


最近,已经开发出许多方法来扩展预训练的大型语言模型(LLM)的上下文长度,但它们通常需要在目标长度(>4K)进行微调,并且难以有效利用来自上下文中间部分的信息。
为了解决这些问题,我们提出了 CREAM(Continuity-Relativity indExing with gAussianMiddle),它通过操纵位置索引来插入位置编码。除了简单之外,CREAM 还具有训练效率:它只需要在预训练的上下文窗口(e.g., LLaMa 2-4K)进行微调,并且可以将 LLM 扩展到更长的目标上下文长度(e.g., 256K)。
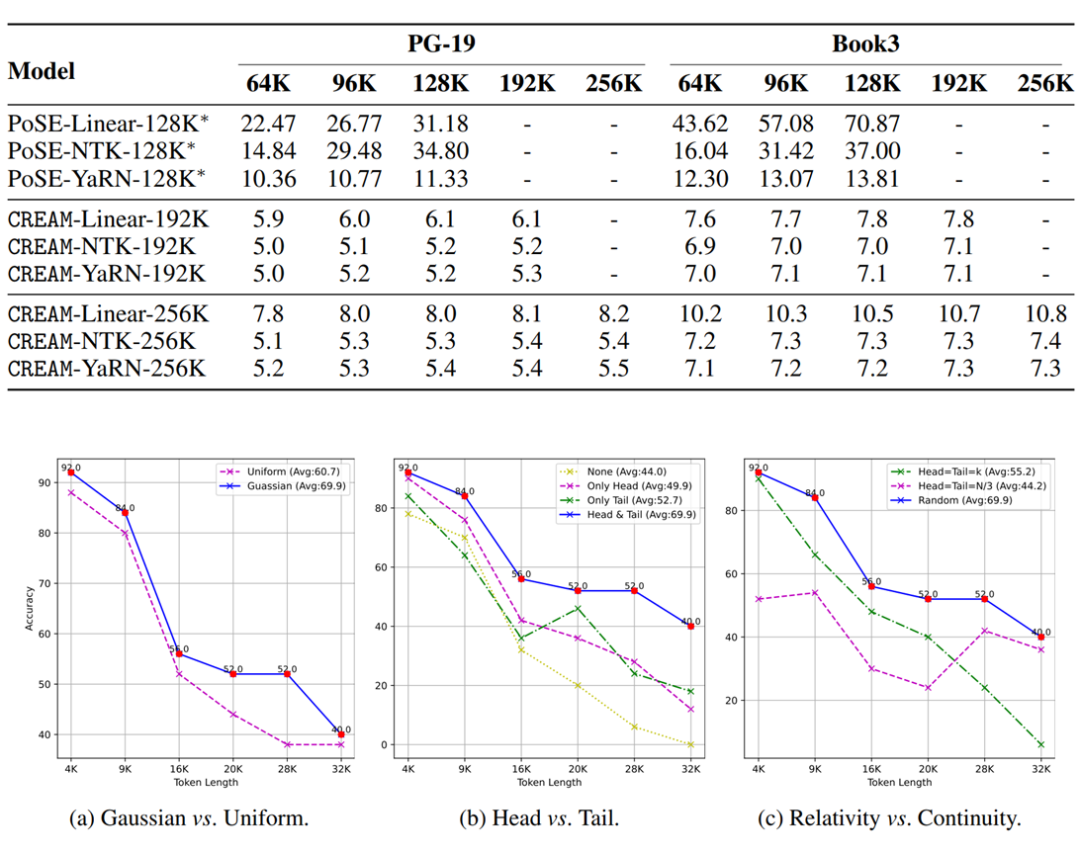
为了确保模型更多地关注中间的信息,我们引入了一个截断高斯来鼓励在微调过程中从上下文的中间部分进行采样,从而缓解长上下文 LLM 面临的 “Lost-in-the-Middle” 问题。实验结果表明,我们的方法成功扩展了 LLaMa2-7B base 和 chat,并且实现了 “Never Miss A Beat”。

论文地址:
代码地址:

