

先来做个小调研:
不知你是否有所发现:和AI 对话越长,它的表现似乎会越差?
甚至,除了回答质量直线下降,回复速度还会越来越慢——
这不是错觉,而是长对话的必然结果!
今天就来简单聊聊这个问题:
长,就好吗?

据我观察,不少人喜欢在同一个对话窗口里与AI多轮长聊
不断追问
这样确实简单省事,还能复用之前的上下文
不用新开个对话重新开场
(尤其 i 人,最怕的就是开场了吧
但事实上,这种方式会影响 AI 的表现。
先放结论:
长,未必就好!
再说原因——
这是因为和LLM 进行长对话,会有着如下问题:
1. 速度变慢
巨大的上下文窗口对应更多的token
这将消耗更多计算资源,响应速度自然会变慢。
2. 效果大打折扣
长对话会或多或少夹杂混杂、矛盾的信息
这会让模型困惑

在体育话题中突然聊烧烤,再突然插入一个AI 话题,然后又再聊会姚明……
虽然可能没多少人会这像我这样对话

但本质上可能差不多,我只是夸大了些而已
这就像让一个人同时做十件事
结果,可想而知
3. 信噪比降低
过多的token 会一起争夺有限的注意力
这会造成 “注意力分散”
从而降低模型性能。

就好比在男朋友正和老板电话时问他“你爱我哪一点?”
很难会得到想要的答案
4. 智能「分辨率」下降
现在模型的上下文窗口正变得越来越长
从GPT2 的1K 到4K、8K、16K、32K、128K、200K,甚至500K、1M
但并不代表什么都往里塞就好
模型的理解能力会随着长度而下降
也会随着内容的纯度而下降
5. 训练数据不匹配
原因很好理解
大多数模型的训练数据以短对话为主,甚至是单轮问答
即(一个问题 -> 答案)
多轮超长对话对AI 来说就像让你读一本用陌生语言写的书,生疏且困难。
一个巨大的超多轮对话将迫使LLM进入一个新的数据分布
而它在训练期间根本就没怎么见到过长这样的东东
很难不懵
你可能会想,那多标点这样的数据不就好了吗?
事实上,你不是第一个想到的
但没有大规模这么做,这在很大程度上是因为——
6. 数据标注困难
目前LLMs 仍主要且非常基本地依赖于人工监督。
而打标的人(即标注员,或工程师)可以较好理解简短的对话,并写出最佳响应或对其进行排序
或者检查LLM裁判是否做对了
但很难有人能为几十万字的对话写出「最佳回答」,而且还是风牛马不相及的大锅炖

最近有篇名为《NOLIMA: Long-Context Evaluation Beyond Literal Matching》的论文
也是直接给当前LLMs 的超长对话判了死刑:
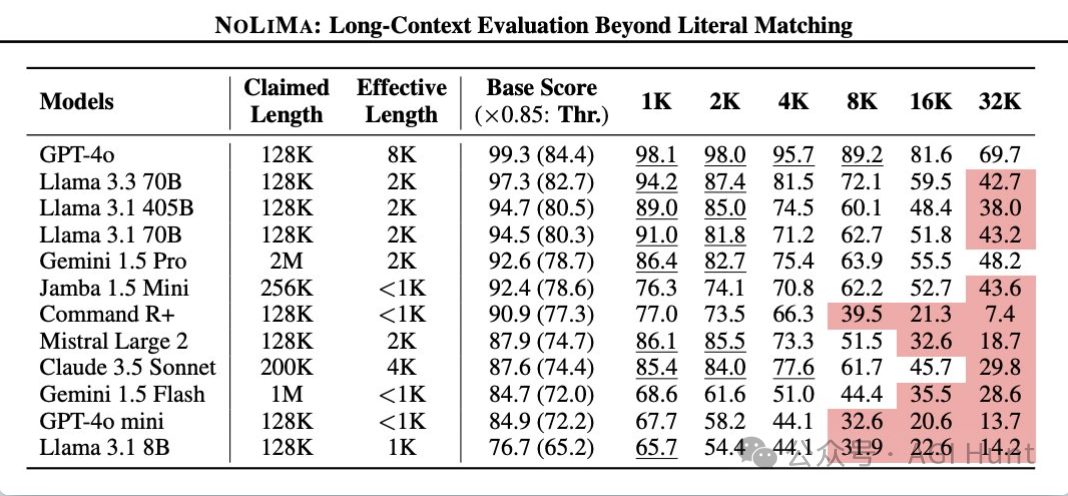
论文地址:arxiv.org/pdf/2502.05167
该研究指出:
-
性能随上下文长度增加而下降。即使像GPT-4o这样的顶级模型,在短对话中表现近乎完美,但文本扩展后也会遭遇滑铁卢。在32K令牌时,大多数模型性能降至短上下文时的50%以下!
-
表面级关键词匹配成为模型的依赖,当这些线索被移除时,性能直线下降。
-
多步推理能力在长对话中严重受损。
-
注意力分散导致模型被肤浅的信息误导,而非进行真正的推理。
此外还有个一因素:
长对话带来的大量计算还造成了不必要的环境成本,增加了碳排放——
7. 极不环保啊♻️
不过,虽然长未必就好
但只要你觉得好用
尤其是简单任务

