

MedGemma模型概览:其核心能力在于接收文本与图像两种模态的输入,并生成高质量的文本输出,适用于从视觉问答到影像报告生成的多种医疗任务。图片来源: Google Research
谷歌发布了专为医疗健康领域设计的开源AI模型系列MedGemma。该系列基于Gemma 3架构,包含能同时处理文本与图像(如X光片)的多模态模型。在多个医疗基准测试中,MedGemma展现出与顶尖模型相媲美的性能,同时保持了显著更低的部署成本。其开源属性为开发者提供了数据隐私控制、模型深度定制和应用长期稳定性等关键优势。这标志着高性能医疗AI正从封闭的API服务模式,向更加开放、可控、协同发展的开发范式演进。
医疗AI站在“开放”与“封闭”的十字路口
在人工智能技术飞速发展的今天,医疗健康领域无疑是最受瞩目也最具挑战性的应用场景之一。然而,主流的大模型多以“黑箱”API的形式提供服务,这在普通消费领域或许高效,但在医疗行业却带来了三大核心挑战:数据隐私与安全、针对特定任务的性能瓶颈,以及模型迭代不可控带来的合规风险。
在此背景下,谷歌的健康AI开发者基础(HAI-DEF)项目选择了一条不同的道路。他们近期发布了MedGemma模型家族,将先进的医疗AI能力以开源形式提供给全球开发者。此举并非简单的技术发布,更像是一次战略选择,旨在探讨一个核心问题:对于医疗这样高度专业化和数据敏感的领域,开放的、可控的模型基础,是否比一个封闭的通用API更有价值?这或许是医疗AI发展范式从追求“更强”到追求“更适用、更可信”的转折点。
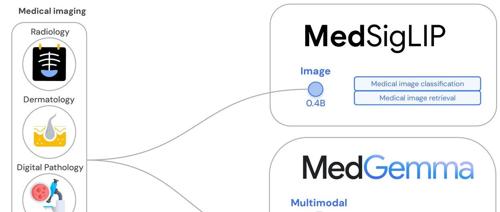
MedGemma模型家族:性能与成本的双重优势
MedGemma并非单一模型,而是一个包含不同尺寸和功能的模型集合,全部基于Gemma 3架构开发,旨在为开发者提供灵活的起点。
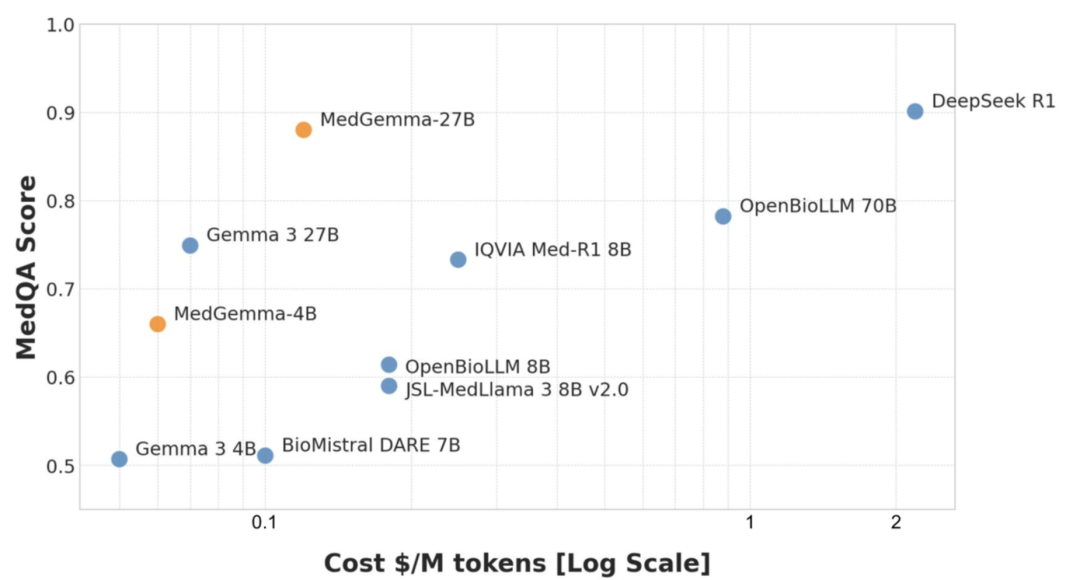
MedGemma在MedQA基准上的性能与成本对比。图中显示,MedGemma 27B(文本)的性能(87.7%)与更大规模的闭源模型(如GPT-3.5)和开源模型(如DeepSeek R1)相当,但其预估的推理成本(蓝色条)远低于同级别对手。图片来源: Google Research
旗舰性能:MedGemma 27B (文本与多模态)
这是该系列的旗舰版本,面向需要更高性能的复杂研究与应用。
-
• 文本模型: 如上图所示,该模型在MedQA上取得了87.7%的高分,性能与顶尖开源模型DeepSeek R1相差不到3个百分点,但推理成本仅为后者的约十分之一。 -
• 多模态模型: 作为最新发布的成员,它扩展了27B模型的边界,能够解读和综合分析复杂的纵向电子健康记录(longitudinal EHR)。根据官方说明,EHR数据仅被用于训练MedGemma 27B多模态模型,使其成为处理结构化病历数据的首选。
