


近年来,随着大语言模型(LLM)的不断进步,如何准确评估其能力已经成为研究的热点问题。诸如大规模多任务语言理解基准 MMLU(Massive Multitask Language Understanding),在评估大语言模型中起到重要作用,然而,由于开放源代码和训练数据的多样性,现有基准测试难免存在数据污染问题,影响评估结果的可靠性。
为了提供更为准确、公平的评估,微软亚洲研究院推出了 MMLU-CF,它是基于公开数据源,经过去污染设计的大语言模型理解基准,并已在 Huggingface 上开放。
近年来,随着大语言模型(LLM)的不断进步,如何准确评估其能力已经成为研究的热点问题。诸如大规模多任务语言理解基准 MMLU(Massive Multitask Language Understanding),在评估大语言模型中起到重要作用,然而,由于开放源代码和训练数据的多样性,现有基准测试难免存在数据污染问题,影响评估结果的可靠性。
为了提供更为准确、公平的评估,微软亚洲研究院推出了 MMLU-CF,它是基于公开数据源,经过去污染设计的大语言模型理解基准,并已在 Huggingface 上开放。

MMLU-CF 介绍
MMLU-CF 是一个“无污染”的、更具挑战性的多项选择题基准数据集。数据集包含 20,000 道题目,分为 10,000 道验证集题目和 10,000 道测试集题目,其中验证集开源,测试集闭源。涵盖健康、数学、物理、商业、化学、哲学、法律、工程等 14 个学科领域。

Github链接:
HF Datasets链接:

MMLU-CF 的贡献
消除数据污染:传统基准测试可能存在数据污染,影响评估的公正性。MMLU-CF通过引入三条去污染规则并扩展数据源,确保测试结果更可靠。
防止恶意数据泄露:我们将数据集分为验证集和测试集,确保测试集保持闭源,避免数据泄漏引发的不公正结果。同时,验证集开源以促进透明度,便于独立验证。
对比结果:评估结果显示,GPT-4o 在 MMLU-CF 测试集上的 5-shot 得分为 73.4%,0-shot 得分为 71.9%,显著低于其在 MMLU 上取得的 88% 得分,证明了 MMLU-CF 基准的严格性。

