
无需标注数据!将Llama 3.3 70B调优到GPT-4o水平
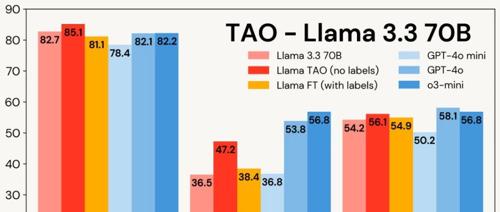
Databricks的TAO方法利用测试时计算和强化学习优化无标签数据,无需人工标注即可提升模型质量,降低成本。它在多个企业任务上提升了LLM性能,接近昂贵专有模型水平。
Databricks的TAO方法利用测试时计算和强化学习优化无标签数据,无需人工标注即可提升模型质量,降低成本。它在多个企业任务上提升了LLM性能,接近昂贵专有模型水平。

最近提出的方法通过在短时间内微调插入位置编码(PE)来有效地扩展预训练 LLM 的上下文窗口。然而,现有的方法仍存在两个显著的局限性:需要对目标长度进行微调,并且难以有效利用来自上下文中间部分的信息。为了解决这些问题,本文提出了 CREAM 方法,通过操纵位置索引来生成较短序列,在保持高效的同时增强模型在处理“中间”内容时的有效性。

CLIP 模型通过对比学习实现了视觉与文本的对齐。然而其文本处理能力有限,研究团队提出 LLM2CLIP 方法利用大语言模型提升 CLIP 的多模态表示学习能力,显著提升了 CLIP 在中文检索任务中的表现,并在复杂视觉推理中提升了 LLaVA 模型的表现。