高效多能:MedGemma 4B 多模态模型
这是一款轻量级模型,旨在平衡性能与效率,支持图像和文本作为输入。
-
• 基准性能: 在MedQA基准上,获得了64.4%的分数,在同等规模(<8B)的开源模型中表现突出。 -
• 影像报告生成: 在一项由美国委员会认证的放射科医生参与的评估中,81%由MedGemma 4B生成的胸部X光报告被认为在准确性上足以引导与原始报告相似的患者管理决策。 -
• 部署优势: 模型可在单GPU上运行,并可适配于移动端硬件,为AI能力下沉到边缘设备提供了可能。
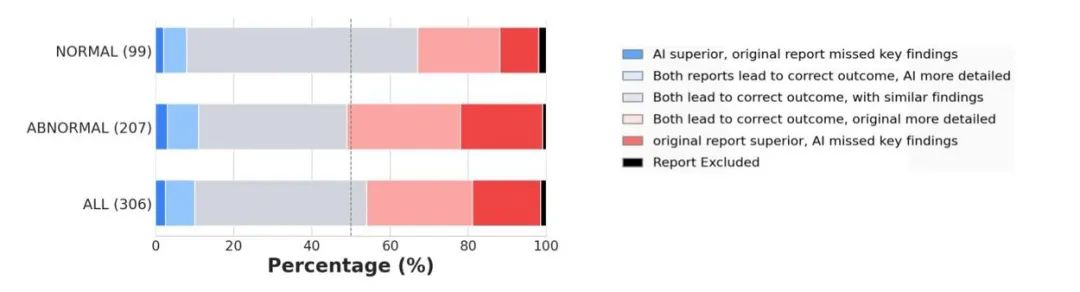
对MedGemma生成报告的临床评估。右侧为模型生成的胸部X光(CXR)报告,评估结果显示,81%的报告在指导后续患者管理上与人类放射科医生的报告等效。图片来源: Google Research
MedSigLIP:MedGemma背后的专业“视觉引擎”
MedGemma强大的多模态能力,很大程度上源于其专为医疗优化的图像编码器——MedSigLIP。它本身也是一个独立的、参数量仅为4亿的轻量级模型。
MedSigLIP工作原理示意图。它能将包括胸片、病理切片、皮肤和眼底图像在内的多种医疗影像,与医疗文本共同编码到一个统一的嵌入空间,实现跨模态的理解和检索。图片来源: Google Research
-
• 专业化训练: MedSigLIP基于SigLIP架构,并使用多样化的医疗影像数据进行微调,使其能够学习这些模态特有的细微特征。 -
• 核心能力: 通过统一的嵌入空间,MedSigLIP擅长执行: -
• 图像分类: 性能与特定任务的专用视觉模型相当甚至更优。 -
• 零样本分类: 无需额外训练,即可通过文本标签对新类型的图像进行分类。 -
• 语义图像检索: 在大型数据库中,根据视觉或语义相似性查找图像。 -
• 通用性保留: 与MedGemma一样,MedSigLIP在获得专业能力的同时,也保留了其在自然图像上的强大性能,保持了模型的通用性和灵活性。
开源的核心价值:重塑医疗AI的开发范式
MedGemma选择开源,是对医疗行业特殊性的深刻回应。相较于API模式,开源为开发者和医疗机构提供了三大不可或缺的优势:
-
1. 数据主权:让敏感数据留在本地:开源模型允许在机构的私有云或本地硬件上部署,确保敏感的患者数据无需离开防火墙,从根本上解决了数据主权和隐私合规的难题。 -
2. 性能优化:为特定任务打造“专家模型”:开源允许开发者使用自有数据对模型进行微调(Fine-tuning)。例如,经过微调的MedGemma 4B在胸部X光报告生成任务上,RadGraph F1分数达到30.3,实现了该任务上的SOTA(State-of-the-art)性能。 -