MMLU-CF vs MMLU 与 MMLU-Pro
MMLU 与 MMLU-Pro:这些基准测试主要关注任务的广度、推理能力和难度,但未考虑数据污染问题。
MMLU-CF:我们在数据收集时应用了去污染规则,确保避免数据泄露,同时将测试集保持闭源,防止恶意泄露。
以下是几款主流模型在 MMLU 与 MMLU-CF 数据集上的表现:
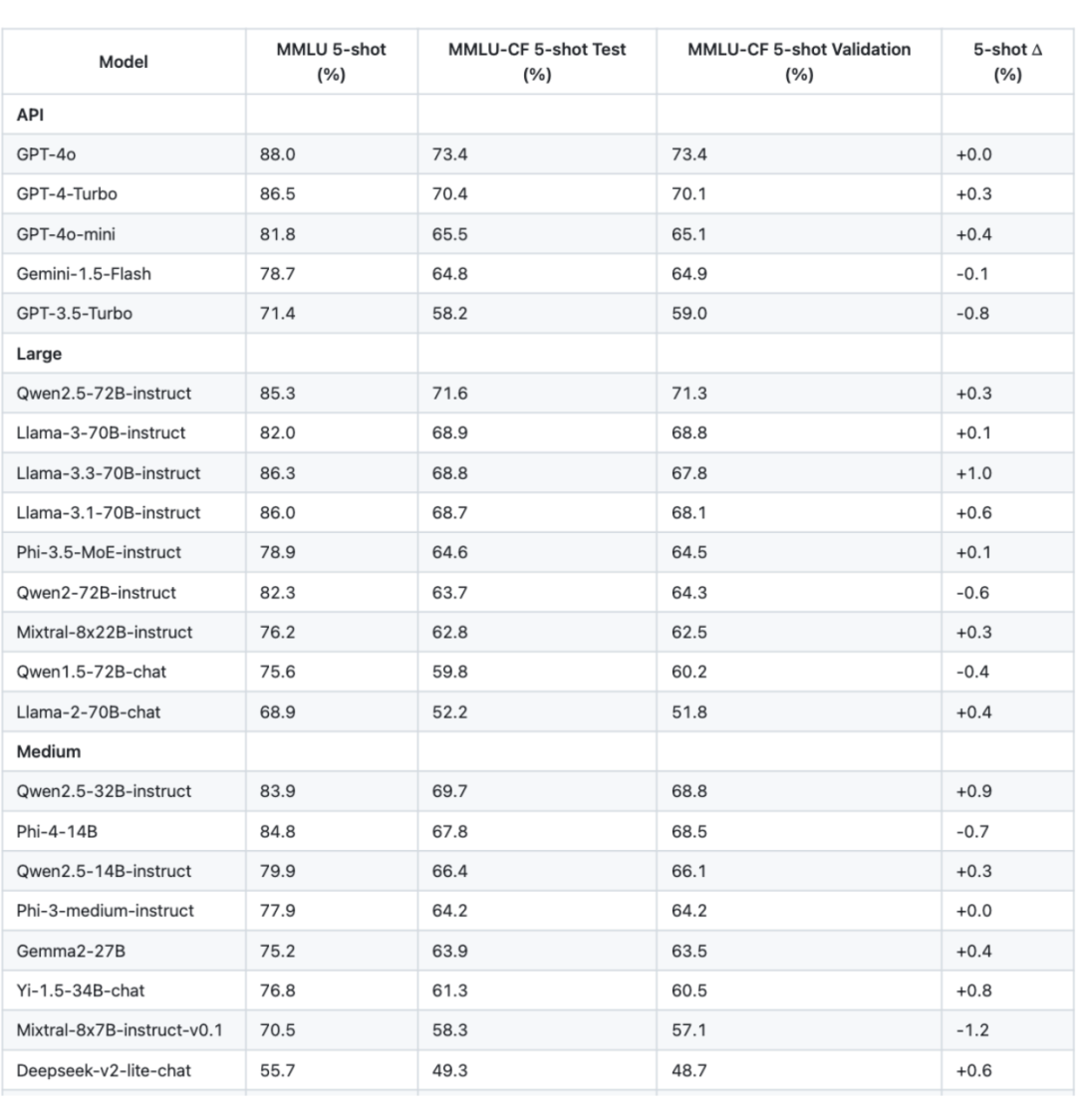
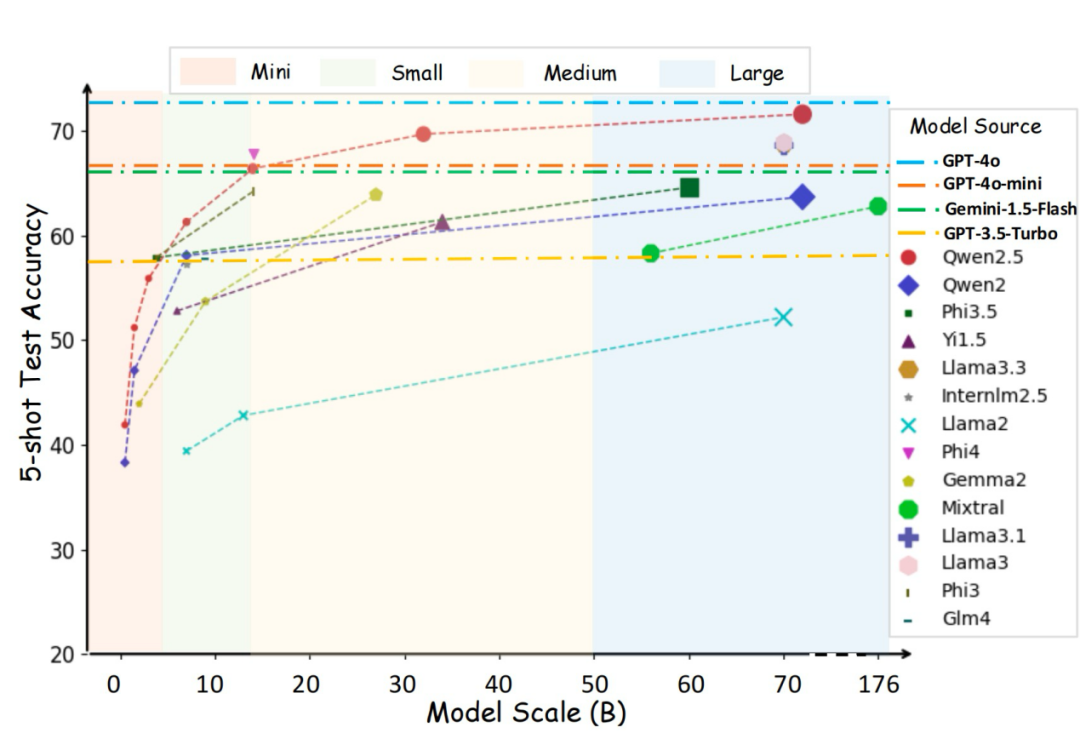
在 API 模型中,GPT-4o 以 73.4% 的测试准确率占领榜首。
在大型模型(>50B 参数)中,Qwen2.5-72B-instruct 在 5-shot 测试中得分 71.6%,接近 GPT-4 级别的表现;Llama-3.3-70B-instruct 也取得了不错的成绩,得分为 68.8%。
在中型模型中,Qwen2.5-32B-instruct 表现强劲,得分 69.7%。Phi-4-14B 则取得了 67.8% 的成绩,超过了更大模型如 Qwen2-72B(63.7%)和 Mixtral-8x22B(62.8%),体现了其高效的架构。
在小型模型中,Qwen2.5-7B-instruct 以 61.3% 的成绩超越同类其他模型,如 Glm-4-9B-chat(57.8%)和 Llama-3-8B-instruct(57.3%)。在迷你模型中,Phi-3.5/3-mini-instruct 以 57.9% 的成绩领先,Qwen2.5-3B-instruct 得分 55.9%,依然超过了同类其他模型。

