

智东西6月30日消息,百度正式开源文心大模型4.5系列模型!
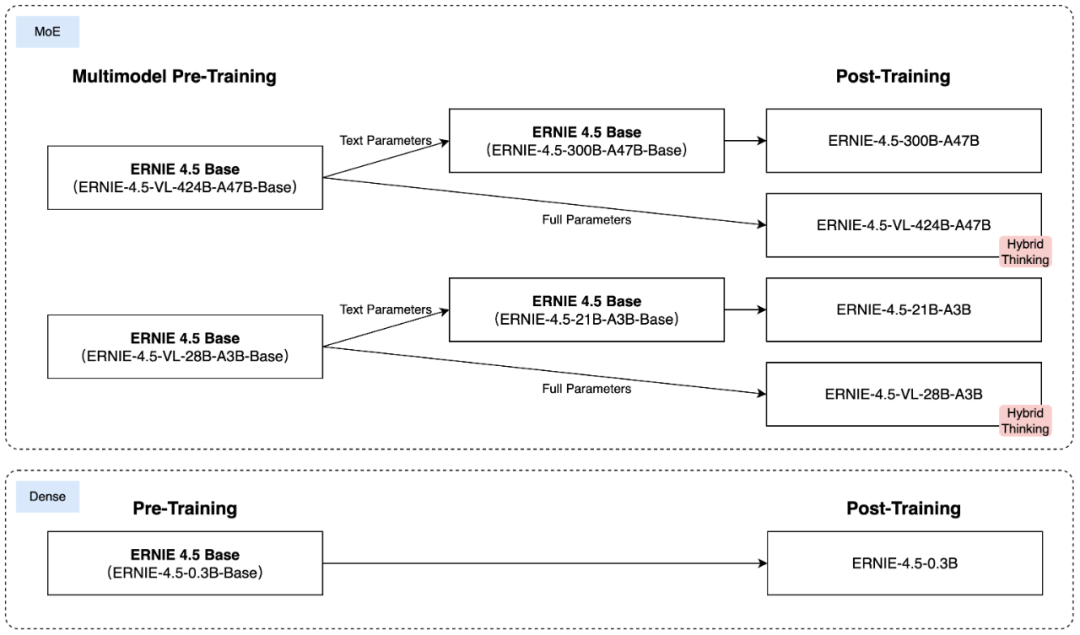
此次百度一口气开源了10款模型,涵盖47B、3B激活参数的混合专家(MoE)模型,0.3B参数的稠密型模型等,并实现预训练权重和推理代码的完全开源。
▲Hugging Face上的文心大模型4.5系列模型开源列表
目前,文心大模型4.5开源系列已可在飞桨星河社区、Hugging Face等平台下载部署使用,同时开源模型API服务也可在百度智能云千帆大模型平台使用。
早在今年2月,百度就已预告了文心大模型4.5系列的推出计划,并明确将于6月30日起正式开源。不过百度这次的开源列表没有其升级版文心大模型4.5 Turbo系列。
Hugging Face:https://huggingface.co/baidu/models
飞桨星河社区:https://aistudio.baidu.com/modelsoverview



文心大模型4.5于3月16日发布,是百度自研新一代原生多模态基础大模型,其图片理解涵盖照片、电影截图、网络梗图、漫画、图标等多种形态,也能理解音视频中的场景、画面、人物等特征,并且在生成名人、物品等方面更具真实性。
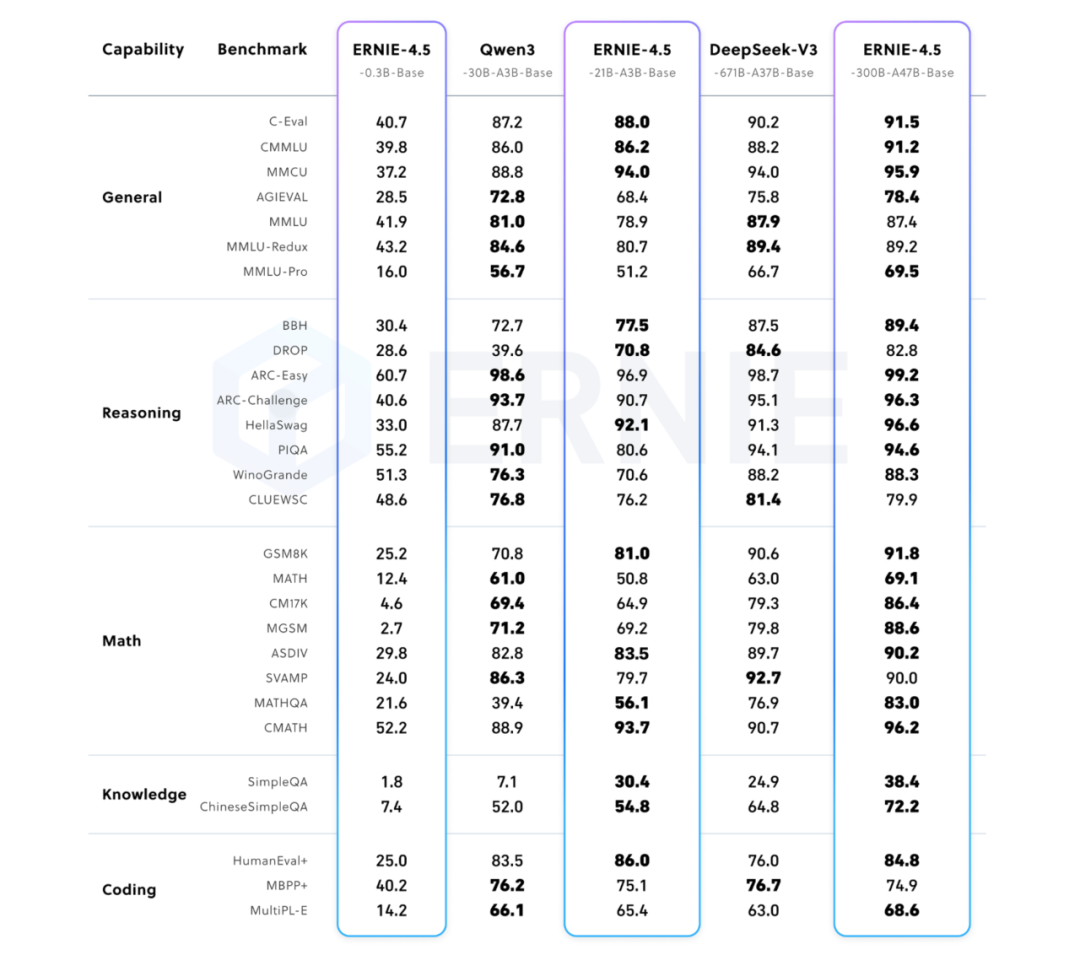
▲文心4.5系列模型与Qwen3、DeepSeek-V3基准测试比较
文心大模型4.5系列背后的关键技术创新包括:
1、多模态异构MoE预训练:其模型基于文本和视觉模态进行联合训练,可捕捉多模态信息的细微差别,并提升文本理解与生成、图像理解以及跨模态推理等任务的性能。
为了实现这一目标,避免一种模态阻碍另一种模态的学习,百度研究人员设计了一种异构MoE结构,并引入了模态隔离路由,采用了路由器正交损失和多模态标记平衡损失。这些架构选择可以确保两种模态都得到有效表示,从而在训练过程中实现相互强化。
