


当前 AI Agent 的构建存在哪些误区?如何才能构建真正有效的 Agent? 本文将为你揭秘 Anthropic 的独家发现和最佳实践。从重新认识 Agent 的本质,到深入解析五大基础工作流模式和自主 Agent 的构建要点,再到分享客户支持和代码开发两大真实场景应用实践,最后提炼出工具设计、框架选择的最佳实践和未来展望。 本文将带你告别炒作,直击构建有效 Agent 的核心,无论你是 AI 新手还是资深专家,都能从中获得宝贵的启示和实用的指导。记住:简单、透明、注重 ACI,才是构建有效 Agent 的不二法门!
开篇:Agent 系统的迷思
当下,AI Agent 无疑是人工智能领域最炙手可热的话题之一。 从自动化任务到复杂决策,Agent 被寄予厚望,似乎无所不能。然而,在光鲜亮丽的表象下,许多 Agent 系统的实际效果却差强人意。 不少开发者盲目追求复杂性,陷入了“功能越多越好”、“系统越复杂越强大”的误区, 结果却往往事与愿违,构建出的 Agent 效率低下、难以维护,甚至漏洞百出。
那么,问题究竟出在哪里? Anthropic 通过大量的实践和研究发现,许多开发者对 Agent 的本质缺乏深刻的理解,在构建过程中也缺乏系统性的方法论。 他们往往被各种花哨的框架和工具所迷惑,而忽略了构建有效 Agent 的真正关键:对任务的深刻理解、对模型能力的清晰认知,以及对工具的精心设计。
重新认识 Agent
Agent 的本质定义
在深入探讨如何构建有效的 Agent 之前,我们需要先厘清 Agent 的本质。Anthropic 将所有具备智能化、自主化特性的系统都归类为 “Agent 系统”。然而,这其中又可以进一步细分为两种关键架构:
-