偶尔乱一下,长一下也没关系
影响不会太大
方便就好
而面对用户们天然会越聊越长的习惯
太长,该怎么办?
各家模型厂商/应用公司也各有不同的处理:
Claude 会直接提醒你超出了上下文窗口限制:
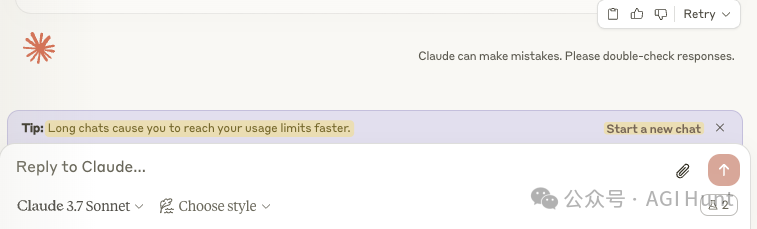
而Claude Code 推出的auto-compact功能是我见过的第一个能显式提供对话压缩的工具

它能自动压缩对话历史,在保留重要信息的同时减少token 使用。
ChatGPT 最近也调整了策略
当对话达到一定限制,它会停止对话并提示创建新对话。
这似乎是后加的调整——
之前似乎能无限长进行对话,且从结果上能明显感受到它使用了RAG 和滚动窗口相关的、机制
或许仍还此机制(未进行精准token 上限测试),只是同时加上了最大上下文的限制
(能rag,但过长时效果会差的没法忍?)
Grok 则(显得)采用了更长的上下文体验
似乎也是利用RAG 和summarize 相关策略来支持超长对话窗口
虽然有时的正确用法是开新对话,但大部分人未必会如此使用
Grok 通过一些优化更好地迎合了人们的使用习惯,也收获了颇多网友好评。
再来说说AI 编程工具Cursor
相比之下,它显得更不擅长在聊天之间保持上下文
我用下来的感受是:混乱、丢失很常见
原因很好理解——Cursor 节省成本带来的副作用
Cursor 团队在播客中有提到他们有本地模型/云端自研模型来评估每次请求需要的内容
来达到速度、成本、效果的最佳平衡
虽然钱省了
但自然也会导致——
不够准
而我的经验是,
若在Cursor 中新开聊天,需要提供更多的上下文信息和参考的文件、要修改的文件、修改思路
才能得到较好的效果
否则可能还不如在原窗口追问,效果反而还更好一些
而Devin 也有这方面的考量
在我和Devin 进行较长的多轮对话后,Devin 也会贴心建议新开会话
以得到更快的速度和更少的ACU 消耗(省钱)
和更好的效果(更准确的意图理解和执行结果)
你可能要问了:
长对话有这么多问题,那有什么正确使用姿势吗?
每次都新开个会话吗?
或者什么时候继续对话,什么时候使用新会话呢?
以及先前对话都不能复用了,那不是一切要从头开始聊了吗?
也挺麻烦的不是?
那我们应该如何与LLM对话才能获得最佳效果呢?
这里给出我的
12 个小小心得分享
1. 避免过长
在和AI 对话时(写prompt 时),要用词精炼
能用10个字的不要用50字,能用词的不要用句
减少重复,精准紧凑,少说废话。
当然,要是就问一两轮的简单任务
那你随意
2. 总结后再开始
与AI 对话有点像与人交谈
当我们聊着聊着,很容易会因跑题而不够聚焦
有时需要重新回归主题,有时则需要针对某个衍生的新话题重新开聊
这就需要定时将主题明确和聚焦,与对方对齐:「嗯,我们在说什么来着?」
而对应到与AI 的对话中,则是——
当对话较长时,可以让AI 写一份详细摘要、重要事实和待办事项,然后开始新对话。
这里分享个提示词供参考:
「总结整个对话,对所有涵盖的主题给予同等的权重,无论何时讨论,都保持其完整的上下文。保留您在这次聊天中的回复格式、语气和对话风格,这样如果我要在新的会话中重新开始,感觉就像我在继续这次对话中的相同版本。」
3. Cursor 未必是最好的Coding 工具
虽然Cursor 已经成了我每天必用的工具
(其实不限于coding
但由于Cursor不想(为了省钱)在聊天中保持较长的上下文
在涉及某些中大型项目或某些复杂的编程任务时
我还是会使用Claude
可以使用Claude Code 来完成
而如果开了Claude 会员且想省点钱避免API 开支
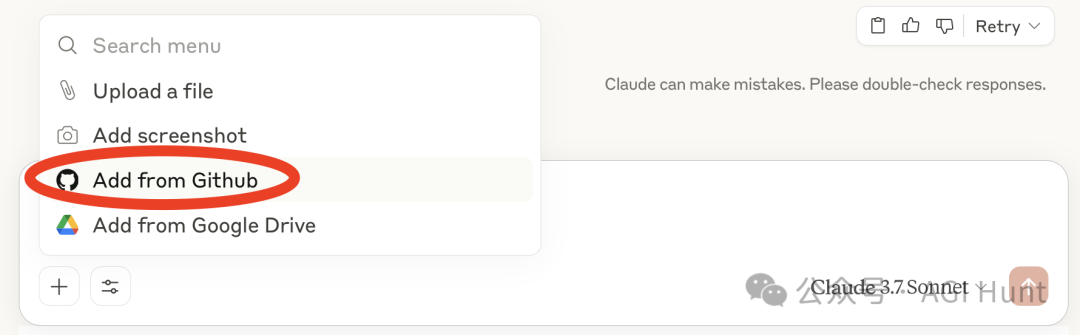
也可以将项目的GitHub 在Claude 工作台中绑定后对话
有时会比直接用Cursor 好很多
4. 任务分流
每当有新想法或新任务时,打开新对话
而需要用到上下文时,找到之前的对话追问。
5. 一次性问题
一次性问题,我通常会在新对话中问
且通常会在完成后存档删除

