


大型语言模型(LLMs)虽在复杂推理任务中表现出色,却存在”无差别计算”缺陷:对简单问题过度消耗资源(如用微积分解1+1),对难题却因计算不足而失败。这种低效性严重阻碍其在自动驾驶、实时医疗等场景的应用。本文首次提出双层效率优化框架,系统梳理了”预算可控”(L1)与”动态自适应”(L2)两类前沿技术,通过大规模实验揭示效率瓶颈,并为轻量化推理指明路径。

-
论文:Reasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs -
链接:https://arxiv.org/pdf/2507.02076
研究背景与动机
LLMs的推理如同”考试答题”:传统模型对每道题固定耗时,无论题目难易。这导致两大问题:
-
过度思考(Overthinking):简单问题生成冗长推理链(如12K tokens计算√1234),浪费50%+算力; -
思考不足(Underthinking):复杂问题因计算不足频繁切换思路,无法深入求解(如空间推理任务)。
工业界已意识到问题严重性:Anthropic为Claude 3.7添加”思考token预算”,OpenAI的o1系列提供”低/中/高”推理强度选项。这些尝试凸显动态计算分配已成为LLM落地的关键技术壁垒。
核心分类框架:双层效率优化
论文创新性地提出层级化解决方案:
-
L1(可控计算):用户设定预算上限(如最多生成1000 tokens),模型在此约束下优化答案质量。