• 工作流 (Workflows): LLM 和工具在预定义的代码路径下协同工作。 这种模式下,LLM 的行为相对受限,更多地扮演执行者的角色,按照预设的流程完成任务,如同“提线木偶”。 -
• 智能体 (Agents): LLM 拥有更大的自主权,可以根据任务需求动态调整策略和工具使用。 这种模式下,LLM 更像是一位“指挥官”,能够根据实际情况灵活决策,自主完成任务。
Workflow vs Agent:关键区别
工作流和智能体的核心区别在于 LLM 的自主程度。 工作流更适用于那些任务明确、步骤固定的场景,而智能体则更适合那些需要灵活应变、自主决策的复杂任务。
何时需要 Agent?
并非所有任务都需要构建复杂的智能体系统。 在许多情况下,简单的解决方案反而更有效。例如,对于一些简单的问答任务,优化单个 LLM 调用的提示和上下文就足以获得满意的结果。盲目追求构建智能体,可能会导致不必要的成本增加和性能下降。
性能与成本的权衡
构建智能体系统往往需要牺牲一定的延迟和成本,来换取性能的提升。 因此,在决定构建智能体之前,我们需要仔细考虑这种权衡是否值得。对于那些任务明确、步骤固定的场景,工作流可能是更好的选择。而对于那些需要灵活决策和自主性的复杂任务,智能体才能发挥其真正的潜力。
Agent 系统的构建模块

1 基础:增强型 LLM
增强型 LLM 是构建 Agent 系统的基石。 通过集成检索、工具和内存等增强功能,我们可以显著提升 LLM 的能力,使其能够处理更复杂的任务。
-
• 核心能力: 理解自然语言、生成文本、执行代码、进行推理等。 -
• 关键增强点: -
• 检索: 使 LLM 能够访问外部知识库,获取所需信息。 -
• 工具: 使 LLM 能够调用外部工具,执行特定操作,例如计算、查询数据库等。 -