如果用的是ChatGPT,还可以使用临时聊天功能来省掉删除的成本。
6. 使用改进版的prompt
如果初版prompt有问题,一种方案是追问修正,另一种是修改为v2版本从头开始
我会使用后者
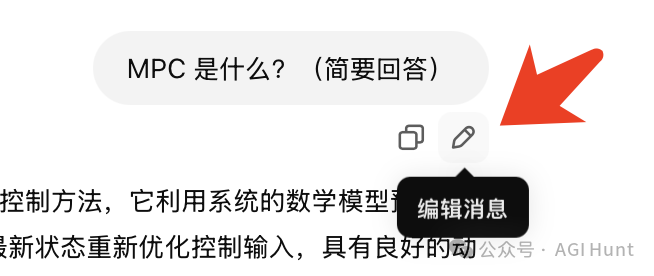
比如问MCP 是什么,如果一开始打错成了MPC,可以追问来调整

也可以修改原prompt 来调整
7. 重命名对话
对话完成后,ChatGPT 和Claude 会自动为对话起名
DeepSeek 和Grok 也会有
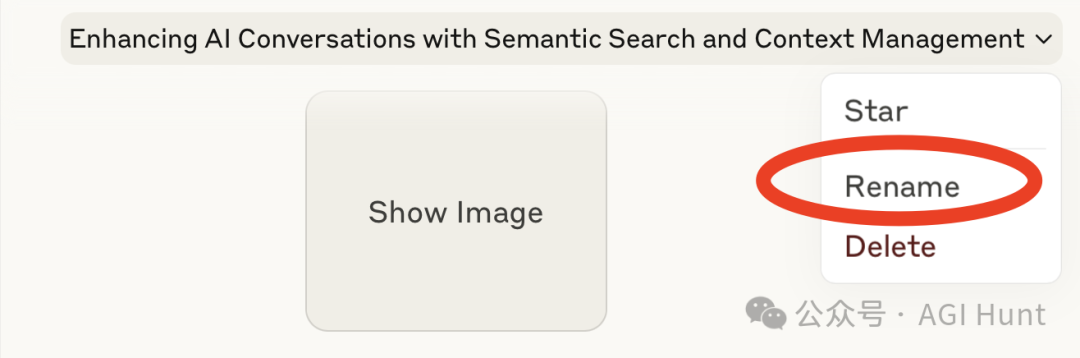
可以便于后续寻找时的搜索
但有时取的名字很不好找——并不是很次都取得很好
而且Claude 取的都是英文名
就会导致对英语不熟悉的小伙伴,可能用中文对的话,想搜英文时得找好半天
因此可以对重要的对话,rename 一下
能便于你后续的记忆和查找
8. 书签功能

