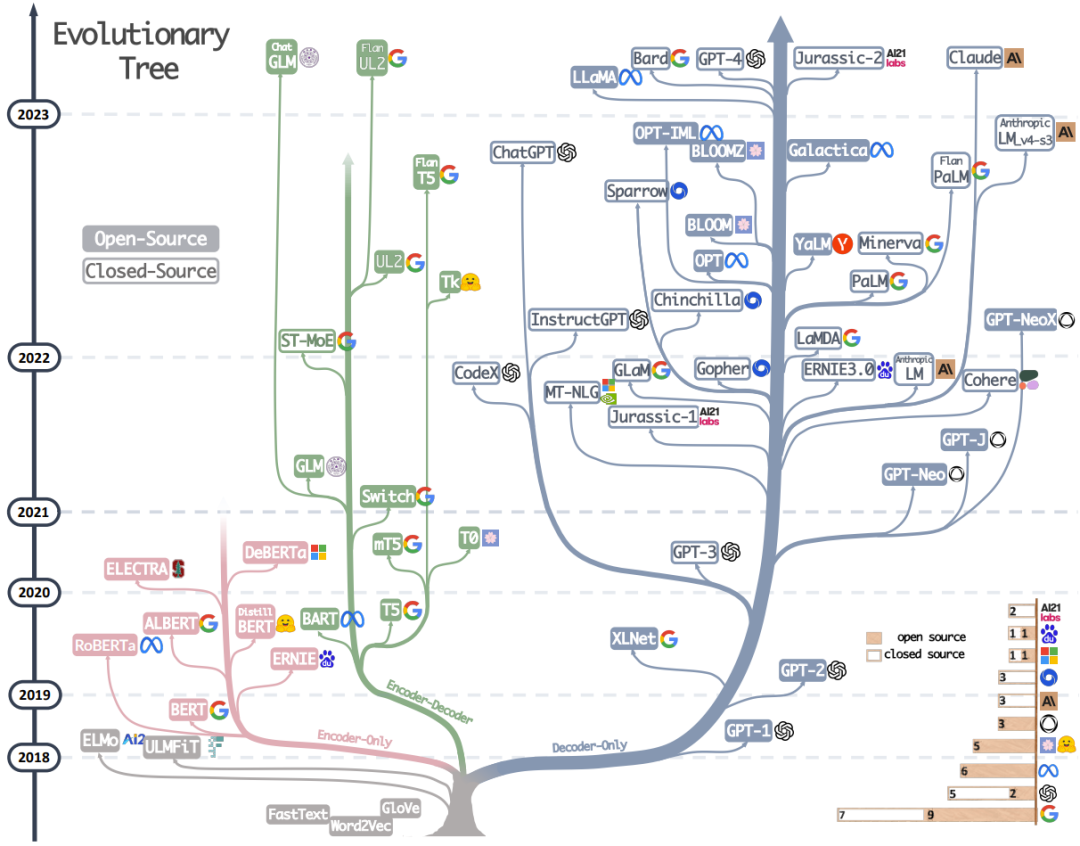
要深入理解这场变革的本质,我们需要回到技术的源头。那些奠定今天 AI 能力的关键论文,不仅记录着算法的演进轨迹,更揭示了从传统编程到自然语言交互这一范式转变的内在逻辑。
此前我们通过 50 个核心问题回顾了 LLM 的基础概念。今天,我们将梳理自 2017 年以来 LLM 领域的重要论文。本文从 X 用户 Pramod Goyal 的论文盘点中精选了 22 篇进行详细介绍,其余论文将在文末列出供读者参考。

奠基理论
-
Attention Is All You Need (2017)