• 内存: 使 LLM 能够记住之前的对话或操作,从而实现更连贯的交互。 -
• 实现方式: Anthropic 推出的模型上下文协议 (Model Context Protocol, MCP) 提供了一套标准化的工具集成方案,只需简单的客户端实现,即可连接丰富的第三方工具生态,让你的 LLM 如虎添翼!MCP 就像一个“万能插座”,让 LLM 可以轻松连接各种数据源和工具,从而执行更加广泛的任务。 -
• 模型上下文协议 (MCP) 链接:https://www.anthropic.com/news/model-context-protocol -
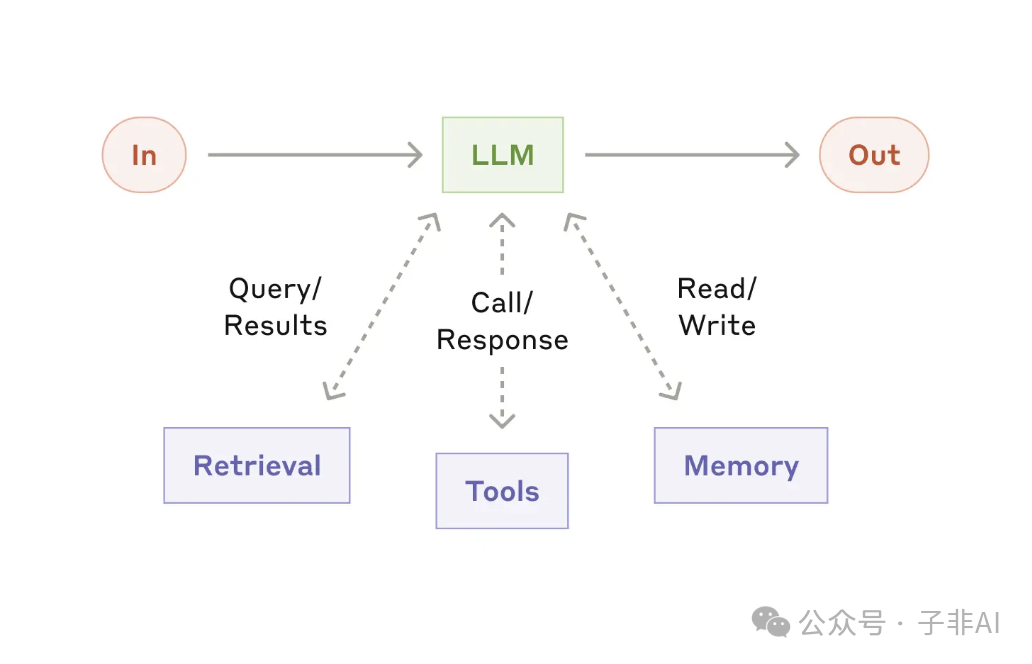
图:增强型 LLM
2 五种基础工作流模式
基于丰富的实战经验,Anthropic 总结了五种构建 Agent 系统的基础工作流模式:
-
• 提示链 (Prompt chaining): 将复杂任务分解成一系列简单的步骤,每个步骤都由一个 LLM 调用处理,前一步的输出作为下一步的输入,环环相扣,最终完成整个任务。 这种模式特别适合那些可以清晰拆解的任务。 -
• 适用场景:营销文案生成、文档大纲撰写等。
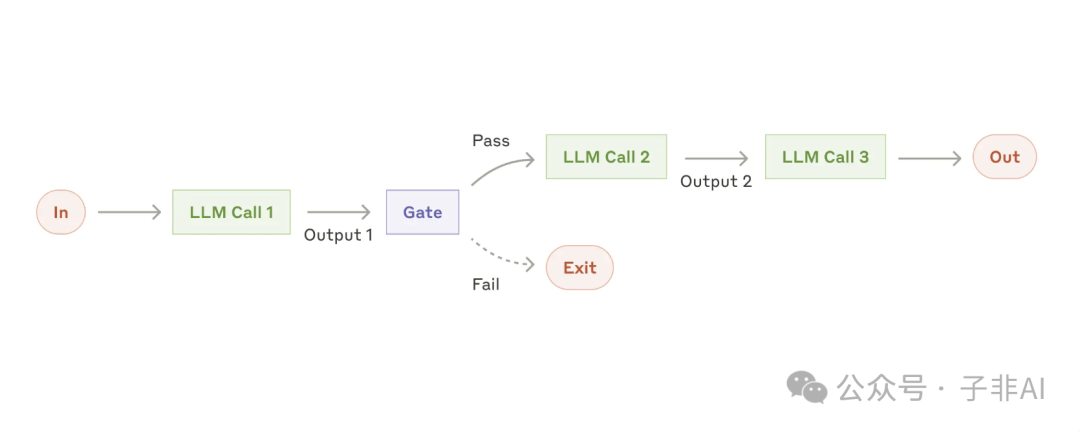
图:提示链,将复杂任务分解成多个步骤,每一步都由一个 LLM 调用处理,让复杂问题迎刃而解
-
• 路由 (Routing): 根据输入的类型将其分配给最合适的“专科医生”。 这种模式可以实现关注点分离,构建更加专业、高效的系统。 -
• 适用场景:客户服务、模型选择(例如,根据任务的复杂性选择 Claude 3.5 Haiku 或 Claude 3.5 Sonnet)等。