2、可扩展、高效的基础设施:百度提出异构混合并行和分层负载均衡策略,以实现ERNIE 4.5模型的高效训练。研究人员通过采用节点内专家并行、内存高效的流水线调度、FP8混合精度训练和细粒度重计算方法,实现了预训练吞吐量提升。
在推理方面,研究人员提出多专家并行协作方法和卷积码量化算法,以实现4位/2位无损量化。此外还引入具有动态角色切换的PD分解,提升ERNIE 4.5 MoE模型的推理性能。基于PaddlePaddle构建的ERNIE 4.5可在各种硬件平台上提供高性能推理。
3、针对特定模态的后训练:为了满足实际应用的多样化需求,百度针对特定模态对预训练模型的变体进行了微调。其大模型针对通用语言理解和生成进行了优化。
VLM专注于视觉语言理解,并支持思考和非思考模式,每个模型都结合使用了监督微调(SFT)、直接偏好优化(DPO)或统一偏好优化(UPO)的改进强化学习方法进行后训练。
在视觉-语言模型的微调阶段,视觉与语言的深度融合对模型在理解、推理和生成等复杂任务中的表现起着决定性的作用。为了提升模型在多模态任务上的泛化能力和适应性,研究人员围绕图像理解、任务定向微调和多模态思路推理三大核心能力,进行了系统性的数据构建和训练策略优化。此外,其利用可验证奖励强化学习(RLVR)进一步提升模型对齐和性能。
作为国内最先入局大模型研发的巨头之一,百度已经形成了文心大模型4.0 Turbo、性能强劲的轻量模型ERNIE Speed Pro和ERNIE Lite Pro到当下的文心大模型4.5、文心大模型X1,以及升级版文心大模型4.5 Turbo等模型系列,其模型数量稳步递增,模型类型愈发多元。到2024年,文心大模型的日均调用量达到16.5亿,而2023年同期这一数字仅为5000万次,增长达到33倍。
(文:智东西)