其中 为性能指标, 为效率指标, 是用户设定的预算
核心思想:像”考试限时答题”,强制在规定资源内完成推理。 -
L2(自适应计算):模型自主分配计算量,平衡质量与效率:
调节效率权重
核心思想:像”学生根据题难度自主分配时间”,简单题快速作答,难题深入思考。
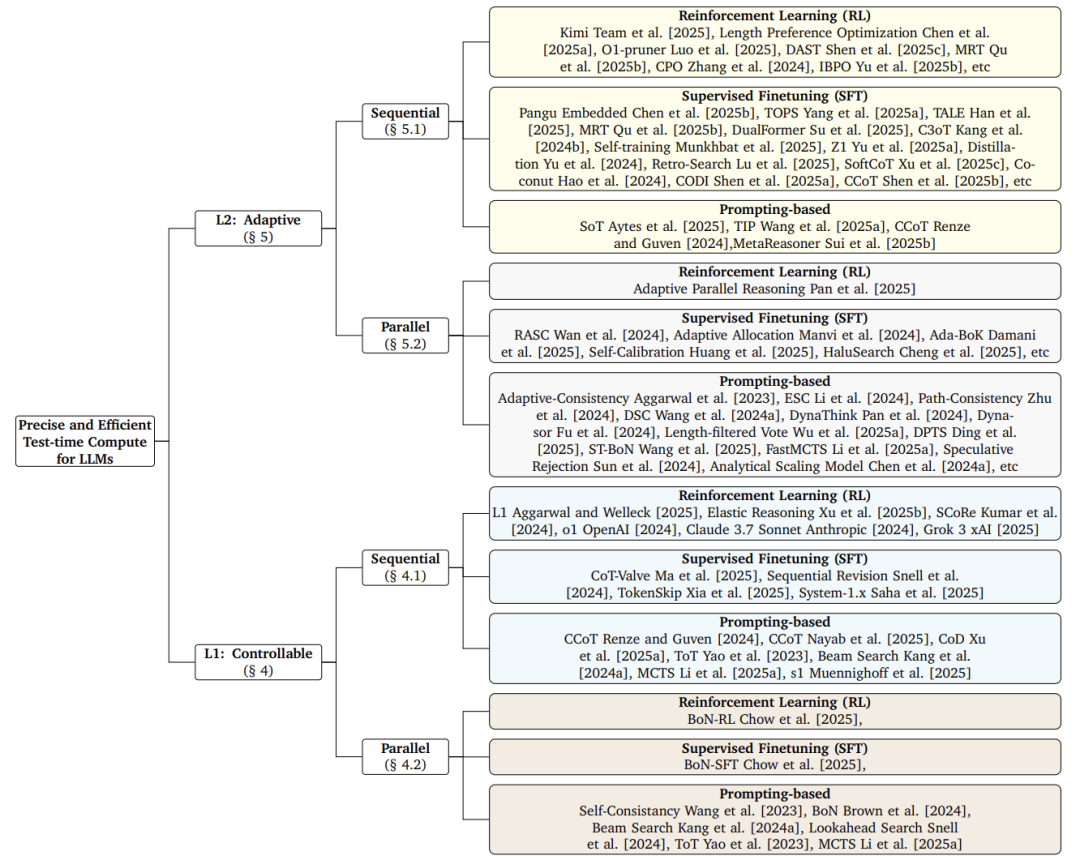
L1方法:预算约束下的推理控制
序列方法
-
TokenSkip压缩:
-
生成完整思维链(CoT) -
删除冗余token(如重复解释) -
微调模型学习压缩版CoT
优势:压缩率可达70%,但可能损失可读性。 -
System 1.x混合规划:
-
Controller:将任务分解为子目标 -
System 1:处理简单子目标(直觉式快速推理) -
System 2:处理复杂子目标(搜索式慢速推理)
用户通过”混合因子”调控速度-精度平衡
并行方法
-
自一致性提前终止:
当多数投票结果稳定时(如5个样本中4个答案相同),立即停止采样,避免无效计算。 -
推理感知微调:
训练时模拟推理过程(如Best-of-N采样),使模型适应测试环境。
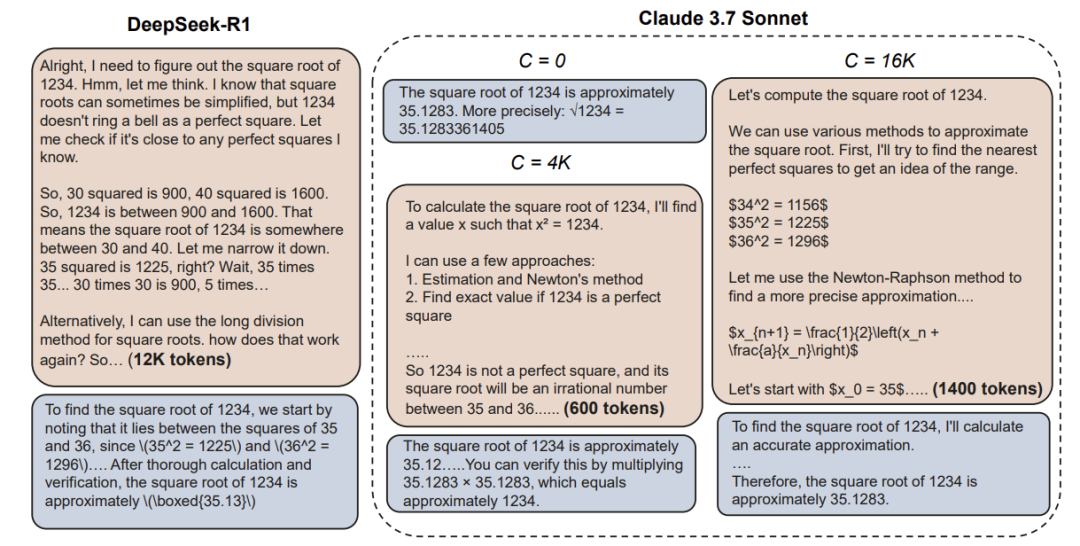
L2方法:动态自适应推理
提示工程
-
简洁思维链(CCoT):
指令”逐步思考并保持简洁”使GPT-4输出长度减少40%,但弱模型(如GPT-3.5)在数学题上性能下降。 -