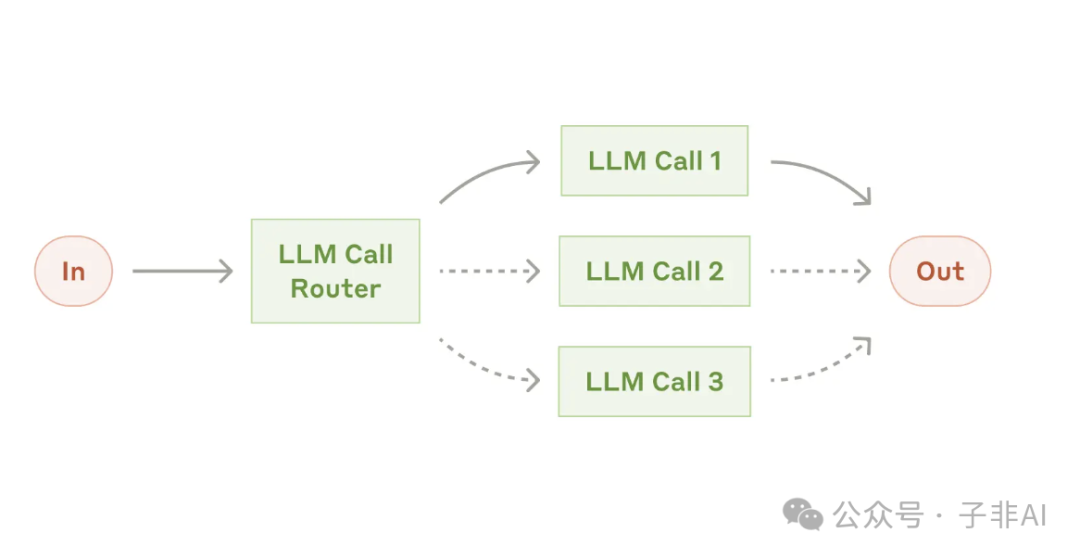
图:路由,根据输入类型,智能分流到不同的处理流程,让专业的人做专业的事
-
• 并行化 (Parallelization): 让多个 LLM 同时处理一个任务,然后将结果汇总,从而提高效率和准确性。 并行化主要有两种实现方式:分段 (Sectioning) 和投票 (Voting)。 -
• 适用场景:安全审查、代码审查等。
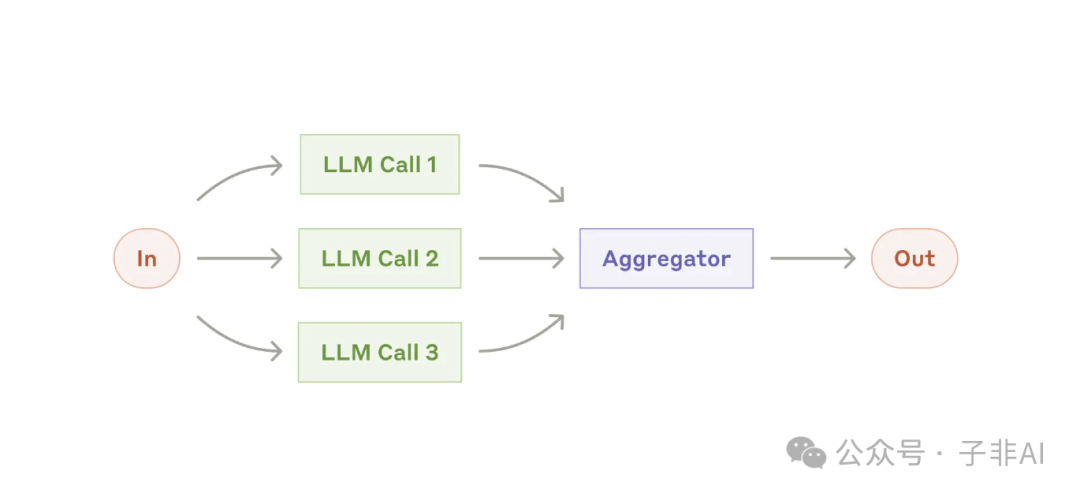
图:并行化,分段模式让多个 LLM 各司其职,并行处理;投票模式则集思广益,提升决策的准确性
-
• 编排器-工作器 (Orchestrator-workers): 由一个中央 LLM(编排器)负责统揽全局,将任务分解成若干子任务,然后分配给其他 LLM(工作器)执行,最后将结果汇总,完成整个任务。 这种模式特别适合那些难以预先确定所有步骤的复杂任务。 -
• 适用场景:复杂代码更改、多源信息搜索等。
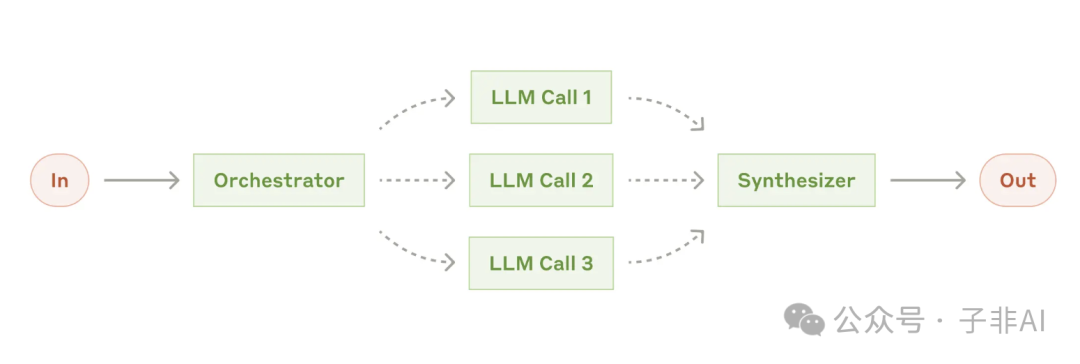
图:编排器-工作器,编排器负责任务分解和调度,工作器负责执行子任务,分工协作,高效完成复杂任务
-
• 评估器-优化器 (Evaluator-optimizer): 一个 LLM 负责生成内容,另一个 LLM 则负责评估内容的质量,并提出改进意见,如此循环往复,直到生成满意的结果。 -
• 适用场景:文学翻译、复杂信息检索等。
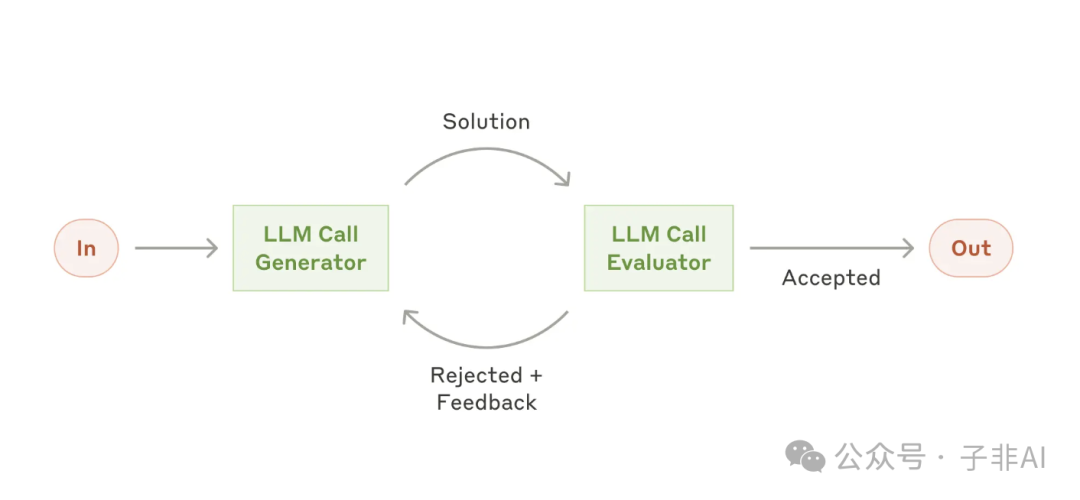
图:评估器-优化器。评估器对生成器的输出进行评估和反馈,帮助其不断改进
3 自主 Agent
