


近日,一个「人形机器人做汉堡」的视频火爆全网!
这个具备 [主动视觉]、[高精度触觉] 以及 [高自由度灵巧手] 的人形机器人,首次实现了 2.5 分钟连续自主控制,从原材料开始,一步步制作出完整汉堡,并递到你的盘子里。
真正让机器人「看得见」、「摸得准」、「动得巧」,未来厨房可能真的不需要人类了!
灵巧操控是机器人实现类人交互的关键能力,尤其在涉及多阶段、细致接触的任务中,对控制精度与响应时机提出了极高要求。尽管视觉驱动的方法近年来快速发展,但在遮挡、光照变化或复杂接触环境下,单一视觉感知常常失效。
触觉感知为机器人提供了与环境交互的直接反馈,在判断接触状态、施力时机等方面扮演着不可替代的角色。然而,当前大多数方法仅将触觉信息作为静态输入进行融合,缺乏真正有效的多模态联合建模机制。更为关键的是,现有方法往往只关注当前的触觉状态,忽视了对未来触觉变化的预测。这种短视导致机器人在连续操作中难以提前准备、策略难以稳定,特别是在需要时序感知和力觉判断的任务中表现不佳。
尽管已有研究尝试引入触觉信息提升策略表现,但往往停留在简单拼接或辅助通道的层面,缺乏结构性设计,难以充分发挥视触结合的潜力。
为应对上述挑战,来自 UC 伯克利、北京大学、Sharpa 等机构的研究人员提出 ViTacFormer,一个融合视觉与触觉信息,并引入未来触觉预测机制的统一框架,专为提升灵巧操控中的精度、稳定性与持续控制能力而设计。
论文作者包括我们熟悉的 UC Berkeley 大牛 Pieter Abbeel 和 Jitendra Malik,以及他们的学生,北大校友、UC Berkeley 博士生耿浩然 (项目 lead)。

