
点击上方“蓝色字体”关注我,每天推送“实用有趣的项目”!
音乐爱好者和音频处理专业人士的福音来了!
今天分享一款开源的音频分离WebUI工具:MSST。
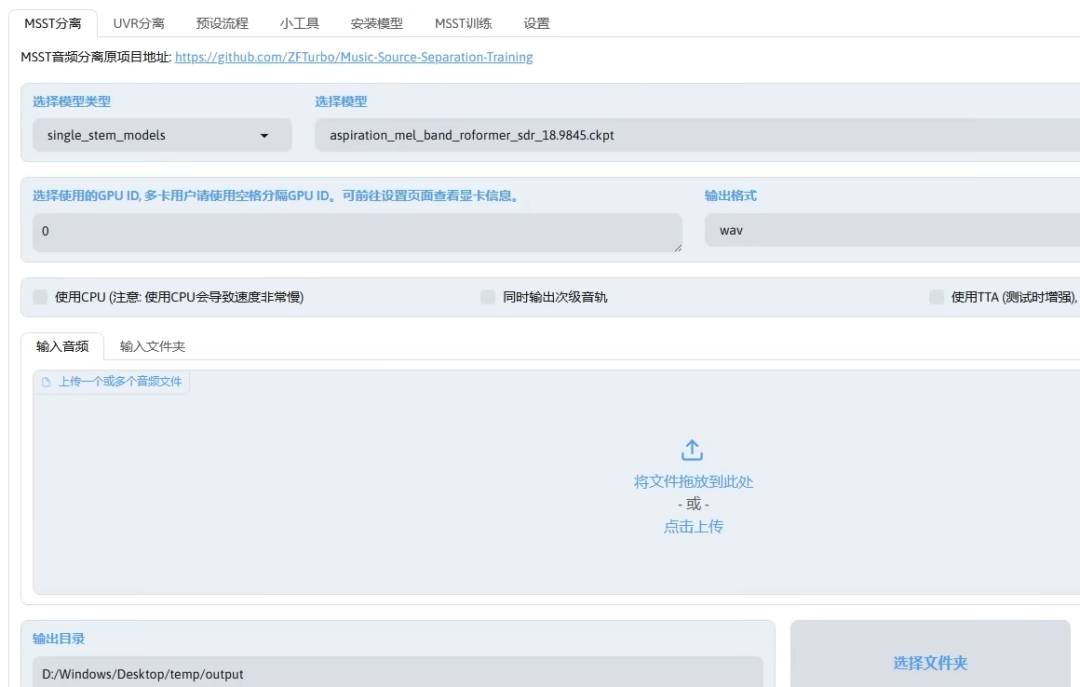
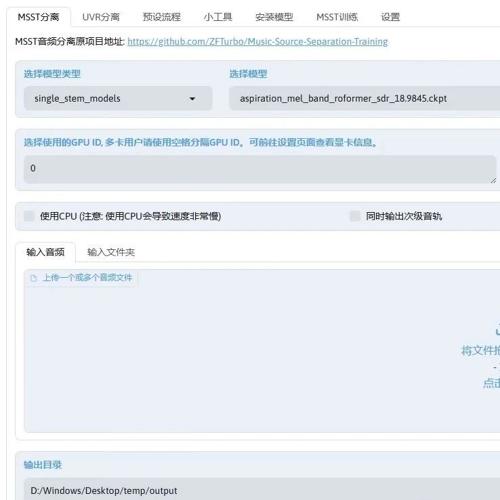
MSST(音源分离训练推理 WebUI ) 是一个集成了音源分离训练框架和 UVR(终极人声消除器)的强大 Web 界面。
无论是分离人声、伴奏,还是其他音频元素,这个工具都能轻松实现,真正做到 高效且灵活的音乐源分离。
主要特点
-
• 直观的 Web 界面:无需复杂的命令行操作,通过 WebUI 完成模型的安装、配置和分离处理,简单易用。
-
• 集成 UVR:强大的终极人声消除功能,精准分离人声与伴奏,适配各种音源处理需求。
-
• 灵活的自定义处理流程:支持用户根据需要配置和优化音源分离流程,满足个性化需求。
-
• 快速安装和使用模型:一键安装和加载预训练模型,无需额外下载步骤,开箱即用。
-
• 训练与推理框架整合:提供音源分离的训练与推理功能,用户可自行训练模型以获得更佳分离效果。
技术亮点
-
• UVR 引擎优化:通过最新的模型和算法,确保分离结果具有良好的音质与高保真度。
-
• 多种分离模型支持:可加载多种预训练模型,适配不同类型的音源分离需求。
-
• 高效的训练和推理:提供完善的训练框架,用户可通过自定义数据集进行音源分离模型训练。
-
• 便捷的批量处理功能:支持批量音频文件处理,大幅提升工作效率。
使用指南
Windows系统 可直接安装一键安装包,前往项目Release页面下载(也可下滑至文末获取)
MacOS系统需用代码部署
①克隆项目代码:
git clone https://github.com/SUC-DriverOld/MSST-WebUI.git
cd MSST-WebUI②创建Python虚拟环境并安装依赖
conda create -n msst python=3.10 -y
conda activate msst