自主 Agent 是 AI 发展的终极目标之一,它能够在没有人类直接干预的情况下,自主完成复杂的任务。 一旦接收到任务指令,自主 Agent 就可以独立进行规划、决策、执行,并在必要时向人类寻求帮助或反馈。
-
• 工作原理: 自主 Agent 通常基于增强型 LLM 构建,并配备了更强大的工具和更复杂的推理能力。它们能够根据环境反馈不断调整策略,并利用工具执行各种操作。 -
• 关键特性: 自主性、适应性、鲁棒性。 -
• 实现要点: -
• 清晰的目标定义: 为 Agent 设定明确的目标和约束条件。 -
• 强大的环境感知能力: 使 Agent 能够准确地感知环境状态,并根据环境变化调整策略。 -
• 可靠的工具使用能力: 为 Agent 配备可靠的工具,并确保其能够正确地使用这些工具。 -
• 有效的安全机制: 设置必要的安全护栏,防止 Agent 出现意外行为。例如限制 Agent 的权限、设置人工审核机制、持续监控 Agent 的行为等。
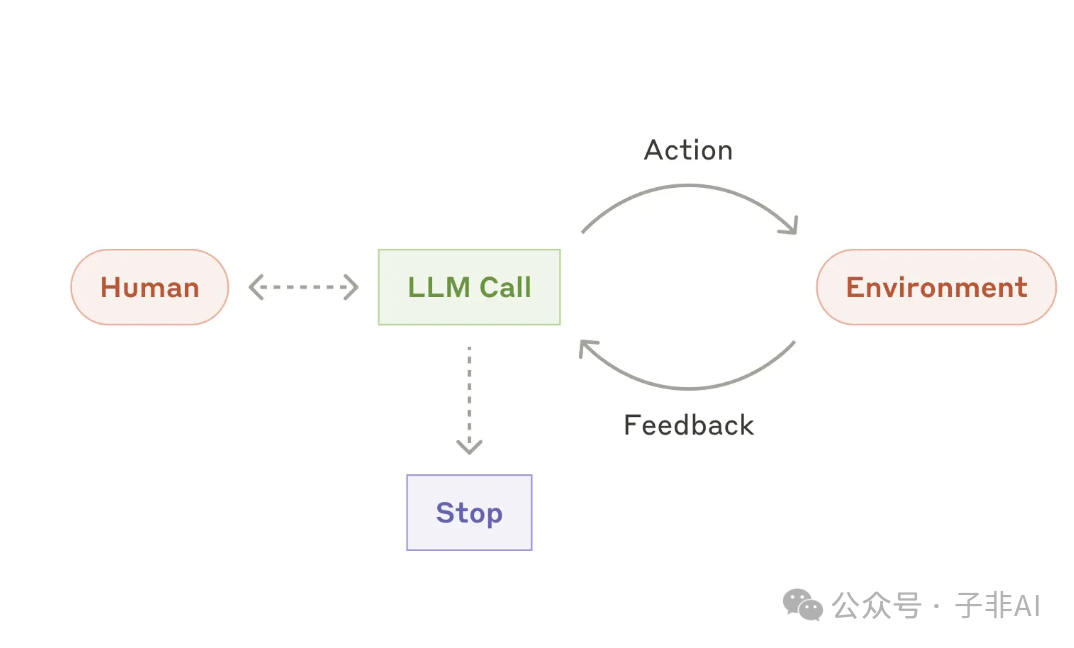
图:自主智能体,根据环境反馈和工具使用,自主完成复杂任务,代表了 AI 发展的未来方向
真实场景应用实践
1 客户支持革新
智能客服是 Agent 技术的典型应用场景。 通过集成知识库、订单系统等工具,智能客服可以 7×24 小时在线,为用户解答疑问、处理订单,甚至完成退款等操作。
-
• 应用价值: 提升客户服务效率、降低运营成本、改善客户体验。 -
• 实现方式: 通常采用路由或编排器-工作器模式,根据用户咨询的类型将其分配给不同的处理流程或工作器。 -
• 成功案例: 一些公司甚至推出了基于成功率的定价模式,只有当智能客服成功解决用户问题时才收费,这充分体现了他们对自家智能客服的信心!
