
AI 大语言模型推理性能的提升,对于低耗能、高效率来说是积极的信号。看我文章的朋友应该还记得之前写过一篇《开源AlphaFold 3》推文,有提到了谷歌DeepMind 对于推动科学发展有积极的意义。
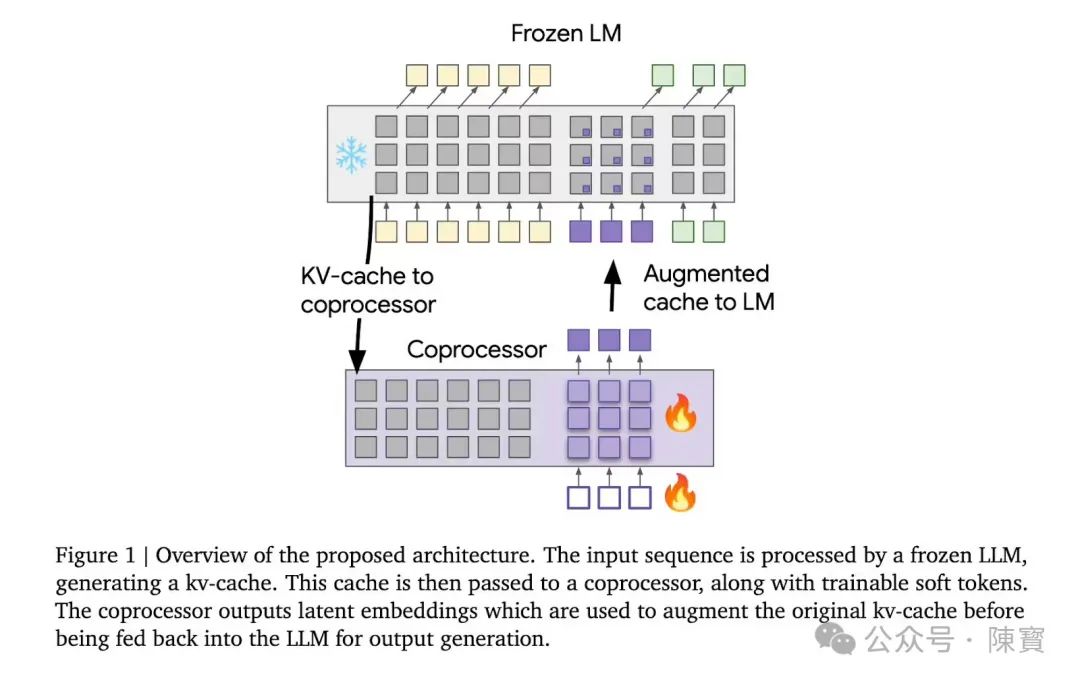
近日,谷歌 DeepMind 团队最新推出的“可微缓存增强”方法,在不明显额外增加计算负担的情况下,显著提升了大语言模型(LLMs)的推理性能。个人觉得它通过引入外部协处理器来增强 LLMs 的键值(kv)缓存,进而丰富了模型的内部记忆。
技术原理
“可微缓存增强”(Differentiable Cache Augmentation),一项由谷歌DeepMind团队提出的创新技术,通过增强模型的键值(key-value, kv)缓存,丰富其内部记忆,进而增强处理复杂任务的能力。
传统LLMs中,模型在处理输入时会生成内部的键值缓存,这些缓存作为模型的“记忆”,记录了对输入的内部表示。然而,这些缓存通常仅用于存储信息,供后续解码使用。
可微缓存增强技术通过引入一个协处理器,对这些缓存进行加工和增强,生成新的潜在嵌入(latent embeddings),以提升模型的推理能力。
协处理器是可微缓存增强技术的核心,其任务是接收模型生成的键值缓存,并输出一组潜在嵌入。这些嵌入随后被添加到原始缓存中,为模型提供更丰富的上下文信息。
整个过程包括以下阶段:
1. 缓存生成:输入序列被传递给冻结的语言模型,生成对应的键值缓存。
2. 缓存增强:协处理器接收键值缓存,并结合一组可训练的软性嵌入(soft tokens),生成潜在嵌入。
3. 增强后的解码:潜在嵌入被添加到原始缓存中,模型在增强后的上下文中继续解码,生成输出序列。
设计的关键优势在于,语言模型的参数在整个过程中保持不变,而协处理器则通过标准的语言建模损失进行训练。
实现了端到端可微性和异步操作,协处理器的训练可以通过梯度反向传播完成,无需复杂的强化学习技术,同时协处理器可以离线运行,与模型的解码过程并行,从而提升效率。
潜在嵌入是协处理器输出的关键结果,它们旨在改善后续解码的保真度。这些嵌入是通过协处理器在单次前向传递中生成的一组软标记实现的,而不是顺序进行。这一额外的处理由协处理器独立模型执行,而基本的语言模型保持不变。
潜在嵌入的作用在于,它们能够将模型的内部记忆策略存储计算,这独立于对查询进行响应的组成。
通过引入外部协处理器来优化键值缓存,研究人员成功地在保持计算效率的同时,显著提升了大语言模型的性能。实验结果表明,当缓存被增强时,解码器在许多后续标记上实现了更低的困惑度。
即使没有任何针对特定任务的训练,实验也表明,缓存增强可以持续减少困惑并提高一系列推理密集型任务的性能。
应用场景
“可微缓存增强”技术在大型语言模型(LLMs)的内部记忆增强方面具有显著的应用潜力,通过引入协处理器来增强LLMs的键值(kv)缓存,能够丰富模型的内部记忆,从而提高模型处理复杂任务的能力。
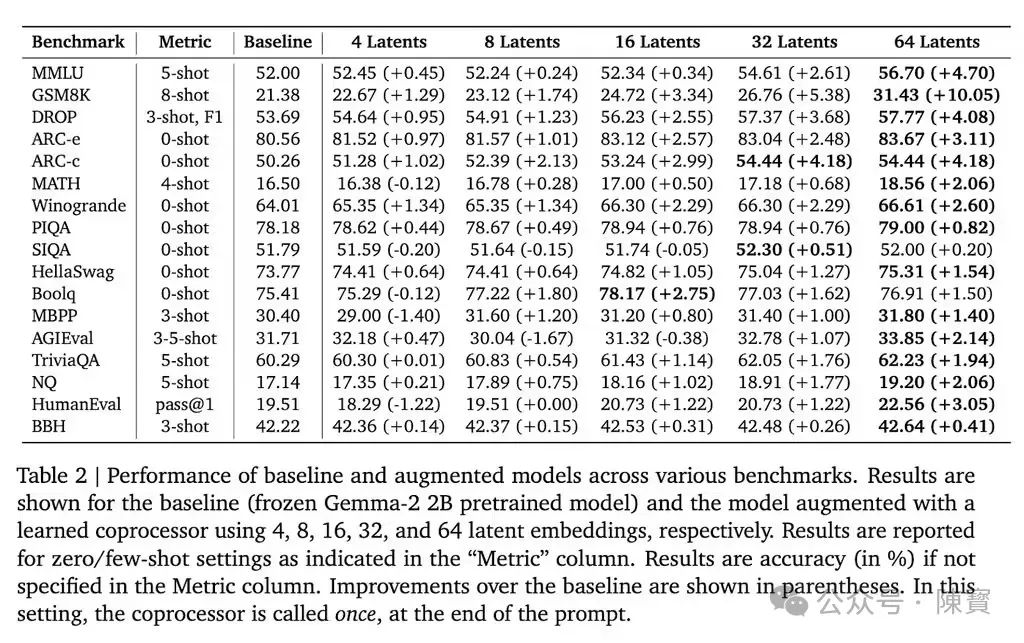