-
论文标题:
ViTacFormer: Learning Cross-Modal Representation for Visuo-Tactile Dexterous Manipulation
-
论文主页:
https://roboverseorg.github.io/ViTacFormerPage/
-
Github 链接:
https://github.com/RoboVerseOrg/ViTacFormer
这项研究获得了业内人士的高度认可,多位知名学者和企业家讨论和转发,其中就包括 Transformer 作者之一、GPT-4 作者之一 Lukasz Kaiser。
ViTacFormer 介绍
方法设计:跨模态注意力与触觉预测
ViTacFormer 核心思想是构建一个跨模态表征空间,通过多层跨注意力模块在策略网络的每一步中动态融合视觉信息与触觉信号,实现对接触语义与空间结构的联合建模。
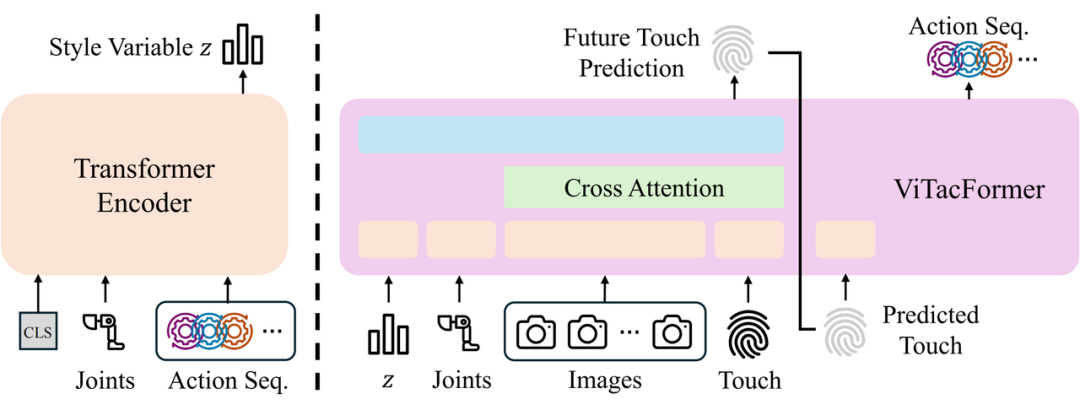
与传统方法仅依赖当前触觉观测不同,ViTacFormer 引入了一个自回归触觉预测分支,以强化模型对未来接触状态的建模能力。该模块强制共享表征空间编码可用于预测的触觉动态特征,使策略不仅「看得见、摸得到」,还能 「预判下一步触感变化」。
在推理过程中,模型首先基于当前观测预测未来的触觉反馈信号,再将其用于指导动作生成,从而实现由 「感知当前」 向 「预测未来」 的关键转变。我们通过实验证明,这种基于未来触觉信号的前瞻式建模方式显著提升了动作策略的稳定性与精度。
系统架构:双臂灵巧手与视触觉数据采集
ViTacFormer 基于一套双臂机器人系统进行数据采集与策略评估。系统由两台 Realman 机械臂组成,每条机械臂搭载一只 SharpaWave 灵巧手(开发版本),具有 5 指结构和 17 个自由度,支持高自由度的多指动作控制。每个手指的指尖均配备分辨率为 320×240 的触觉传感器,用于实时记录接触反馈。
视觉感知部分包括两种视角:手腕安装的鱼眼相机提供近距离局部观察以及顶部 ZED Mini 立体摄像头提供全局场景信息。视觉与触觉数据同步记录,覆盖机器人执行过程中的关键状态变化。
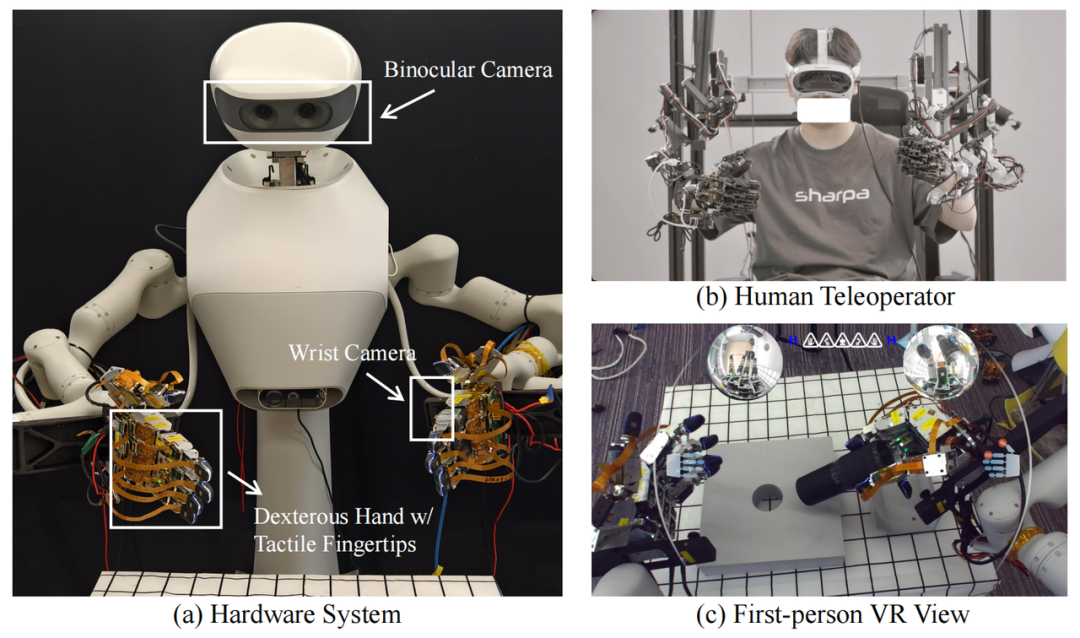
在专家示范采集过程中,团队使用一套基于机械外骨骼手套的遥操作系统。操作者通过手套与灵巧手形成机械联动,并佩戴 VR 头显获取第一人称沉浸式反馈。该界面集成了立体顶视图、双腕局部视图与实时触觉图像叠加,支持自然直观的操控体验,有效提升了接触密集型任务的示范质量。
实验评估:真实任务中的操作性能验证
基线比较:在短程灵巧操作任务中的表现
团队在四项真实的短程灵巧操控任务上评估了 ViTacFormer 的性能,包括插销(Peg Insertion)、拧瓶盖(Cap Twist)、擦花瓶(Vase Wipe)和翻书(Book Flip),每项任务均具有明确的接触依赖性与细粒度控制需求。
实验设置中,每个任务仅使用 50 条专家轨迹进行训练,并在测试阶段独立推理 10 次,以评估模型在有限数据条件下的策略学习能力与执行稳定性。
团队将 ViTacFormer 与四个当前代表性的模仿学习基线方法进行比较:Diffusion Policy (DP)、HATO、ACT 和 ACTw/T。DP 和 ACT 分别代表当前主流的视觉模仿策略,不使用触觉信息;而 HATO 和 ACTw/T 则在输入中引入触觉信号,但均采用直接拼接或简单 token 融合的方式,未进行深入建模。
相比之下,ViTacFormer 采用跨模态注意力与自回归预测机制,充分挖掘视觉与触觉之间的动态依赖关系。
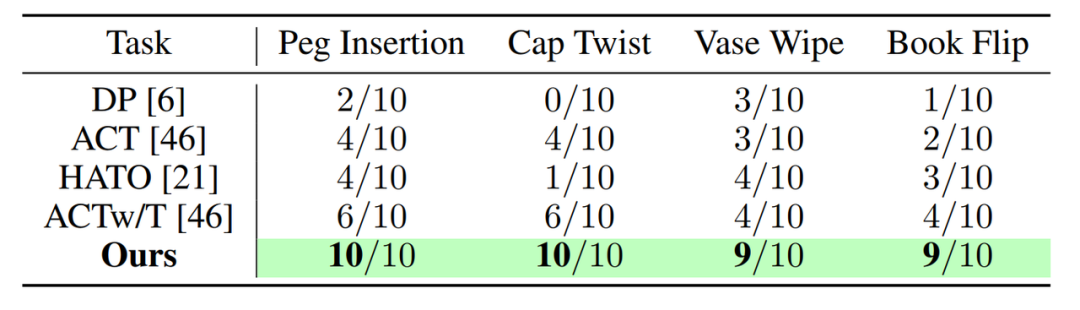
从结果来看(见上表),ViTacFormer 在所有短程灵巧操控任务中均显著优于现有方法,相比仅使用视觉或简单融合触觉的模型,成功率稳定提升,平均增幅超过 50%。这表明跨模态注意力与未来触觉预测在提升操作稳定性与精度方面具有关键作用。
长时任务评估
稳定完成 11 阶段连续操作流程
为进一步验证 ViTacFormer 在复杂任务中的执行能力,团队对其在一项长时灵巧操作任务中进行评估。
该任务包括 11 个连续子阶段,模拟制作汉堡的全过程,涵盖多指协调、精细接触与长时间持续控制等挑战,对策略的稳定性与动作连贯性提出了极高要求。
实验结果显示,ViTacFormer 能够稳定完成整个操作序列,持续操控时间达到约 2.5 分钟,整体成功率超过 80%。在长时间、多阶段的任务中,系统表现出良好的动作连贯性和接触控制能力,充分体现了视触觉融合策略在复杂任务执行中的优势。

©
(文:机器之心)