Introduction
基于 Transformer 的大型语言模型(LLM)通常使用固定的上下文窗口大小进行预训练,例如 LLaMa2 中的 4K 个 tokens。然而,许多下游应用(包括 in-context learning 和 LLM agents)需要处理更长的上下文,例如最多 256K 个 token。
最近的研究提出了一些方法,通过在短时间内微调插入位置编码(PE)来有效地扩展预训练 LLM 的上下文窗口。与高效 Transformer 和内存增强等其他技术不同,基于 PE 的方法不需要改变模型的架构或合并补充模块。因此,基于 PE 的方法具有直接实施和快速适应的优势,使其成为在涉及更大上下文窗口的任务中扩展 LLM 操作范围的实用解决方案。
尽管简单有效,但现有的基于 PE 的方法仍存在两个显著的局限性。
首先,先前的方法(例如位置插值)仍然需要对目标上下文窗口大小进行微调,这会带来相当大的计算开销。
其次,虽然一些 PE 方法已证明具有处理极长序列的潜力,这一点可以从较低的滑动窗口困惑度得分中看出,但它们的性能在“中间”场景中会明显下降。具体而言,当模型需要准确检索和处理位于扩展上下文中间的内容时,扩展窗口大小的性能会明显下降。
这些观察和见解强调了一个基本问题:我们能否有效地扩展预训练 LLM 的上下文窗口大小,同时优化其在处理“中间”内容时的有效性?
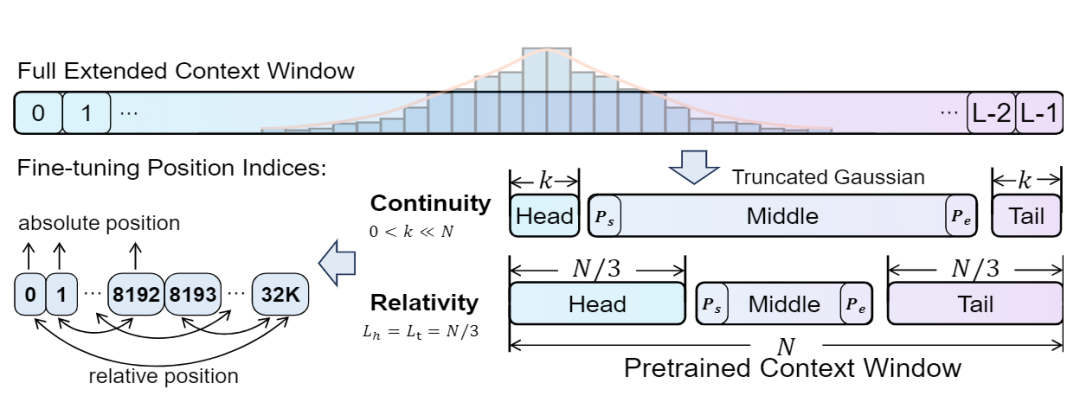
为了回答上述问题,我们提出了 CREAM,即 \oursfull。CREAM 是一种基于 PE 的新型微调方法,既能高效地进行微调,又能有效地增强中间内容的理解。我们的关键见解在于操纵长目标序列的位置索引,以在预训练的上下文窗口大小内生成较短的序列。