测试集与验证集的划分
在 MMLU-CF 中,我们将数据集划分为测试集和验证集,并通过计算绝对分数差异()评估模型的泛化能力。统计结果显示,约 60% 的 值小于 0.5,96% 的 值低于 1.0,表明测试集和验证集的评估结果高度一致。

数据构建流程

▲ 图3. 数据构建流程图
MMLU-CF 的数据构建包括以下几个步骤:
1. 题目收集:从广泛的开放互联网域收集问题,保证问题的多样性。
2. 题目清洗:确保收集到的问题质量高,适合用于评估。
3. 难度采样:确保问题的难度分布合理。
4. 大模型检查:使用 GPT-4o、Gemini、Claude 模型对数据的准确性和安全性进行检查。
5. 去污染处理:通过去污染处理,确保数据集的无污染性。
最终,MMLU-CF 数据集分别包含了 10,000 道测试集域验证集题目,同时测试集保持闭源,验证集则公开以保证透明性。

去污染处理规则
为了避免无意中的污染并评估模型的推理和理解能力,我们采用了三条去污染规则:
-
规则 1:改写问题,减少模型对已见数据的依赖。
-
规则 2:打乱选项,避免模型通过记忆选项顺序做出正确答案。
-
规则 3:随机替换选项,增加模型的推理难度。
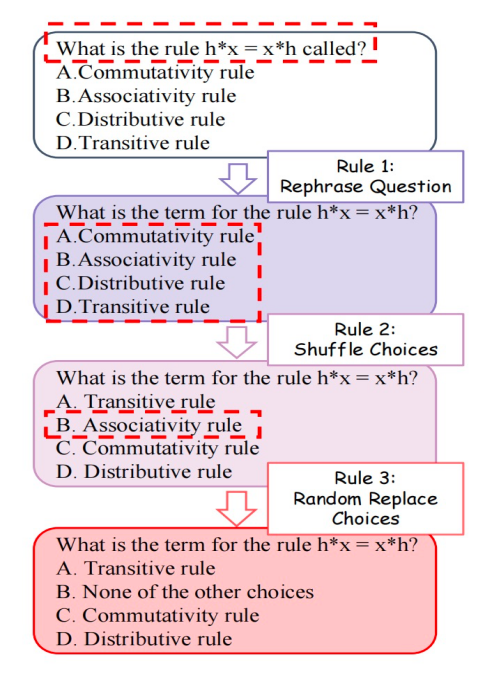
▲ 图4. 去污染示例
这些规则有效减少了恶意和无意的泄漏风险,确保了数据集的“无污染”性。

总结
MMLU-CF 为大语言模型的评估提供了一个更加公平和可靠的基准,不仅帮助研究者准确理解模型的能力,也为未来模型优化提供了宝贵的数据支持。如果您希望测试自己的大模型在 MMLU-CF 上的表现,请访问我们的 GitHub 主页获取更多信息。
招聘:MSRA – 大模型相关的数据生成、处理、训练和地质学交叉学科方向实习生与科研助理(需已毕业),联系方式 yanghuan@microsoft.com
(文:PaperWeekly)