链接:https://arxiv.org/pdf/1706.03762
主要内容:提出了 Transformer 架构,它完全摒弃了传统的循环和卷积网络,仅依靠自注意力机制来处理序列数据。通过并行计算和位置编码,它能高效捕捉长距离的依赖关系,以更快的速度和更高的质量完成机器翻译等任务。
影响:Transformer 架构是现代 AI 的基石,直接催生了 GPT 和 BERT 等 LLM,并引发了当前的 AI 热潮。它的高效和通用性使其不仅彻底改变了自然语言处理,还被成功应用于计算机视觉等多个领域,成为一项革命性的技术。
-
Language Models are Few-Shot Learners (2020)
论文地址:https://arxiv.org/abs/2005.14165
主要内容:介绍并验证了拥有 1750 亿参数的自回归语言模型 GPT-3 的强大能力。研究表明,与以往需要针对特定任务进行大量数据微调的模型不同,GPT-3 无需更新权重,仅通过在输入时提供任务描述和少量示例(即「少样本学习」或「上下文学习」),就能在翻译、问答、文本生成乃至代码编写等大量不同的自然语言处理任务上取得极具竞争力的表现,且模型性能随着参数规模的增长和示例数量的增加而稳定提升。
影响:确立了「大模型 + 大数据」的缩放定律 (Scaling Law) 是通往更通用人工智能的有效路径,直接引领了全球范围内的 LLM 军备竞赛。同时,它开创了以「提示工程」为核心的新型 AI 应用范式,极大地降低了 AI 技术的开发门槛,并催生了后续以 ChatGPT 为代表的生成式 AI 浪潮,深刻地改变了科技产业的格局和未来走向。
-
Deep Reinforcement Learning from Human Preferences (2017)

论文地址:https://arxiv.org/abs/1706.03741
主要内容:该论文开创性地提出,不再手动设计复杂的奖励函数,而是直接从人类的偏好中学习。其核心方法是:收集人类对 AI 行为片段的成对比较(「哪个更好?」),用这些数据训练一个「奖励模型」来模仿人类的判断标准,最后用这个模型作为奖励信号,通过强化学习来训练 AI。该方法被证明仅需少量人类反馈即可高效解决复杂任务。
影响:这篇论文是「基于人类反馈的强化学习」(RLHF) 领域的奠基之作。RLHF 后来成为对齐和微调 ChatGPT 等 LLM 的关键技术,通过学习人类偏好,使 AI 的输出更有用、更符合人类价值观。它将「AI 对齐」从抽象理论变为可行的工程实践,为确保 AI 系统与人类意图一致提供了可扩展的解决方案,是现代对话式 AI 发展的基石。
-
Training language models to follow instructions with human feedback (2022)

主要内容:该论文提出了一种结合人类反馈的强化学习方法 (RLHF) 来训练语言模型,使其更好地遵循用户的指令。具体步骤包括:首先,使用少量人工编写的示例对预训练的 GPT-3 进行微调;然后,收集人类对模型不同输出的偏好排序数据,并用这些数据训练一个「奖励模型」;最后,利用这个奖励模型作为强化学习的信号,进一步优化语言模型。通过这种方式,即使模型参数比 GPT-3 小得多,InstructGPT 在遵循指令方面也表现得更出色、更真实,且有害内容生成更少。
影响:催生了现象级产品 ChatGPT,并为 LLM 的发展确立了新的技术路线。它证明了通过人类反馈进行对齐 (Alignment) 是解决大型模型「说胡话」、不听指令问题的有效途径。此后,RLHF 成为训练主流对话式 AI 和服务型大模型的行业标准,深刻改变了 AI 的研发范式,将研究重点从单纯追求模型规模转向了如何让模型更好地与人类意图对齐。这一方法论的成功,是推动生成式 AI 从纯粹的技术展示走向大规模实际应用的关键一步。
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2019)

论文地址:https://aclanthology.org/N19-1423/
主要内容:该论文提出了 BERT,一个基于 Transformer 的语言表示模型。其核心创新是真正的双向上下文理解,通过创新的「掩码语言模型」(MLM) 预训练任务,让模型能同时利用一个词左右两侧的全部语境。这克服了以往单向模型的局限性。BERT 通过在海量文本上预训练,再针对具体任务微调的范式,极大地提升了语言理解能力。
影响:BERT 的发布是 NLP 领域的革命,它在 11 项主流任务上刷新了最高分纪录,确立了「预训练 + 微调」作为行业标准范式。它极大地简化了为特定任务构建高性能模型的流程,减少了对复杂定制架构的需求。BERT 开启了现代 LLM 的新纪元,成为后续无数模型的基础。
-
Training Compute-Optimal Large Language Models (2022)