也可以使用书签功能,同样方便对常用对话的快速查找和重复使用
9. 使用projects 功能
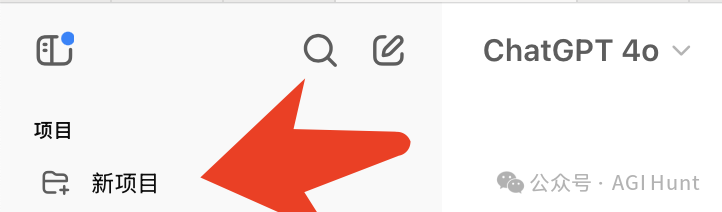
ChatGPT 和Claude 都提供了项目功能
可以试试把一些有共性/共同目标的对话放到同一个project 中
虽然不是必需,但会更方便管理
10. 分叉使用
如果你不知道什么叫分叉(我临时起的名字)
那请看下图(其实上面就展示过了):
也就是对多轮对话中的某一轮进行修改后重新提问
(当然,你也可以不改,而是让AI 重新回答
此时你与AI 的多轮对话就劈叉了
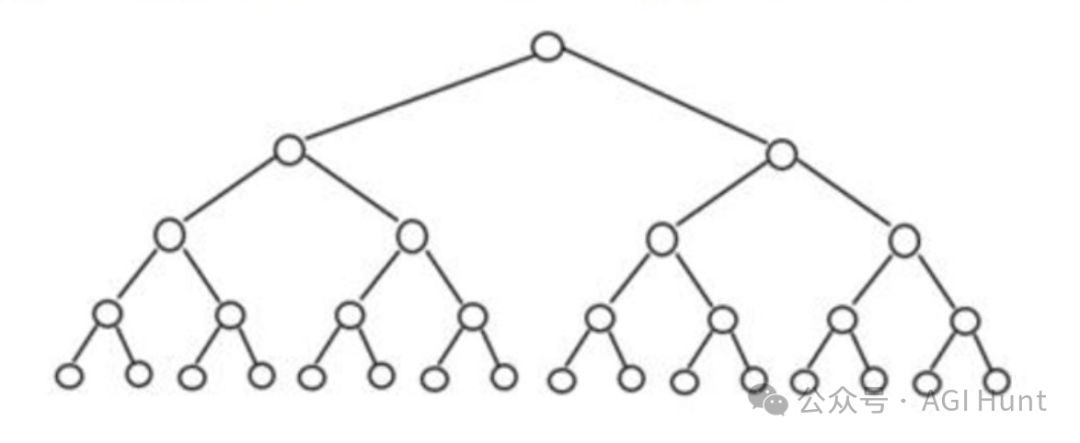
这有点像是平行宇宙——
在任何一个节点均可分叉独立进行演变且各自再无交集
数据结构上来说,则是个树状结果
各家工具都提供分叉功能
ChatGPT/Claude/Grok/DeepSeek…
比如看我与Claude 某个对话的劈叉:
这样看可能不够直观
我把数据导了出来做了个简单的可视化,长这样:

只是据我观察,似乎很多人更喜欢追问而非分叉使用
有人可能要问:
分叉有什么用?
我只能说——
如果你是认真读到这里,那就知道分叉相比追问好在哪里了
此外,分叉还有个用
11. 平替版GPTs
如果你有用过ChatGPT 的GPTs,那你应该好理解下面的公式:
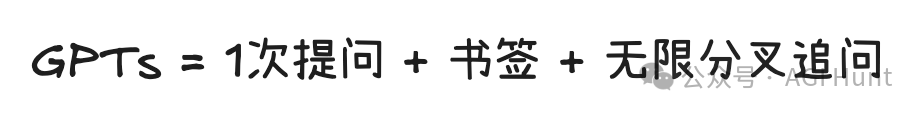
比如我用4o 来生成公众号封面的对话:


