
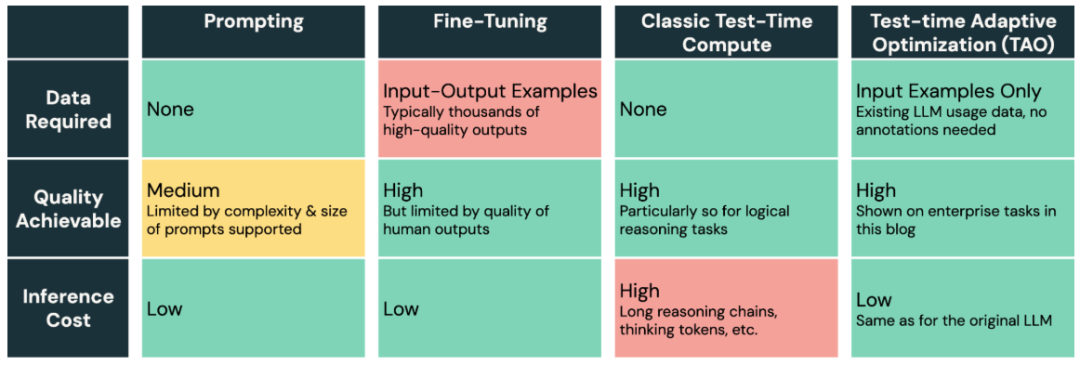
LLM 难以适应新的企业任务。提示工程易出错且效果有限,而微调需要大量人工标注数据,大多数企业任务无法满足。Databricks 推出的 TAO(Test-time Adaptive Optimization,测试时自适应优化)是一种新型模型优化方法,仅需无标签的使用数据,即可提升 AI 质量并降低成本。它利用测试时计算(如 o1 和 R1)与强化学习,让模型基于过往输入自动优化,无需人工标注,且调优成本可调节。尽管 TAO 使用测试时计算,但优化后的模型在推理时无需额外计算,保持低成本。
令人惊讶的是,即使没有标注数据,TAO的优化效果也优于传统微调,使低成本开源模型(如Llama)接近昂贵专有模型(如GPT-4o和o3-mini)。
TAO是 Databricks “数据智能”研究计划的一部分,旨在让 AI 利用企业已有数据提升特定领域能力。TAO 取得了三项重要突破:
-
在文档问答、SQL 生成等企业任务上,TAO 超越了基于数千条标注数据的传统微调,使 Llama 8B 和 70B 模型达到 GPT-4o 等昂贵模型的水平。
-
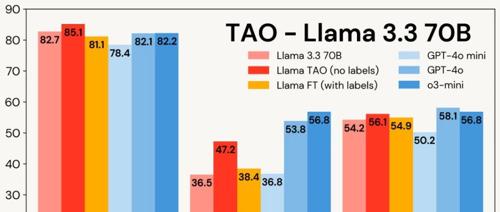
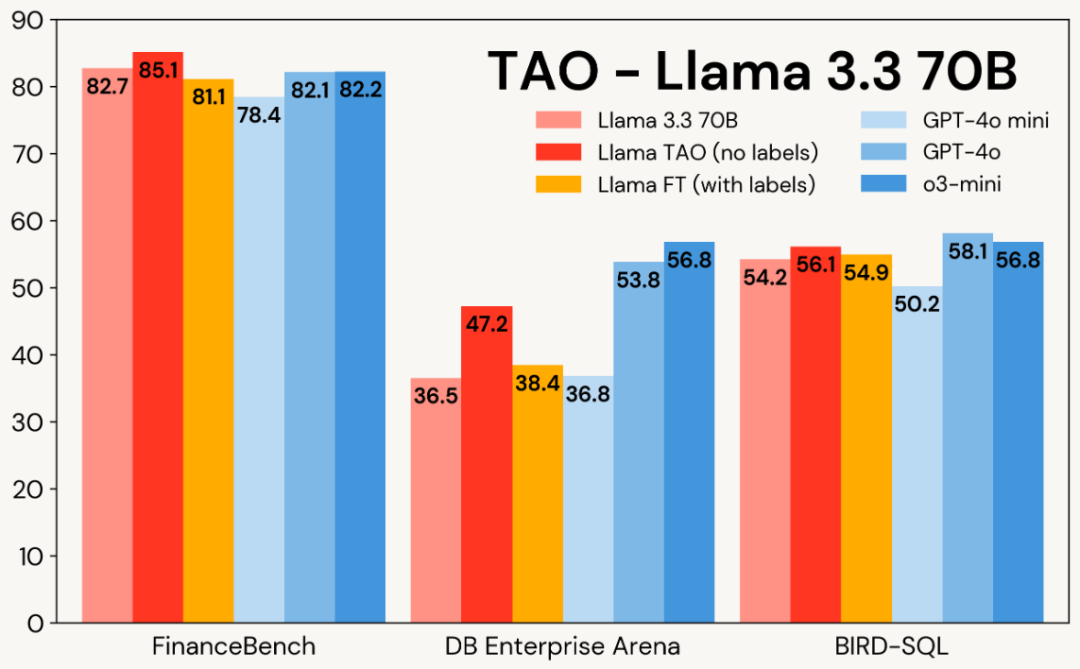
通过多任务 TAO,可在多个任务上全面提升 LLM 性能。例如,在企业基准测试中,TAO 使 Llama 3.3 70B 的性能提升 2.4%。
-
只需增加调优阶段的计算预算,即可提升模型质量,而最终推理成本不变。
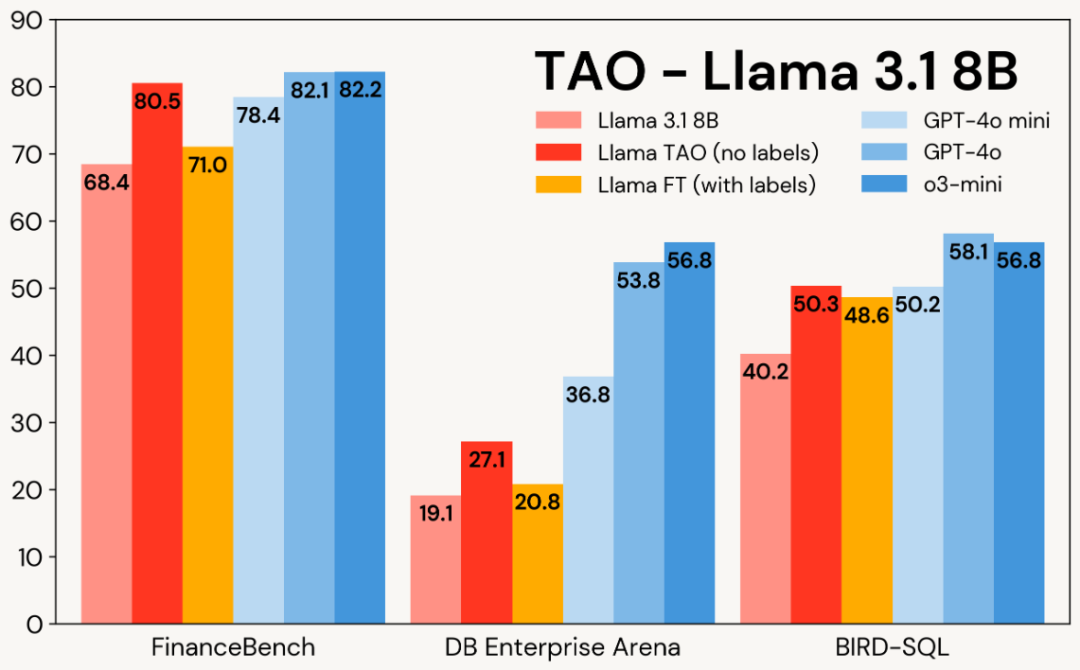
实验结果显示,TAO 在金融、数据库、SQL 等企业任务中,使 Llama 的性能超越传统微调,并接近昂贵的专有模型。