论文地址:https://arxiv.org/abs/2203.15556
主要内容:这篇由 DeepMind 发表的论文(通常被称为「Chinchilla 论文」)挑战了当时「模型越大越好」的普遍认知。通过对超过 400 个模型的系统性训练和分析,研究者发现,现有的 LLM 普遍处于「训练不足」的状态。为了在给定的计算预算下达到最佳性能,模型的大小和训练数据的规模应该同步增长。具体来说,模型参数每增加一倍,训练数据的量也应相应增加一倍。这揭示了一个新的、更高效的「计算最优」缩放法则,颠覆了以往只侧重于增加模型参数的策略。
影响:改变了之后 LLM 的研发方向和资源分配策略。它提出的「计算最优」缩放法则,成为了业界训练新模型时遵循的黄金准则。在此之前,各大机构竞相追求更大的模型规模,而「Chinchilla」证明了在同等计算成本下,一个参数量更小但用更多数据训练的模型(如其 700 亿参数的 Chinchilla 模型)可以优于参数量更大的模型(如 GPT-3)。这促使整个领域从单纯追求「大」转向追求「大与多的平衡」,对后续如 LLaMA 等高效模型的诞生起到了关键的指导作用。
里程碑突破
-
GPT-4 Technical Report (2023)

论文地址:https://arxiv.org/abs/2303.08774
主要内容:详细介绍了一个大规模、多模态的语言模型——GPT-4。其核心在于展示了该模型在各类专业和学术基准测试中展现出的「人类水平」的性能。与前代不同,GPT-4 不仅能处理文本,还能接收图像输入并进行理解和推理。报告重点阐述了其深度学习系统的构建、训练方法、安全考量以及通过可预测的「缩放法则」来准确预测最终性能的工程实践。同时,报告也坦诚地指出了模型在事实准确性、幻觉和偏见等方面的局限性。
影响:进一步巩固了大规模基础模型作为通往更强人工智能关键路径的行业共识。GPT-4 所展示的卓越性能,特别是其多模态能力和在复杂推理任务上的突破,迅速成为 AI 技术的新标杆,极大地推动了 AI 在各行业的应用深度和广度。它不仅催生了更多强大的 AI 应用,也促使全球科技界、学术界和政策制定者更加严肃地审视 AI 安全、对齐和伦理挑战,加速了相关防护措施和治理框架的研究与部署。
-
LLaMA:Open and Efficient Foundation Language Models (2023)

主要内容:发布了一系列参数规模从 70 亿到 650 亿不等的语言模型集合——LLaMA。其核心发现是,通过在海量的公开数据集上进行更长时间的训练,一个规模相对较小的模型(如 130 亿参数的 LLaMA 模型)其性能可以超越参数量更大的模型(如 GPT-3)。论文证明了训练数据的规模和质量对于模型性能的决定性作用,并为业界提供了一条在有限算力下训练出高效能模型的全新路径。
影响:LLaMA 的发布对 AI 领域产生了颠覆性的影响。尽管最初其权重并非完全开源,但很快被社区泄露,并催生了 Alpaca、Vicuna 等大量开源微调模型的井喷式发展,极大地推动了 LLM 研究的民主化进程。它让学术界和中小型企业也能参与到大模型的研发与应用中,打破了少数科技巨头的技术垄断,引爆了整个开源 AI 生态的活力与创新。
-
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (2022)

主要内容:提出了一种快速且节省内存的精确注意力算法。它通过融合计算内核、重排计算顺序以及利用 GPU 内存层级(IO 感知)等技术,有效减少了在计算注意力时对高带宽内存 (HBM) 的读写次数。这使得模型在处理长序列时,既能大幅提升计算速度,又能显著降低内存占用,且计算结果与标准注意力完全一致。
影响:FlashAttention 已成为训练和部署 LLM 的行业标准。该技术使得用更少的硬件训练更大、更长的模型成为可能,直接推动了长上下文窗口模型的发展。因其显著的加速和优化效果,它被迅速集成到 PyTorch、Hugging Face 等主流深度学习框架和库中,极大地促进了整个 AI 领域的进步。
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2022)