2 代码开发助手
从代码补全到自主编程,Agent 正在彻底改变软件开发的模式。通过集成代码仓库、测试框架等工具,Agent 可以根据任务描述自动生成代码、运行测试、修复 bug,甚至完成整个开发流程。
-
• 技术创新: Anthropic 的 Claude 3.5 Sonnet 模型在 SWE-bench Verified 基准测试中取得了优异成绩,展现出强大的代码理解和生成能力。 -
• SWE-bench:评估 LLM 解决真实 GitHub 问题的能力 – https://www.anthropic.com/research/swe-bench-sonnet -
• 实现细节: 通常采用编排器-工作器或自主 Agent 模式,将代码开发任务分解成若干子任务,并利用工具执行代码编辑、编译、测试等操作。 -
• 实践效果: Claude 3.5 Sonnet 已经能够自主解决相当比例的真实 GitHub 问题,展现出惊人的能力!
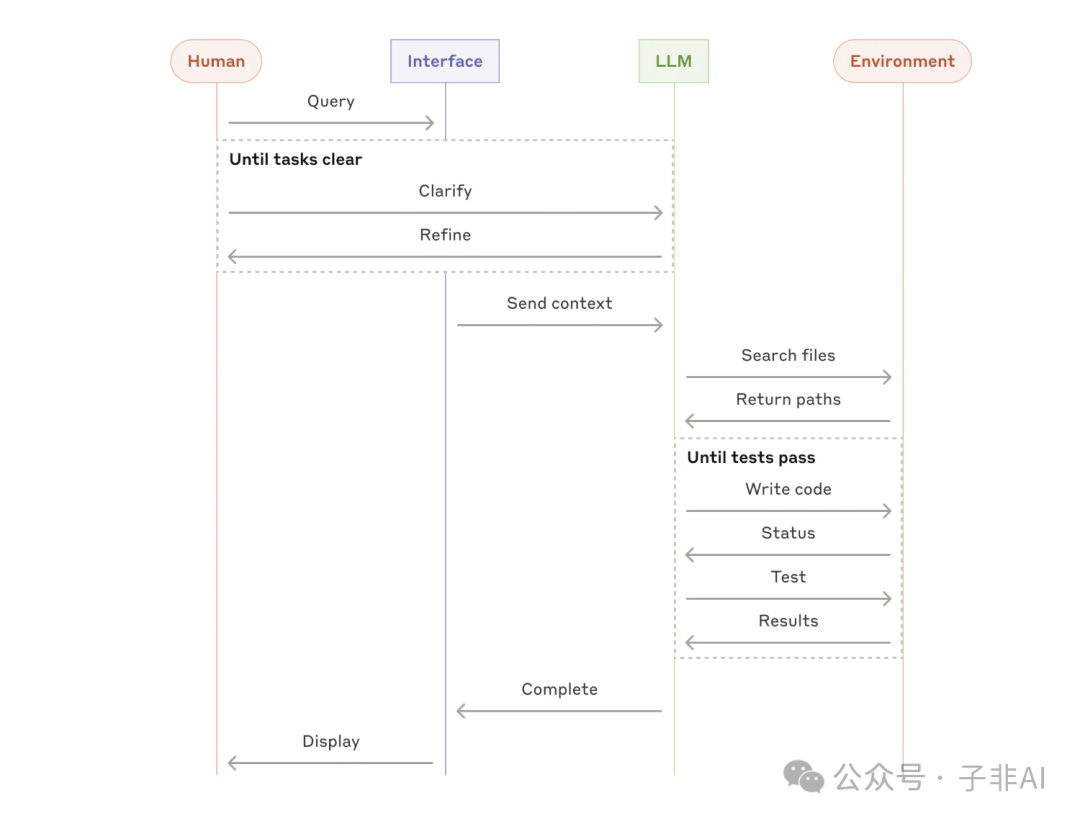
图:代码开发助手的整体架构
构建有效 Agent 的最佳实践
1 工具设计的艺术
工具是 Agent 与外部世界交互的桥梁,其质量直接决定了 Agent 的能力上限。 Anthropic 创造性地提出了 Agent-Computer Interface (ACI) 的概念,并呼吁开发者像重视 HCI 一样重视 ACI 的设计。
-
• ACI 设计理念: ACI 的设计应以 LLM 为中心,充分考虑 LLM 的特点和能力,使其能够轻松、准确地理解和使用工具。 -
• 最佳实践: -
• 换位思考: 站在 LLM 的角度思考,这个工具好用吗?描述清晰吗?参数合理吗? -
• 精雕细琢: 像写 API 文档一样,认真编写工具的描述和参数说明,确保 LLM 能够准确理解和使用。 -
• 反复测试: 在 Anthropic 的 Workbench 中进行大量测试,找出 LLM 在使用工具时容易犯的错误,并进行针对性的优化。 -
• Anthropic Workbench 链接:https://console.anthropic.com/workbench -
• 防呆设计: 借鉴工业设计中的错误预防 (Poka-yoke) 理念,通过巧妙的设计,从源头上避免错误的发生。 -
• 错误预防 (Poka-yoke) 链接:https://en.wikipedia.org/wiki/Poka-yoke -