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt --only-binary=samplerate
pip uninstall librosa -y
pip install tools/webUI_for_clouds/librosa-0.9.2-py3-none-any.whl③启动 Web 界面:
python webUI.py支持以下选项参数:
–server_name 自定义IP地址,默认:0.0.0.0
–server_port 自定义IP端口,默认: 7860
–share 开启分享链接,默认:关闭
–debug 开启Debug模式,默认:关闭
④打开浏览器访问 WebUI(默认地址):http://127.0.0.1:7860

最新版本更是支持自定义安装模型
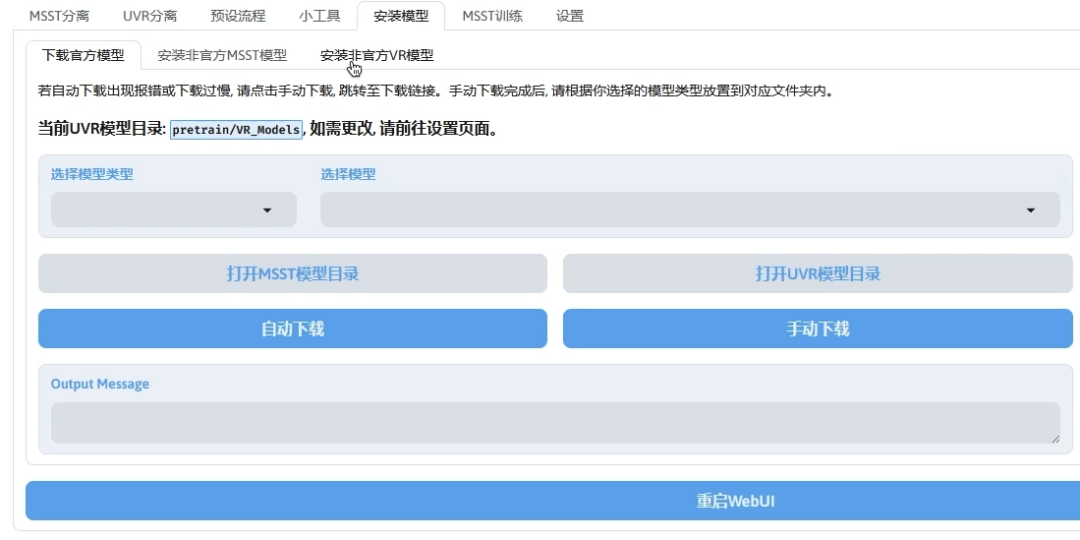
写在最后
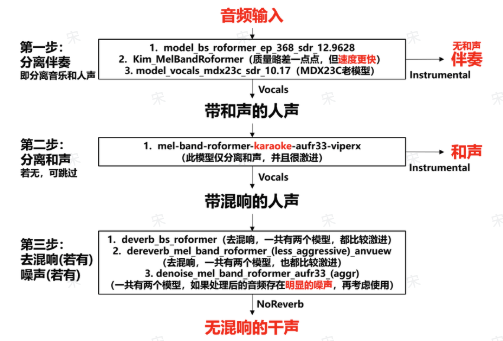
MSST 将复杂的音源分离技术通过 Web 界面简化成了一种易于操作的体验,无论是音频爱好者还是专业工作者,都能轻松使用其强大功能。
你可以直接使用现成的模型,或者训练自己的定制模型,满足各种音频处理需求。
GitHub:https://github.com/SUC-DriverOld/MSST-WebUI
TIPS:如有下载问题,可复制关键词 “msst” 发送到公众号,获取工具相关安装包。
往期推荐 ⬇️ 『今日软荐』专题
今日软荐:抠图工具再添一员猛将!批量去背景从未如此简单
今日软荐:3.4K Star!一个集成了Claude 3.5 Sonnet的 VSCode AI编程工具:Claude Dev
今日软荐:GitHub 上 IPTV 电视直播源更新神器:TV 频道管理工具
今日软荐:可平替Snipaste的强大截图工具!长截图/gif动态截图/文字识别,简单但不简单!
PS:动动小手指,点点“在看”吧!
(文:开源星探)
挺像gpt-sovits的