元推理器(MetaReasoner):
动态监控推理进度,遇困时触发策略调整(如:”当前路径无效,建议回溯步骤3″)。
微调技术
-
连续潜空间推理:
将离散token替换为隐藏层向量:# 传统: token -> 文本 -> 答案
# 新方法: 隐藏向量 -> 答案效果:减少50% token,但需防范灾难性遗忘。
-
长短思维链蒸馏:
-
教师模型生成长短两种CoT -
学生模型学习”何时用短CoT”(如添加[简单]标签)
突破:模型自适应选择推理深度。
强化学习(RL)
核心是在奖励函数中加入效率惩罚:
-
基础设计: 奖励 = 准确性得分 - β × 输出长度 -
创新方案(如DAST):
引入Token长度预算(TLB):基 难度系数由问题类型决定(如数学题系数>历史题)。准 长 度 难 度 系 数
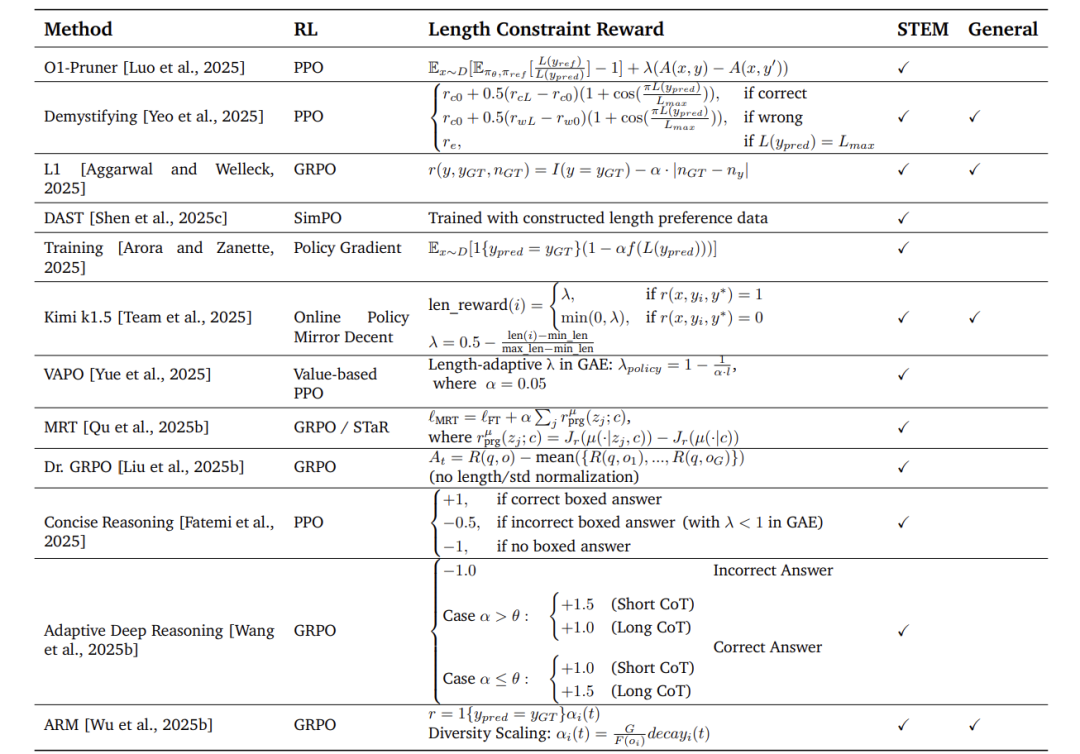
实验分析与核心发现
关键实验1:商业模型预算控制
-
测试集:AIME(奥数题) vs MATH500(基础数学) -
发现: -
Claude在MATH500上严格遵循预算(<5%超标) -
但AIME难题出现长尾超标(20%样本超预算2倍)
关键实验2:效率-性能权衡
-
惊人结论:
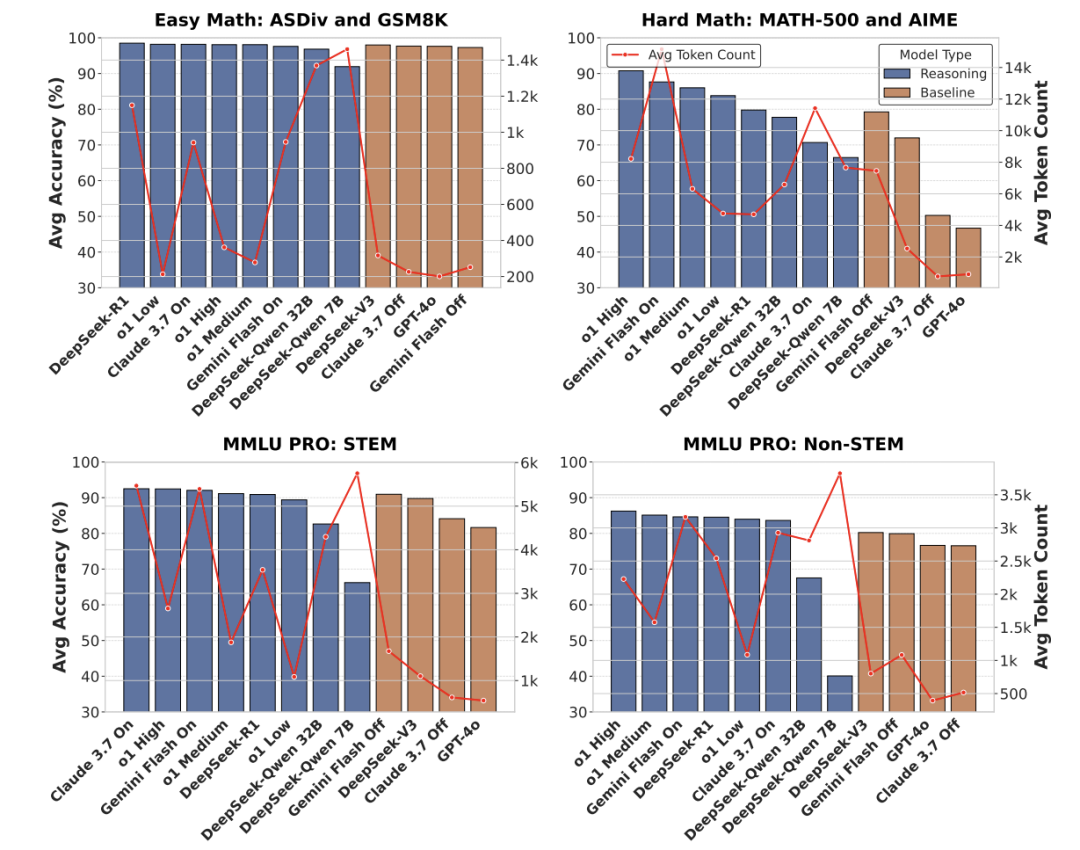
