


邮箱|wangzhaoyang@pingwest.com

-
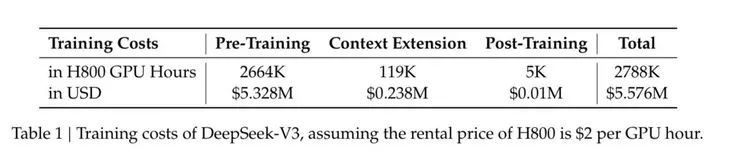
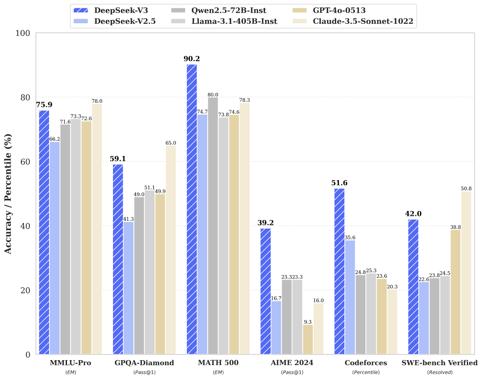
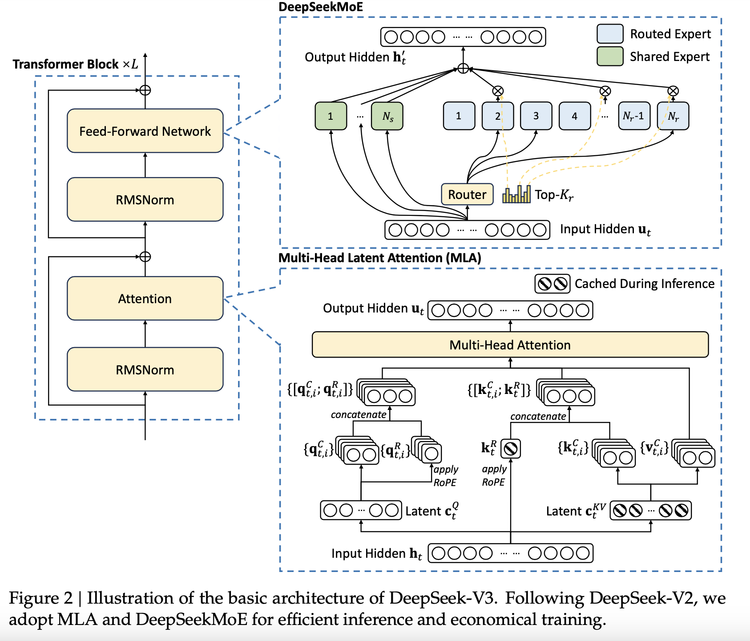
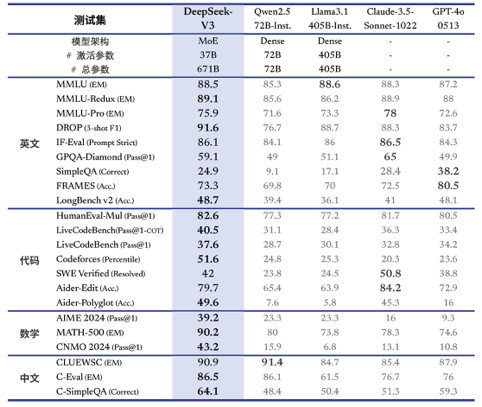
百科知识:DeepSeek-V3 在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平相比前代 DeepSeek-V2.5 显著提升,接近当前表现最好的模型 Claude-3.5-Sonnet-1022。 -
长文本: 在长文本测评中,DROP、FRAMES 和 LongBench v2 上,DeepSeek-V3 平均表现超越其他模型。 -
代码:DeepSeek-V3 在算法类代码场景(Codeforces),远远领先于市面上已有的全部非 o1 类模型;并在工程类代码场景(SWE-Bench Verified)逼近 Claude-3.5-Sonnet-1022。 -
数学: 在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek-V3 大幅超过了所有开源闭源模型。 -
中文能力:DeepSeek-V3 与 Qwen2.5-72B 在教育类测评 C-Eval 和代词消歧等评测集上表现相近,但在事实知识 C-SimpleQA 上更为领先。

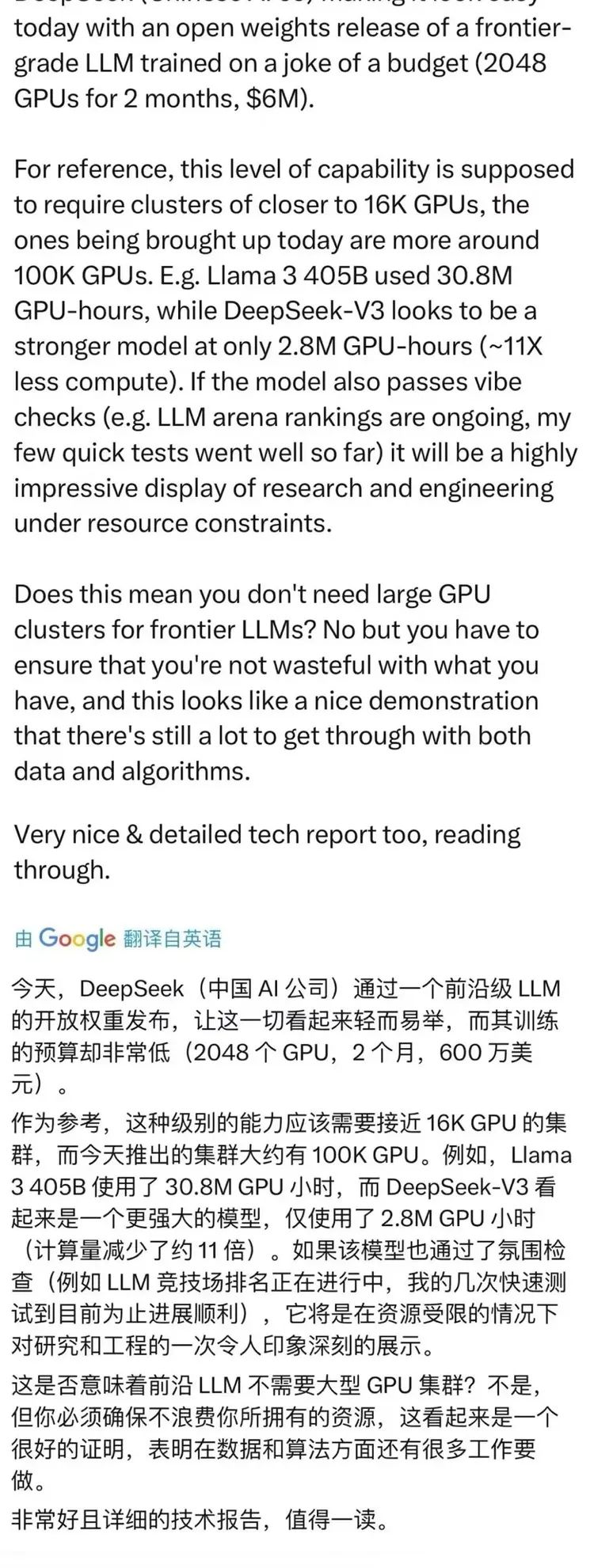
另外一个有意思的地方是,今天最重要的一些AI Infra创业公司的创始人们也对Deepseek V3充满好感。一个在推理侧再次推动着创新并由此可以刺激市场需求的模型,自然是推理侧的创业公司们需要和希望客户们看到的。



(文:硅星人Pro)