下图展示了 TAO 在 Llama 3.1 8B 和 Llama 3.3 70B 上的企业基准测试表现:TAO 在多个企业任务上显著提升模型质量,超越传统微调,并接近昂贵的专有 LLM。
TAO 如何工作?利用测试时计算和强化学习优化模型
TAO 的核心思想是不依赖人工标注数据,而是通过测试时计算探索任务的合理答案,并使用强化学习根据评估结果优化 LLM。这种方法依赖测试时计算,而非昂贵的人工标注,从而提升模型质量。此外,TAO 可以结合特定任务的规则进行定制,进一步优化效果。令人惊讶的是,在许多情况下,这种方法结合高质量开源模型,甚至能超越人工标注的微调效果。
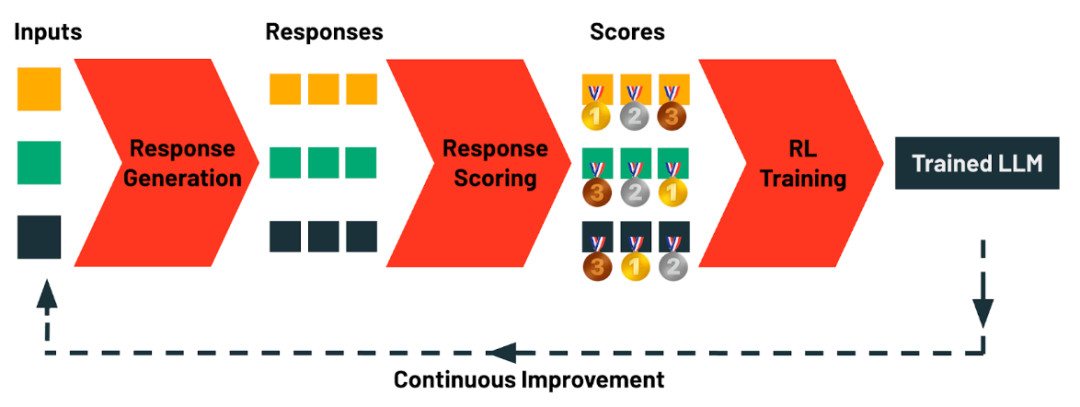
TAO包括四个阶段:
-
响应生成:收集任务的示例输入(如提示或查询),并自动生成多样化的候选响应,支持从简单的链式思维到复杂推理等不同生成策略。
-
响应评分:对生成的响应进行评估,采用奖励模型、偏好评分或任务特定验证(如LLM判定或自定义规则)来量化质量和匹配度。
-
强化学习训练:使用 RL 方法优化 LLM,使其更倾向于生成高分响应,提高整体质量。
-
持续优化:LLM的使用数据自然形成训练数据,随着使用增加,TAO 不断优化模型,无需额外标注。
尽管 TAO 使用测试时计算,但优化后的模型推理成本与原模型相同,远低于 o1、o3和 R1 等测试时计算模型。实验表明,TAO 优化的开源模型可在质量上挑战顶级专有模型。
相比提示工程(易出错且低效)和传统微调(依赖昂贵人工标注),TAO 仅需提供任务的示例输入,即可实现优质优化,为 AI 调优提供了强大新工具。