• 常见陷阱: -
• 工具描述不清晰: LLM 无法理解工具的用途或使用方法。 -
• 参数设计不合理: LLM 难以正确地输入参数。 -
• 缺乏错误处理机制: 工具调用失败时,LLM 无法进行处理。
2 框架选择指南
市面上涌现出越来越多的 Agent 构建框架,例如 LangChain 的 LangGraph、Amazon Bedrock 的 AI Agent 框架、Rivet、Vellum 等。这些框架可以帮助开发者快速构建 Agent,但也存在一些潜在的缺点,例如过度抽象、难以调试等。
-
• 主流框架对比:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
• 选择建议: 优先考虑直接使用 LLM API。 如果一定要用框架,请务必彻底理解底层代码,别让“黑匣子”坑了你! -
• 使用注意事项: 避免过度依赖框架,要根据实际需求选择合适的工具和技术。
未来展望
Agent 技术正处于快速发展阶段,未来充满无限可能。
-
• 技术趋势: -
• 更强大的 LLM: 随着 LLM 模型的不断发展,Agent 的能力也将不断提升。 -
• 更丰富的工具: 越来越多的工具将被开发出来,使 Agent 能够执行更广泛的任务。 -
• 更智能的 Agent: Agent 将变得更加智能,能够更好地理解人类意图,并自主完成更复杂的任务。 -
• 应用前景: -
• 个性化助手: Agent 将成为我们每个人的个性化助手,帮助我们处理各种日常任务。 -
• 自动化专家: Agent 将在各个领域取代人类专家,执行各种专业任务。 -
• 科学发现: Agent 将帮助科学家进行科学研究,加速科学发现的进程。
相关链接
-
• Anthropic Quickstarts – 计算机使用示例 – https://github.com/anthropics/anthropic-quickstarts/tree/main/computer-use-demo -
• Amazon Bedrock 的 AI Agent 框架:简化智能体开发 – https://aws.amazon.com/bedrock/agents/ -
• Anthropic Cookbook – 智能体示例代码:提供多种智能体模式的实现示例 – https://github.com/anthropics/anthropic-cookbook/tree/main/patterns/agents
(文:子非AI)