12. 分叉展示插件
而随着腿劈多了,不对,叉劈多了,自然就偶尔会想要找某一任前任再叙旧情
此时就会发现,找起来还挺麻烦
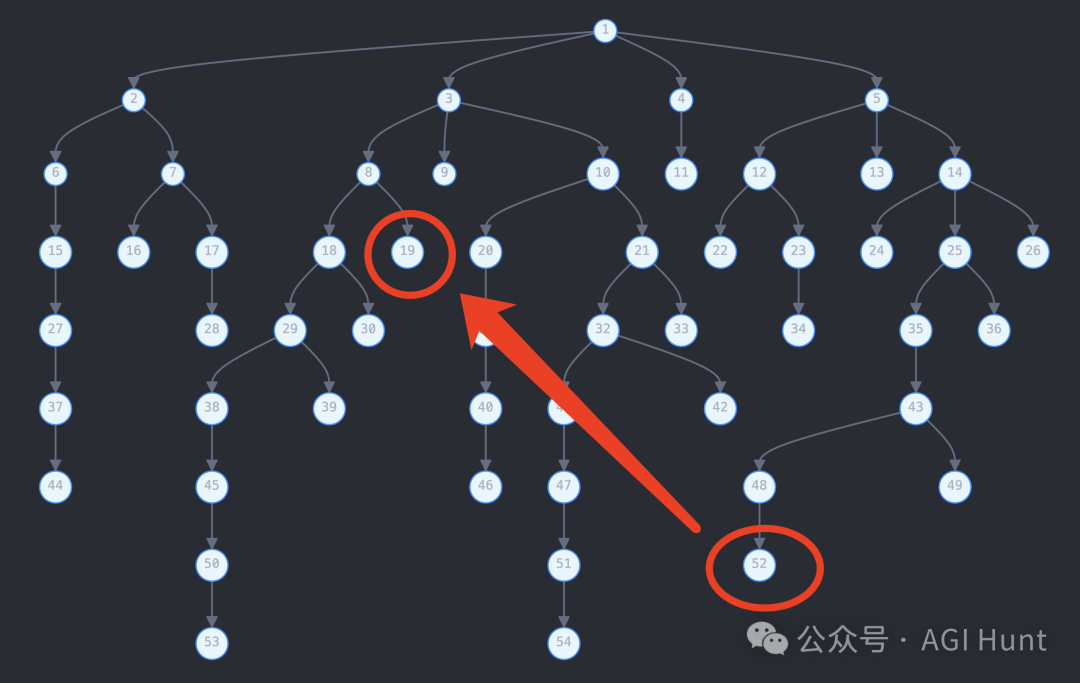
像上面这样的一棵大树
如果此时你在52 节点上,想要回到19 节点续旧
可想可知
这个任务不是脑子好就行
记忆也得好,还不能有幻觉!
为此,我还为自己量身制作了个插件(当然是用AI)来展示对话分叉
(目前仅支持Claude 和ChatGPT
插件会在Claude 和ChatGPT 网页的右下角添加一个按钮,长这样:
只需要点击一下,插件就会自动获取当前对话的整个树
并在新的tab 中展示(我的一个真实例子):

欢迎安装使用,插件地址见:
https://chromewebstore.google.com/detail/chatmind-visualizer/ikgckfehbaiphhbjoomnppcfdigamgca
(插件已过审上架,可放心食用)
目前只支持了我最常劈叉的两个平台
如果你有想要的平台,可以告诉我
我还有些其他的功能性小想法
就抽空一起加了
以上就是我12 个小小的心得分享
最后
也希望ChatGPT / Claude 们能多优化一下用户体验
包括但不限于下述一些
小建议
1. 更好用的搜索
在搜索历史对话时,不要只能搜索标题
再加个关键词搜索和语义结合的搜索,并不难啊
还有对话内容的搜索
随时有点很浪费服务端资源(倒排索引),但真的刚需
希望早点能用上
能节省我不少时间(虽然我现在会及时+书签有所改善
2. 精准的上下文管理
聚焦在最相关、最紧凑的内容上
不论是要省token 做RAG,还是要在超长上下文下也能让用户无感对话
请把RAG / summarize 做更好一些
3. 固定重要内容?
考虑在在多轮对话中,可以让用户将某一轮标记为「固定此内容」
这样在RAG 时可将其作为最重要的内容,保留在上下文中
4. 更好的分叉对话工具
原生支持分叉对话展示和劈叉追问、快速切换
其实功能都有了,就是不够方便
不要再让我开发插件了
以上
如果本文有让你有所收获
还请分享给你身边的人
此外
希望我只是抛砖引玉
欢迎在评论区分享你的经验
(文:AGI Hunt)