


视频生成技术正经历跨越式发展:从早期只能生成几秒钟低质量片段,到如今能够输出数分钟高清视频。
在可控视频生成领域,除了 Text-to-Video(T2V)和 Image-to-Video(I2V)两个基础任务外,Subject-to-Video(S2V)成为新的研究焦点。S2V 的核心挑战在于平衡文本指令与参考图像内容——既要发挥 T2V 的创造性优势,又要突破 I2V 对输入图像的依赖。
现有 S2V 算法虽能保持主体外观一致,但其类似 T2V 的生成模式使得主体的运动形式呈现高随机性,导致目标动作呈现“开盲盒”式不可预测性。
针对这一难题,阿里云团队近期推出其 CVPR 2025 轨迹可控视频生成算法 Tora 的升级版 Tora2。该方案通过融合多主体参考图像与运动轨迹指令,同步实现视频中多主体外观一致性与轨迹可控性。目前,Tora2 已被 ACM MM25 收录,被领域主席推荐为 Oral。

论文链接:
https://arxiv.org/abs/2507.05963
项目主页:
https://ali-videoai.github.io/Tora2_page/
下图展示了 Tora2 的框架设计。在多主体视频生成中,环境和动作虽可变化,但主体核心身份特征需严格保持一致。
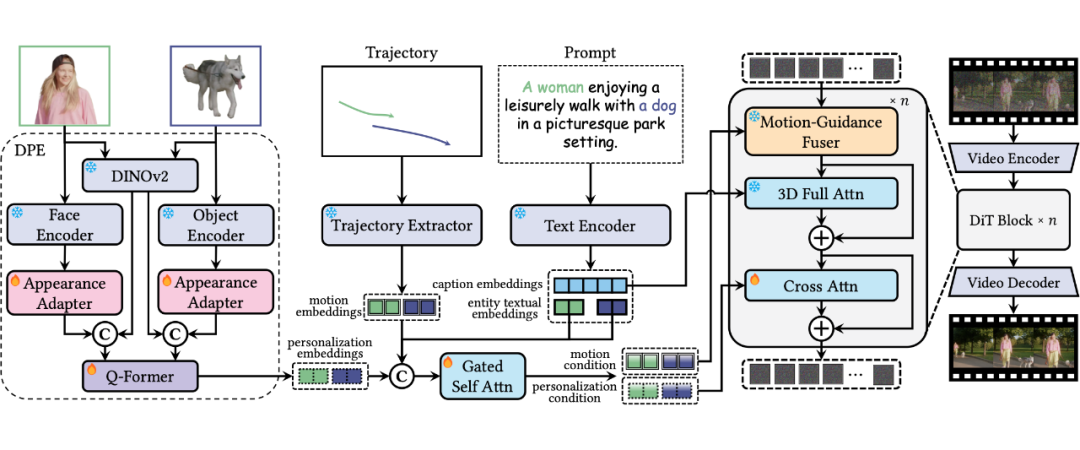
现有方案(如 Video Achemist、ConceptMaster)通过 CLIP/DINO 系列模型提取高阶语义特征实现跨场景生成,但因对高频细节(面部纹理等)感知不足,导致主体一致性受限。
针对此问题,Tora2 提出解耦式个性化提取器(DPE):在保留 DINOv2 高阶语义特征提取能力的同时,引入专家模型补充高频细节——针对人物和物体分别采用预训练的人脸识别特征针和重识别(ReID)特征,并通过两个适配器与 DINOv2 特征融合。
最终,Q-Former 对多源特征进行统一处理,既平衡了视觉基础模型与扩散模型间的差异,又通过参数冻结兼容性和特征密度优化,实现了紧凑的核心主体表征提取。
Tora2 在运动控制方面沿用了 Tora 架构,通过轨迹提取器(Trajectory Extractor)生成与 Video Diffusion Transformer(DiT)输入对齐的 motion embeddings。
为实现各个主体运动特征与视觉特征的绑定,Tora2 设计了门控自注意力层:输入包括主体的实体文本嵌入、运动嵌入及 DPE 提取的个性化嵌入,并通过动态门控机制调节各模态特征的权重。
随后,运动特征和视觉个性化特征分别由基于自适应归一化的 Motion-Guidance Fuser 和额外的交叉注意力层注入视频 DiT 模型中。
此外,Tora2 引入针对参考主体的运动-视觉对比学习,在多主体场景中增强特征判别性,提升运动路径与视觉表征的协同一致性,缓解由多主体多模态特征引导带来的歧义分配问题。
Tora2 在训练中继承了 Tora 的初始化权重,并融合 Tora 与 Video Alchemist 的视频筛选策略,构建包含 110 万视频片段的训练集(覆盖丰富主体类别与运动模式)。
评估体系包含三类指标:
1)基础质量指标(Text Similarity:生成视频与文本指令的 CLIP 相似度;Video Similarity:生成视频与测试视频的 CLIP 相似度);
2)外观一致性指标(Subject Similarity:主体 DINO 相似度;Face Similarity:人像 ArcFace-R100 一致性);
3)运动一致性指标(Trajectory Error:生成轨迹与目标轨迹的距离差异)。
在 MSTVTT-Personalization 上测试,Tora2 在个性化生成能力上与 Video Alchemist 持平,同时具备独有的轨迹控制优势。
Tora2 通过与两阶段方案(Flux.1 生成个性化图像 + Tora 生成视频)的定性对比验证了联合优化方案有效解决了分阶段生成导致的特征断层问题,使主体身份特征与运动轨迹实现深度协同。
(文:PaperWeekly)