Gemma-2 2B模型上的测试结果显示,该技术在多个基准测试中取得了显著成果,在GSM8K数据集上,准确率提高了10.05%;在MMLU上,性能提升了4.70%。
新技术降低了模型在多个标记位置的困惑度,这进一步证明了其有效性。
内部记忆增强的应用不仅限于提高模型的准确性,还包括提升模型的推理能力和适应性。通过增强的内部记忆,LLMs能够更好地理解和处理长距离依赖关系,这对于语言理解和生成任务尤为重要。
一个包含2万亿标记的多样化数据集上进行预训练的Gemma-2模型,通过协处理器生成不同数量的潜在嵌入,并在多个推理密集型任务上进行评估,结果显示困惑度显著降低。
表明潜空间增强不仅提升了短期预测能力,还对更远的标记产生了积极影响。
“可微缓存增强”技术在提升复杂问题解决能力方面也显示出巨大潜力,传统方法需要模型生成离散的中间步骤,这会导致显著的延迟,并且难以进行端到端的优化。
通过在潜在空间中进行推理,避免了逐步生成的开销,同时实现了端到端的可微性。这种方法使得模型能够以更高效的方式处理复杂问题,尤其是在需要更长的依赖关系或更高的预测准确性的任务中。
多个公开基准测试中,增强后的模型在推理密集型任务上的表现显著提升。
“可微缓存增强”技术为在固定计算预算内优化性能提供了新的思路,优化LLMs的一大挑战是它们无法有效地跨多个任务进行推理或执行超出预训练架构的计算。
通过引入外部协处理器增强kv缓存,研究人员在保持计算效率的同时显著提高了模型性能,即使在计算资源有限的情况下,LLMs也能够通过增强内部记忆来提升其性能。
潜在影响
“可微缓存增强”(Differentiable Cache Augmentation)技术为AI模型设计提供了重要的启示,特别是在如何平衡模型的复杂性和计算效率方面。
这项技术展示了通过创新的架构设计,能够在不增加模型参数的情况下提升性能。
这种设计思路启示研究人员在模型设计时考虑更多的模块化和可扩展性,通过引入辅助组件来增强模型能力,而不是简单地增加模型大小。

“可微缓存增强”技术通过协处理器的引入,实现了模型的端到端可微性和异步操作,我认为它给模型设计提供了新的思路。
(一)未来的模型设计中,可以考虑更多的并行处理和异步学习机制,以提高训练效率和模型性能。
(二)模型设计中考虑记忆和推理能力很重要性,通过增强模型的内部记忆,能够提升模型处理复杂任务的能力。
(三)对于设计能够处理长距离依赖和复杂推理任务的模型具有重要意义。
“可微缓存增强”技术在不显著增加计算负担的情况下,显著提升了大语言模型的推理性能。
通过减少模型在多个标记位置的困惑度,提升了模型的推理能力。在相同的计算资源下,模型能够更准确地理解和生成语言,对于需要高推理能力的NLP任务尤为重要。
⋯ ⋯
技术的影响是深远的,也是深刻的。“可微缓存增强”为大语言模型的性能优化提供了新的方向,即通过增强内部记忆来提升模型的推理能力。
它会引导未来的研究更多地关注模型的记忆机制和信息处理能力,而不是单纯地增加模型规模。
方向正确了,就不怕路远,它会推动更多关于模型微调和优化的研究。通过协处理器的引入,研究人员能够探索更多关于模型组件化和模块化的方法,以实现更高效和灵活的模型训练和部署。
(文:陳寳)