主要内容:该论文发现,在处理复杂的推理任务(如数学题)时,若引导 LLM 模仿人类的思维过程,先输出一步步的推理「思路链」(Chain-of-Thought),再给出最终答案,其准确率会大幅提升。这种简单的提示技巧,有效激发了模型隐藏的逻辑推理能力。
影响:这项工作开创了「思维链」(CoT) 提示技术,成为提升大模型推理能力最重要和基础的方法之一。它深刻地影响了后续提示工程的发展,并启发了一系列更高级的推理技术,是理解和应用现代 LLM 的基石性研究。
-
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (2023)

主要内容:提出了一种名为「直接偏好优化」(DPO) 的新方法,用于对齐语言模型。它不再需要像传统 RLHF 方法那样,先训练一个独立的奖励模型,再通过强化学习去优化。DPO 直接利用人类偏好数据,通过一个简单的分类目标,就能高效地调整语言模型,使其更符合人类期望。这种方法将复杂的对齐过程简化成了一步式的微调。
影响:DPO 因其简洁性和高效性迅速产生了巨大影响。它大大简化了从人类偏好中学习的训练流程,降低了计算成本和技术门槛,使得更多研究者和开发者能够有效地对齐自己的模型。目前,该方法已被业界广泛采纳,成为许多领先开源模型(如 Zephyr、Tulu 2)进行对齐时所采用的主流技术之一。
-
Scaling Laws for Neural Language Models (2020)

主要内容:系统地研究了神经语言模型的性能与其规模之间的关系。研究发现,模型性能与模型参数量、数据集大小和用于训练的计算量之间存在着平滑的、可预测的幂律关系 (Power Law)。这意味着,当我们在计算资源受限的情况下,可以根据这些「缩放法则」来最优地分配资源,以达到最佳的模型性能,而无需进行昂贵的试错。
影响:为之后的 LLM 研发提供了理论基石和路线图。它明确指出,持续、可预测的性能提升可以通过同步扩大模型、数据和计算量来实现。这直接指导了像 GPT-3、PaLM 等后续超大规模模型的诞生,确立了「暴力缩放」(Scaling) 作为通往更强 AI 能力的核心策略,深刻塑造了当前 AI 领域的军备竞赛格局。
-
Proximal Policy Optimization Algorithms (2017)

论文地址:https://arxiv.org/abs/1707.06347
主要内容:该论文提出 PPO 算法,一种旨在解决强化学习中策略更新不稳定的新方法。其核心创新是「裁剪代理目标函数」,通过将新旧策略的概率比率限制在一个小范围内,来防止过大的、破坏性的策略更新。这种简洁的一阶优化方法在保证训练稳定性的同时,显著提升了数据利用效率,且比 TRPO 等先前算法更易于实现。
影响:PPO 凭借其稳定性、性能和实现简单的完美平衡,已成为强化学习领域的「默认」算法。其最深远的影响是作为核心技术,驱动了「基于人类反馈的强化学习」(RLHF),这使得对齐 ChatGPT 等 LLM 成为可能,确保 AI 更有用、更无害。此外,它在机器人等领域应用广泛,并成为衡量新算法的重要基准。
核心架构与方法
-
Mamba: Linear-Time Sequence Modeling with Selective State Spaces (2023)

论文地址:https://arxiv.org/abs/2312.00752
主要内容:Mamba 是一种新型的序列建模架构,它通过引入一种选择性机制来改进状态空间模型 (SSM)。这使其能根据输入内容动态地压缩和传递信息,从而以与序列长度成线性关系的时间复杂度高效处理超长序列,并在性能上媲美甚至超越了传统的 Transformer 架构。
影响:Mamba 为长序列建模提供了一个区别于 Transformer 的强大新选择,其高效性能迅速激发了学界对状态空间模型的研究热潮。它被视为下一代基础模型架构的有力竞争者,正推动语言模型、基因组学、多模态等领域的底层架构革新,展现出巨大的应用潜力。
-
QLoRA: Efficient Finetuning of Quantized LLMs (2023)