TAO 具有高度灵活性,可按需定制,但在 Databricks 的默认实现已能高效适配多种企业任务。其核心是团队开发的强化学习和奖励建模技术,使 TAO 通过探索学习并利用 RL 优化模型。例如,TAO 采用专为企业任务训练的自定义奖励模型 DBRM,可在广泛任务中提供精准评分信号。
DBRM 表示 Databricks Reward Model,是 Databricks 专为企业任务训练的自定义奖励模型。它用于在 TAO 过程中对模型生成的响应进行评分,提供准确的质量评估信号。DBRM 可以适用于多种企业任务,确保 TAO 能够有效优化 LLM,使其输出更符合任务需求。
使用 TAO 提升任务表现
我们使用 TAO 优化 LLM 在企业专用任务上的表现,选取了三个具有代表性的基准测试,包括开源和 Databricks 自研的 DIBS(Domain Intelligence Benchmark Suite)。

我们对比了多种方法:
-
原始 Llama 模型(Llama 3.1-8B 或 Llama 3.3-70B)直接使用,无优化。
-
Llama 微调,使用或构建包含数千条示例的大规模数据集,如:
-
FinanceBench:7200 条关于 SEC 文档的合成问题
-
DB Enterprise Arena:4800 条人工编写的输入
-
BIRD-SQL:8137 条训练数据,调整为 Databricks SQL 方言
-
TAO 优化 Llama,仅使用微调数据集中的输入(不使用输出),并结合 DBRM 奖励模型优化。DBRM 未针对这些基准测试单独训练。
-
高质量专有LLM,如 GPT-4o-mini、GPT-4o、o3-mini 等。
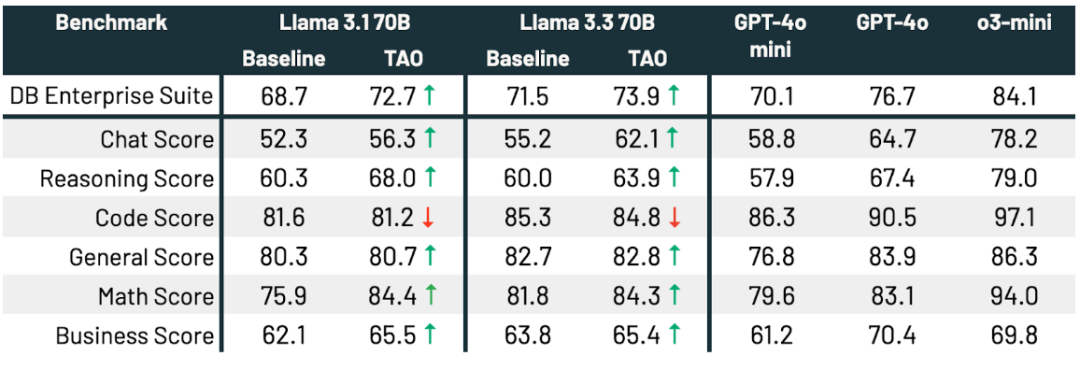
结果:如下表所示,在所有三个基准测试和 Llama 模型上,TAO 不仅显著提升了Llama的基础性能,甚至超过了传统微调方法。