我们总结了有效位置索引的两个关键要素:产生紧密连接的位置索引的连续性和揭示片段之间长距离依赖关系的相关性。CREAM 是一个结合两全其美的方案,通过分别引入连续性和相对性的两种索引策略。
此外,为了缓解 “Lost-in-the-Middle” 的挑战,我们引入了截断高斯分布进行中间段采样,使 LLM 能够优先考虑中间位置的信息,即使在预训练上下文窗口大小内执行位置插值时也是如此。
我们进行了全面的实验来证明我们的效率和有效性。我们用 CREAM 在 LLaMa 2-7B 上持续进行短时间的预训练,并将上下文窗口大小从 4K 扩展到 256K。此外,我们用 CREAM 在 LLaMa 2-7B-Chat 上进行了 100 步的 Instruction tuning,并获得了令人满意的结果。
我们强调我们的经验优势如下:
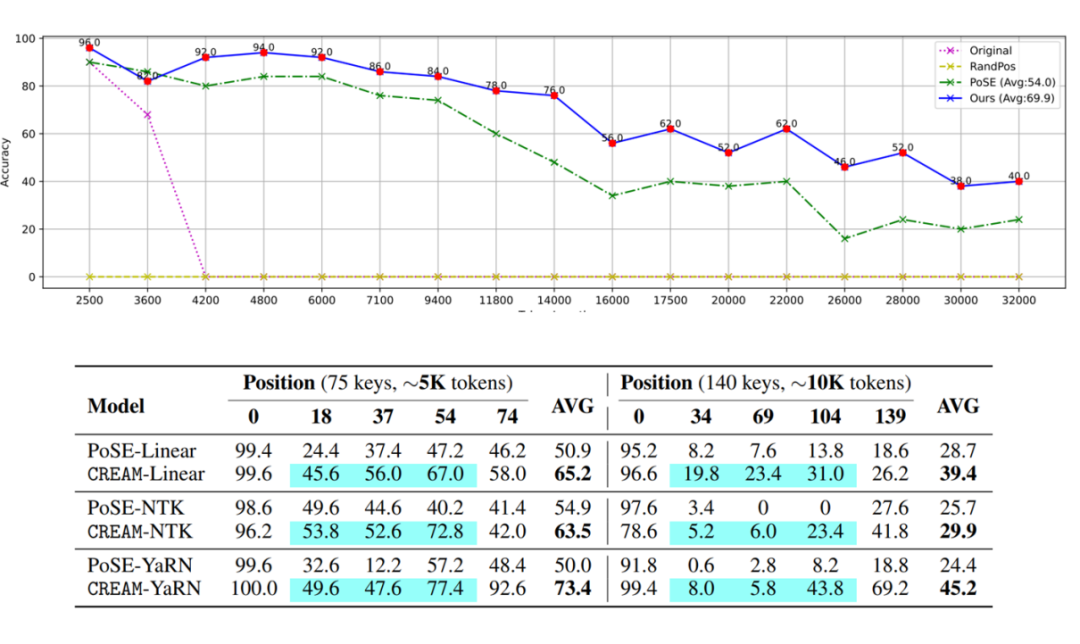
1. CREAM 不仅可以在训练前的上下文窗口大小内进行微调,还可以缓解模型容易在中途迷失的问题。e.g.,CREAM-YaRN 在 “Lost-in-the-Middle” 任务中平均比 PoSE-YaRN 表现好 20% 以上。
2. CREAM 可以通过在位置插值频率上集成新颖的设计(例如 Linear、NTK、Yarn、etc.)得到进一步增强,并且可以扩展到高达 256K 或更大的上下文窗口大小。
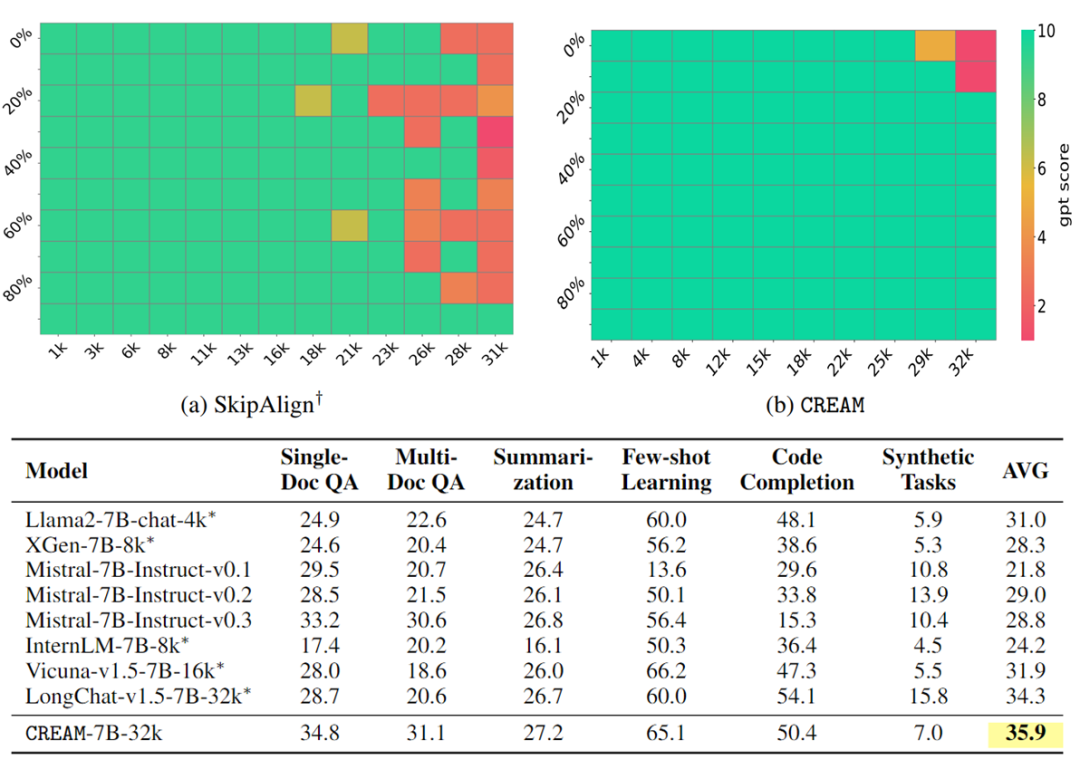
3. CREAM-Chat 模型仅需 100 步指令调优,便可在 Needle-in-a-Haystack 压力测试中实现近乎完美的性能,并且在 LongBench 上超越了现有的强基线。

Methodology

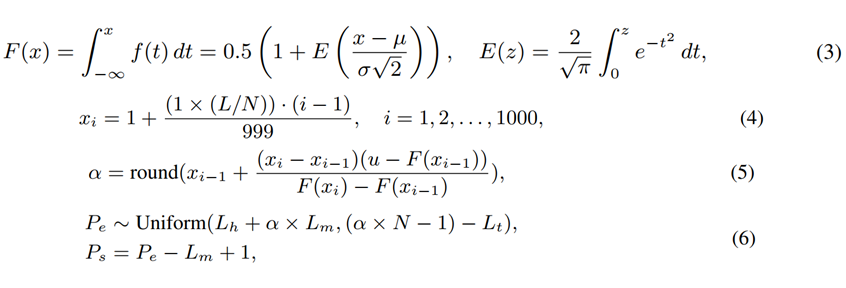

(文:PaperWeekly)