主要内容:提出了一种高效微调量化 LLM 的方法。它通过引入一种新的 4 位数据类型 (4-bit NormalFloat)、双重量化和分页优化器技术,极大地降低了微调大模型所需的显存,仅用一块消费级 GPU 即可微调数十亿参数的模型。这种方法在大幅节省资源的同时,几乎不损失模型性能,能达到与 16 位全量微调相当的效果。
影响:极大地降低了参与 LLM 研发的门槛,使得个人开发者和小型研究团队也能在消费级硬件上微调强大的模型。它迅速成为最主流和最受欢迎的高效微调技术之一,推动了开源社区的繁荣和 AI 应用的创新。QLoRA 的技术思想也启发了后续更多关于模型量化和效率优化的研究工作。
-
PagedAttention: Efficient Memory Management for LLM Serving (2023)

主要内容:提出了一种名为「分页注意力」(PagedAttention) 的新型注意力机制算法。它借鉴了操作系统中虚拟内存和分页的思想,将 LLM 的键 (Key) 和值 (Value) 缓存分割成非连续的固定大小「块」进行管理。这解决了因注意力缓存 (KV Cache) 导致的严重内存碎片和冗余问题,使得在处理长序列或并行处理多个请求时,内存利用率大幅提升。
影响:作为核心技术被集成到业界领先的推理服务框架 vLLM 中,将 LLM 的吞吐量提升了数倍,并显著降低了显存占用。这使得在相同硬件上服务更多用户、运行更大模型成为可能,极大地降低了 LLM 的部署成本和延迟,已成为当前高性能大模型服务 (LLM Serving) 领域的行业标准方案。
-
Mistral 7B (2023)

主要内容:Mistral 7B 论文介绍了一款高效的 70 亿参数语言模型。它通过分组查询注意力 (GQA) 和滑动窗口注意力 (SWA) 等创新架构,在显著降低计算成本和推理延迟的同时,实现了卓越性能。该模型在众多基准测试中,其表现不仅超越了同等规模的模型,甚至优于 Llama 2 13B 等参数量更大的模型,展现了小尺寸模型实现高水平推理与处理长序列的能力。
影响:Mistral 7B 的发布对开源 AI 社区产生了巨大影响,迅速成为高效能小型模型的标杆。它证明了小模型通过精巧设计足以媲美大模型,激发了社区在模型优化上的创新热情。该模型不仅被广泛用作各种下游任务微调的基础模型,还推动了 AI 技术在更低资源设备上的普及与应用,确立了 Mistral AI 在开源领域的领先地位。
-
LAION-5B: An open, large-scale dataset for training next generation image-text models (2022)

主要内容:LAION-5B 论文介绍了一个公开发布的、至今规模最大的图文对数据集。它包含从互联网抓取的 58.5 亿个 CLIP 过滤后的图像-文本对,并根据语言、分辨率、水印概率等进行了分类。该数据集的构建旨在民主化多模态大模型的训练,为研究社区提供了一个前所未有的、可替代私有数据集的大规模、开放资源。
影响:极大地推动了多模态人工智能的发展,尤其是在文本到图像生成领域。它成为了许多著名模型(如 Stable Diffusion)的基础训练数据,显著降低了顶尖 AI 模型的研发门槛。该数据集的开放性促进了全球范围内的研究创新与复现,深刻影响了此后生成式 AI 模型的技术路线和开源生态格局。
-
Tree of Thoughts: Deliberate Problem Solving with LLMs (2023)