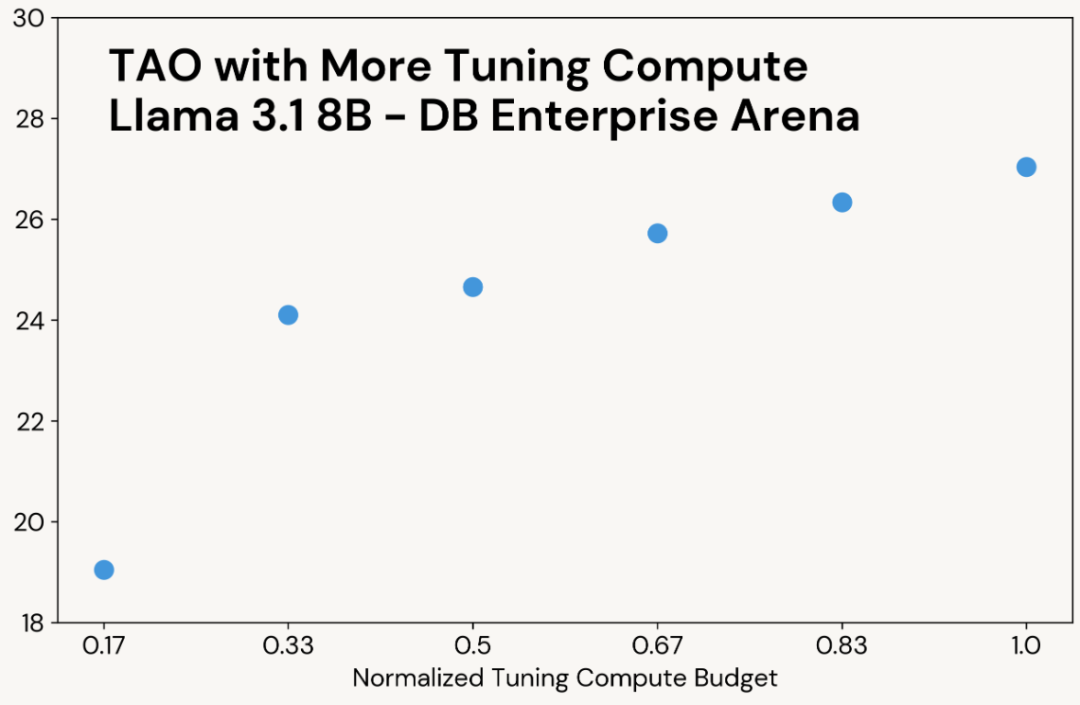
与传统测试时计算(Test-Time Compute)类似,TAO 在分配更多计算资源时能产生更高质量的结果。但不同的是,这些额外计算仅用于调优阶段,最终模型的推理成本与原始 LLM 相同。例如,o3-mini 在任务中生成的输出 token 数量是其他模型的 5-10 倍,推理成本也相应更高,而 TAO 优化后的 Llama 模型推理成本保持不变。
TAO 提升多任务智能能力
此前,我们使用 TAO 优化 LLM 在单一任务(如 SQL 生成)上的表现。然而,随着智能体复杂度的提升,企业越来越需要能执行多种任务的 LLM。本部分展示了 TAO 如何全面提升模型在企业任务中的表现。
在实验中,我们收集了 17.5 万条企业任务相关的输入,涵盖编程、数学、问答、文档理解和聊天等多个领域,并对 Llama 3.1 70B 和 Llama 3.3 70B 进行 TAO 优化。随后,我们在多个企业相关基准测试(如 Arena Hard、LiveBench、GPQA Diamond、MMLU Pro、HumanEval、MATH)及内部评测集上进行测试。
结果:TAO 显著提升了模型表现,Llama 3.3 70B 提升2.4个百分点,Llama 3.1 70B 提升 4.0 个百分点,并使 Llama 3.3 70B 在企业任务上的表现更接近 GPT-4o。这些提升无需人工标注,仅依赖代表性 LLM 使用数据和 TAO 优化。此外,所有子任务得分均有所提升,除编程任务外(性能保持不变)。
https://www.databricks.com/blog/tao-using-test-time-compute-train-efficient-llms-without-labeled-data
(文:PyTorch研习社)