



研究背景与挑战
近年来,多模态大语言模型(MLLMs)在视觉推理领域取得了显著进展,展现出强大的视觉问答和视觉常识推理能力。然而,这些模型是否真正具备抽象视觉推理(AVR)能力仍是一个悬而未决的问题。
类似于解决数独谜题,抽象视觉推理需要在特定任务配置中识别和应用控制输入形状的高级模式。但现有的评估方法存在明显不足:评估范围过于局限,往往只包含简单的推理模式和基础图形;同时评估方法过于简单,无法有效区分模型的视觉感知能力和推理能力。

MARVEL数据集的创新设计
为解决这些问题,研究团队提出了 MARVEL 基准测试集。这个包含 770 个高质量测试样例的数据集建立在人类认知科学的基础之上,特别是核心知识系统理论。MARVEL 的设计突破了传统评估的局限,提供了多维度的测试框架,包括六种核心知识模式、多样的几何和抽象形状输入,以及五种不同的任务配置方式。

论文地址:
代码地址:
在具体实现上,MARVEL 的任务配置涵盖了序列、双行、矩阵、分组和重组等多种形式。这种多样化的配置设计使得评估更加全面和深入。例如,序列格式以 1×n 的线性方式排列面板,而矩阵格式则采用 3×3 的布局,可以同时测试行向和列向的模式识别能力。特别值得一提的是重组格式,它专门用于评估模型对 3D 几何的理解能力。

基于认知科学的知识体系
MARVEL 的一个重要特点是其建立在扎实的认知科学理论基础之上。该数据集围绕三类核心知识展开:对象核心知识关注物体的时空运动和接触特性;数字核心知识测试对小数字的抽象表示和比较能力;几何核心知识则评估对环境几何特征的理解能力。每类核心知识又细分为两种具体模式,从而形成了一个全面的评估体系。

实验评估与关键发现
研究团队对 10 个代表性的 MLLMs 进行了全面测试,包括 GPT-4、Gemini、Claude3 等闭源模型和 LLaVA-1.5、InstructBLIP、Fuyu 等开源模型。实验采用了零样本和少样本两种设置,并辅以提示工程优化。
实验结果令人深思:所有模型在 MARVEL 上的表现都接近随机水平,与人类表现存在约 40% 的显著差距。其中,闭源模型的平均表现(25.7%)略优于开源模型(24.0%)。
更深入的分析揭示了一个关键问题:模型的视觉感知能力可能是制约其表现的关键瓶颈。在提供准确的文本描述后,一些闭源模型(如 GPT-4V)展现出不错的推理能力,但其整体表现仍受限于较弱的视觉感知能力。这一发现表明,改进模型的视觉感知能力可能是提升其抽象视觉推理能力的关键。

未来展望与启示
MARVEL 的研究成果为我们指明了未来的研究方向。首先,提升模型的视觉感知能力是当务之急;其次,增强模型对抽象形状的理解和空间关系的推理能力也很重要。此外,研究团队也承认目前的工作存在一些局限性,如认知科学研究本身仍在不断发展,评估方式可能需要进一步优化等。
总的来说,MARVEL 不仅揭示了当前 MLLMs 在抽象视觉推理方面的局限,也为未来的改进提供了清晰的方向。这个基于认知科学的多维度评估框架,将推动抽象视觉推理研究的深入发展,为实现真正的视觉智能迈出重要一步。
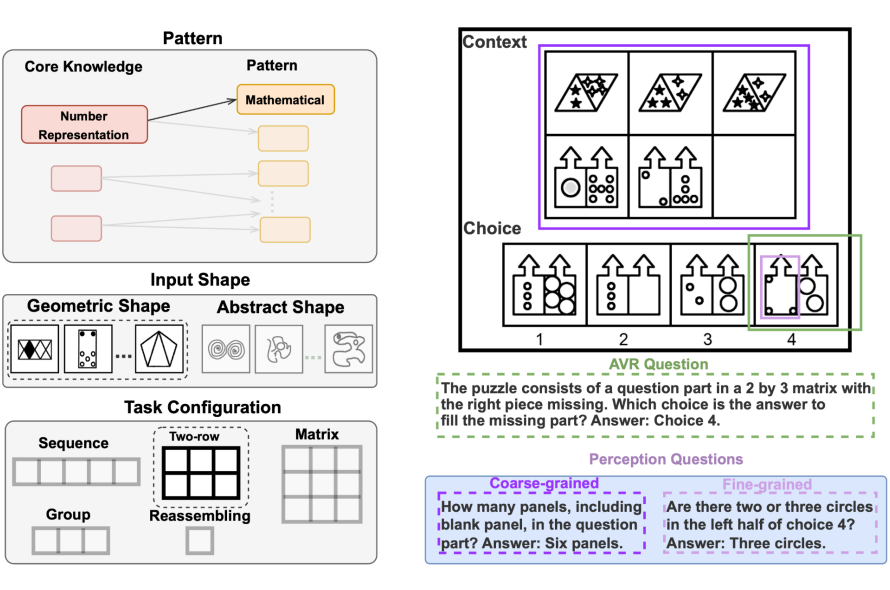
MARVEL 中的抽象视觉推理难题:通过两行任务配置展现几何图形中由数学模式控制的元素数量变化。AVR 问题关注最终答案,而感知问题聚焦单个选项细节或整体特征。例如,左侧黑色元素逐步递增 1,右侧白色元素在第一面板中的数量等于第二和第三面板之和。
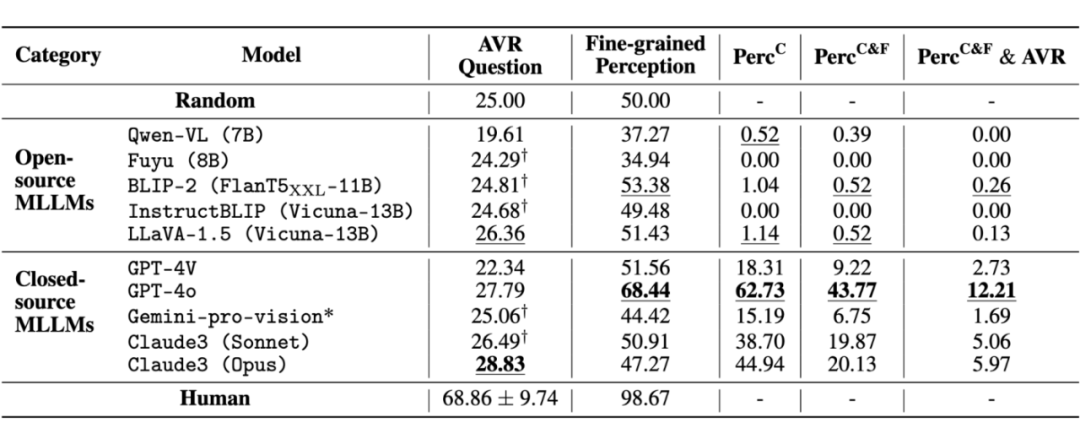

增加文本描述后,闭源大模型的表现可以获得显著提升,这一结果进一步说明基础视觉感知能力是当前多模态大模型能力的一大瓶颈。
(文:PaperWeekly)