

-
基于流水线的OCR表现出最佳性能。在所有OCR解决方案中,使用Marker实现了最佳的检索性能,而MinerU在生成和整体评估中占据主导地位。 -
所有OCR解决方案都遭受了性能下降。即使是最好的解决方案,在整体评估中EM@1下降了1.9,F1@1下降了2.93,而在检索和生成阶段的损失更大。 -
RAG系统中不使用OCR而直接使用视觉-语言模型(VLMs)的潜力。

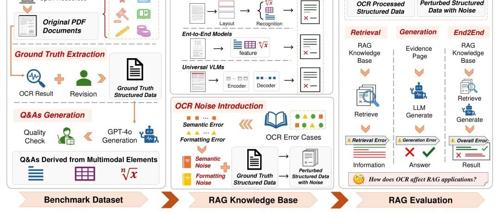
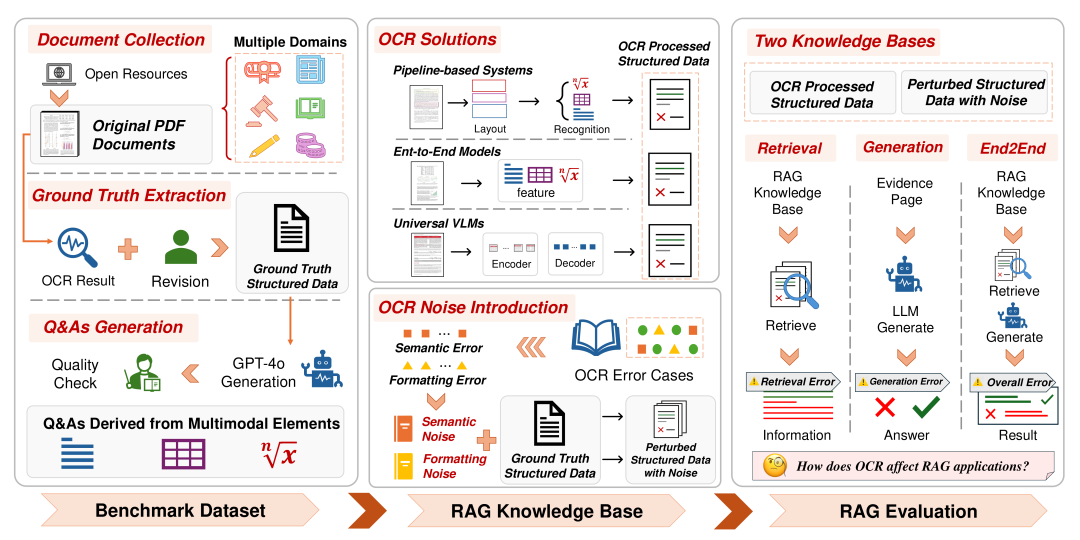
OHRBench的构建与评估协议。(1) 基准数据集:从六个领域收集PDF文档,提取经过人工验证的地面真实结构化数据,并从多模态文档元素生成问答。(2) RAG知识库:用于基准测试当前OCR解决方案的OCR处理结构化数据,以及用于评估不同OCR噪声类型影响的扰动结构化数据。(3) 评估OCR对每个组件以及整个RAG系统的影响。


https://github.com/opendatalab/OHR-BenchOCR Hinders RAG: Evaluating the Cascading Impact of OCR on Retrieval-Augmented Generationhttps://arxiv.org/pdf/2412.02592
(文:PaperAgent)