主要内容:提出了一种名为「思想树」(Tree of Thoughts, ToT) 的新框架,旨在增强 LLM 解决复杂问题的能力。不同于传统的一次性生成答案,ToT 允许模型探索多个不同的推理路径,像人类一样进行深思熟虑。它通过自我评估和前瞻性规划来评估中间步骤的价值,并选择最有希望的路径继续探索,从而显著提升了在数学、逻辑推理等任务上的表现。
影响:为提升 LLM 的推理能力提供了全新且有效的途径,引发了学术界和工业界的广泛关注。它启发了一系列后续研究,探索如何让模型具备更强的规划和自主思考能力,推动了从简单「生成」到复杂「推理」的技术演进。ToT 框架已成为优化提示工程 (Prompt Engineering) 和构建更强大 AI 智能体 (Agent) 的重要思想之一。
-
Emergent Abilities of Large Language Models (2022)

主要内容:这篇论文的核心观点是,LLM 的能力并非随着规模增大而平滑提升,而是会「涌现」出一些小模型完全不具备的新能力。研究者发现,在多步推理、指令遵循等复杂任务上,只有当模型规模跨越某个关键阈值后,其性能才会从接近随机猜测的水平跃升至远超随机的水平。这种现象是不可预测的,只能通过实际测试更大规模的模型来发现。
影响:该论文为「大力出奇迹」的模型缩放路线 (Scaling Law) 提供了更深层次的理论解释和预期。它激发了业界对探索和理解大模型「涌现」能力的浓厚兴趣,推动了对模型能力边界的研究。同时,「涌现」这一概念也成为了解释为何更大模型(如 GPT-4)能处理更复杂、更精细任务的理论基石,深刻影响了后续模型的研发方向和评估标准。
-
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism (2019)

主要内容:该论文旨在解决单个 GPU 内存无法容纳巨型模型的核心工程难题。它提出了「张量并行」(即层内模型并行)技术,将 Transformer 层内部的巨大权重矩阵切分到多个 GPU 上,每个 GPU 仅计算一部分,再通过高效通信聚合结果。这种方法实现简单,且能与其他并行策略结合。研究者用该技术成功训练了当时前所未有的 83 亿参数模型,证明了其可行性。
影响:这项工作是 AI 基础设施的里程碑,它提供的张量并行技术是打破单 GPU 内存瓶颈的关键。它为训练拥有数千亿甚至万亿参数的模型铺平了道路,并与数据、流水线并行共同构成了现代大规模分布式训练的基石。Megatron-LM 开源库迅速成为行业标准,为学界和业界提供了实现超大规模 AI 的工程蓝图,将「规模化」理论变为了可操作的现实。
-
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models (2019)

主要内容:该论文提出了一种名为 ZeRO (零冗余优化器) 的显存优化技术。它通过在数据并行训练的各个 GPU 之间巧妙地分割和分配模型状态(优化器状态、梯度和参数),消除了显存冗余,从而能在现有硬件上训练远超以往规模的巨型模型,为万亿参数模型的实现铺平了道路。
影响:ZeRO 技术被整合进微软 DeepSpeed 等主流深度学习框架并获广泛采用。该技术极大降低了训练超大模型的硬件门槛,直接推动了后续 GPT 系列、BLOOM 等千亿乃至万亿参数模型的成功训练,是支撑当前大模型发展的关键基础设施技术之一。
-
OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER (2017)