模型效率对比:蒸馏模型(紫色)token多且性能差 -
蒸馏模型(如DeepSeek-Quen 7B)输出最长但性能最差 -
RL微调模型(如DeepSeek-R1)token消耗↑5倍,但数学精度↑35% -
领域泛化:
过思考现象在非STEM任务(如法律推理)同样显著,推翻”仅数学需优化”的假设。
应用场景与挑战
落地应用
-
实时系统:
自动驾驶中,L1控制确保200ms内响应(例:COT-Drive框架)。 -
多模态扩展:
长 度 惩 罚 -
FAST框架根据图像复杂度分配视觉推理预算 -
VLM-R1通过目标检测惩罚减少冗余输出:
核心挑战
-
奖励设计困境:
长度惩罚可能抑制关键推理步骤(如证明题的必要推导)。 -
硬件适配:
连续潜空间推理需专用加速器支持。
未来方向
-
混合架构:
融合直觉型(GPT-4o)与深度推理型(o1)模型,类似人脑快慢思考系统。 -
生成式推理:
扩散模型逐步细化答案,替代传统自回归生成。 -
无奖励RL:
探索自监督信号替代人工设计奖励(如预测自身推理成功率)。
结论
本文系统化解构了LLM推理效率优化路径:
-
理论贡献:创立L1/L2双层框架,统一碎片化方法; -
技术突破:揭示蒸馏效率陷阱,验证RL动态分配的普适优势; -
产业价值:为实时AI系统提供可控计算范式。
未来需在跨模态适应性与训练轻量化方向突破,最终实现”一个模型适应所有场景”的终极目标。
(文:机器学习算法与自然语言处理)