3. 长期可信:确保研究与应用的可复现性:开源模型以版本快照的形式分发,其参数是固定的,不会意外改变。这种稳定性对于需要长期保持一致性和可复现性的临床研究和应用至关重要。
开发者指南:如何选择与使用MedGemma模型
为了帮助开发者快速上手,谷歌不仅提供了模型,还配套了一系列资源,包括一份清晰的模型选型指南。
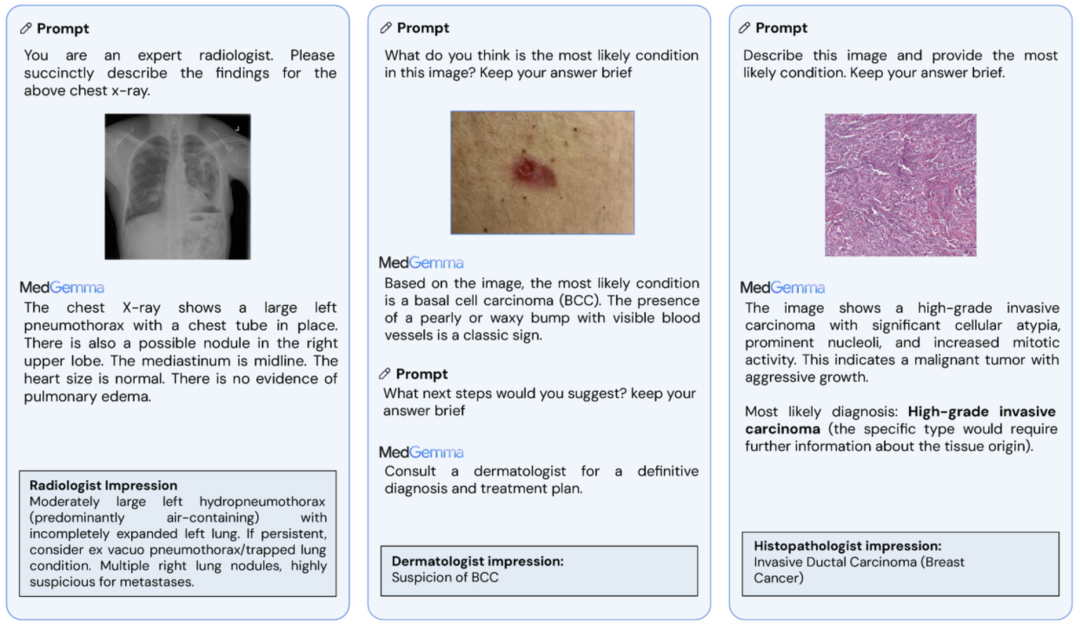
官方模型选型指南,清晰列出了不同模型版本最擅长的任务。图片来源: Google Research
根据上表:
-
• 对于视觉问答(VQA)和通用文本/图像报告生成,4B和27B的多模态版本均适用。 -
• 对于复杂的EHR记录解读,推荐使用专门为此训练的MedGemma 27B 多模态模型。 -
• 对于纯粹的文本摘要和问答,MedGemma 27B 文本模型是性价比最高的选择。 -
• 脚注中还提到,对于不需要语言对齐的病理学专用应用,谷歌另外提供了Path Foundation模型,这为开发者提供了更细分的工具选择。
此外,开发者可以通过Hugging Face(以safetensors格式)、GitHub(提供详细的推理和微调教程)以及Google Vertex AI(用于规模化部署)等平台获取完整资源。谷歌还提供了一个名为appoint-ready的开源演示应用,展示了如何利用MedGemma简化患者就诊前的信息收集流程。
重要声明与未来展望
谷歌在发布时明确指出,MedGemma和MedSigLIP是为AI开发提供支持的基础模型,其本身并非医疗器械,也不能直接用于临床诊断或治疗决策。所有模型的输出都应被视为初步信息,需要经过人类专家的独立验证和临床相关性评估。
展望未来,MedGemma的真正意义,不在于提供一个“开箱即用”的答案,而在于提供了一个高质量、可信赖的“起点”。它通过降低技术门槛,将创新的权力交还给最了解临床需求的医疗专家和开发者。这或许将引领医疗AI领域从依赖少数几个“封闭花园”的模式,走向一个由全球社区共同建设、更加繁荣和开放的生态系统。
推荐阅读
-
• MedGemma官方博客: https://research.google/blog/medgemma-our-most-capable-open-models-for-health-ai-development/ -
• MedGemma技术报告 (arXiv): https://arxiv.org/abs/2507.05201 -
• 健康AI开发者基础 (HAI-DEF) 官网: http://goo.gle/hai-def -
• Hugging Face模型集: https://huggingface.co/collections/google/medgemma-release-680aade845f90bec6a3f60c4
(文:子非AI)