论文地址:
主要内容:该论文引入了稀疏门控专家混合层 (MoE) 架构,通过条件计算解决了模型容量与计算成本的矛盾。该架构包含成千上万个「专家」子网络,由一个门控网络为每个输入仅激活少数几个专家进行处理。这使得模型参数可增加超 1000 倍,而计算成本仅有微小增加,从而在不牺牲效率的情况下,极大地提升了模型的知识吸收能力。
影响:这项工作首次在实践中大规模证明了条件计算的可行性,为构建拥有数千亿甚至万亿参数的巨型模型铺平了道路。MoE 已成为现代顶尖 LLM (如 Mixtral) 的核心技术之一,它通过让专家网络实现功能分化,在提升模型性能的同时保持了计算效率,对整个 AI 领域的大模型发展产生了深远影响。
重要优化与应用
地址: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Deep contextualized word representations (2018)
地址: https://aclanthology.org/N18-1202/
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020)
地址: https://arxiv.org/abs/2005.11401
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (2020)
地址: https://arxiv.org/abs/1910.10683
RoBERTa: A Robustly Optimized BERT Pretraining Approach (2019)
地址: https://arxiv.org/abs/1907.11692
Holistic Evaluation of Language Models (HELM) (2022)
地址: https://arxiv.org/abs/2211.09110
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference (2024)
地址: https://arxiv.org/abs/2403.04132
LIMA: Less Is More for Alignment (2023)
地址: https://arxiv.org/abs/2305.11206
Grouped-query attention (2023)
地址: https://arxiv.org/abs/2305.13245
Fast Inference from Transformers via Speculative Decoding (2022)
地址: https://arxiv.org/abs/2211.17192
GPTQ: Accurate Post-Training Quantization for Generative Language Models (2022)
地址: https://arxiv.org/abs/2210.17323
LLaVA: Visual Instruction Tuning (2023)
地址: https://arxiv.org/abs/2304.08485
PaLM 2 / BLOOM / Qwen (Series) (2022-2023)
PaLM 2 地址: https://ai.google/static/documents/palm2techreport.pdf
BLOOM 地址: https://arxiv.org/abs/2211.05100
Qwen 地址: https://arxiv.org/abs/2309.16609
Universal and Transferable Adversarial Attacks on Aligned Language Models (2023)
地址: https://arxiv.org/abs/2307.15043
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training (2023)
地址: https://arxiv.org/abs/2308.01320
前沿探索与新趋势
Language Models are Unsupervised Multitask Learners (2019)
地址: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
DistilBERT, a distilled version of BERT (2019)
地址: https://arxiv.org/abs/1910.01108
Efficient Transformers (Sparse / Longformer / Reformer / Performers) (2019-2020)
Sparse Transformers 地址: https://arxiv.org/abs/1904.10509
Longformer 地址: https://arxiv.org/abs/2004.05150
Reformer 地址: https://arxiv.org/abs/2001.04451
Performers 地址: https://arxiv.org/abs/2009.14794
SentencePiece: A simple and language independent subword tokenizer (2018)
地址: https://arxiv.org/abs/1808.06226
Generative Agents: Interactive Simulacra of Human Behavior (2023)
地址: https://arxiv.org/abs/2304.03442
Voyager: An Open-Ended Embodied Agent with Large Language Models (2023)
地址: https://arxiv.org/abs/2305.16291
Textbooks Are All You Need (Phi Series) (2023)
地址: https://arxiv.org/abs/2306.11644 (phi-1)
Jamba: A Hybrid Transformer-Mamba Language Model (2024)
地址: https://arxiv.org/abs/2403.19887
WizardLM: Empowering Large Language Models to Follow Complex Instructions (2023)
地址: https://arxiv.org/abs/2304.12244
TinyLlama: An Open-Source Small Language Model (2024)
地址: https://arxiv.org/abs/2401.02385
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (2025)
地址: https://arxiv.org/abs/2501.12948
Train Short, Test Long: Attention with Linear Biases (ALiBi) (2021)
地址: https://arxiv.org/abs/2108.12409
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration (2023)
地址: https://arxiv.org/abs/2306.00978
Red Teaming Language Models with Language Models (2022)
地址: https://arxiv.org/abs/2202.03286
Universal Language Model Fine-tuning for Text Classification (ULMFiT) (2018)
地址: https://arxiv.org/abs/1801.06146
XLNet: Generalized Autoregressive Pretraining for Language Understanding (2019)
地址: https://arxiv.org/abs/1906.08237
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation… (2020)
地址: https://aclanthology.org/2020.acl-main.703/
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (2020)
地址: https://arxiv.org/abs/2003.10555
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (2020)
地址: https://arxiv.org/abs/2006.16668
MEASURING MASSIVE MULTITASK LANGUAGE UNDERSTANDING (MMLU) (2020)
地址: https://arxiv.org/abs/2009.03300
Beyond the Imitation Game: Quantifying and extrapolating… (BIG-bench) (2022)
地址: https://arxiv.org/abs/2206.04615
Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models… (2023)
地址: https://arxiv.org/abs/2312.12148
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale (2022)
地址: https://arxiv.org/abs/2207.00032

©
(文:机器之心)