

用更少的数据,做更复杂的事!

几周前,OpenAI悄悄放出了一个重磅新技术——强化微调(Reinforcement Fine-Tuning,RFT)。
这个技术号称能让大语言模型只用「几十条数据」就能完成复杂任务的训练!

这听起来像是天方夜谭?
但OpenAI展示的结果令人震惊:RFT不仅能用少量数据进行训练,还能教会模型如何思考问题!
为什么RFT如此重要?
在AI发展的当下,我们似乎遇到了一个尴尬的瓶颈:
模型训练和推理成本确实在大幅下降,但收集高质量的标注数据依然是一个大难题。
特别是对于那些需要专业知识的领域,比如医疗、法律等,获取足够的标注数据简直就是一场噩梦。
RFT的出现,将所需数据量减少了一个或多个数量级!
这意味着,我们终于有机会用更少的数据,去解决更复杂的问题。
RFT:干货满满的技术细节
那么,RFT到底是如何工作的呢?

OpenAI的工程师们设计了一个精妙的训练流程:
第一步:准备数据集
-
数据量可以很小,只需几十条
-
但必须有「明确的对错标准」
-
比如医疗案例中判断基因突变、法律文书中提取关键信息等
第二步:生成推理
-
模型会生成「推理轨迹」和最终输出
-
不是简单输出结果,而是展示完整的思考过程
-
就像上图中的流程展示,每个步骤都清晰可见
第三步:评分机制
-
评分员(可以是程序)会给每个输出打分
-
采用灵活的评分标准,而不是简单的对错判断
-
允许「部分正确」,给予相应的分数奖励
第四步:强化学习
-
使用PPO(近端策略优化)等强化学习算法
-
根据评分结果更新模型权重
-
引导模型生成更高质量的输出
「部分正确」的魔力
RFT最巧妙的设计在于它的评分机制。看看这个具体的例子:
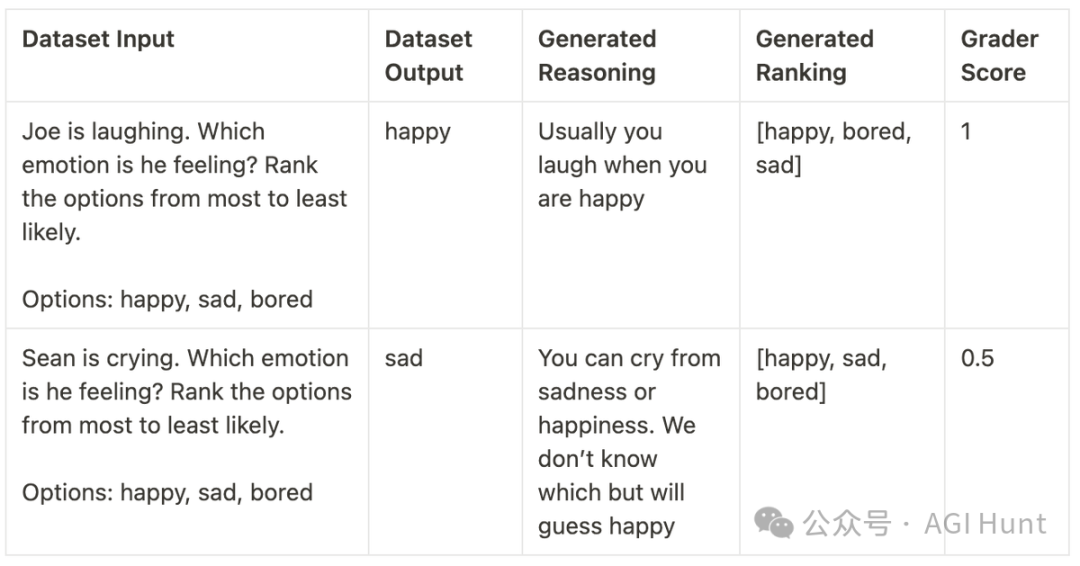
在这个情绪判断的任务中:
-
正确答案排第一:得满分(1分)
-
排在第二位:得半分(0.5分)
-
排在第三位或未出现:零分
这种设计让模型能更快地找到正确方向:即使答案不完全正确,只要方向对了,就能得到一些积极反馈。
在强化学习中,这被称为「密集奖励信号」(dense reward signal)。它能帮助模型更稳定、更快速地学习,而不是像传统方法那样只能从完全正确的答案中学习。
什么时候该用RFT?
OpenAI建议在以下三种情况下考虑使用RFT:
任务难度大
-
如果是简单任务,可能完全不需要微调
-
越是复杂的任务,RFT的优势越明显
容易验证输出
-
必须能清楚判断输出的对错
-
分类、信息提取等任务最为合适
-
开放式对话等任务可能不太适合
标注数据难收集
-
如果已经有大量标注好的数据,用传统的监督式微调(SFT)可能更简单
-
但如果收集数据成本高,RFT就是最佳选择
RFT的实用技巧
对于超大规模任务,RFT还可以作为「垫脚石」,采用这样的策略:
-
先用50-100个人工标注的例子训练RFT模型
-
用这个RFT模型去标注更多数据(比如2万条)
-
再用这些数据去训练一个更简单、更快的模型
-
最后用这个优化后的模型处理剩余的所有数据
这样就能既享受RFT的高效,又不被它的复杂性所困扰。
目前,OpenPipeAI正在开发开源版RFT实现,计划用于微调像Qwen的QwQ这样的推理模型。他们已经获得了一些令人振奋的初步结果,正在寻找更多的数据集进行测试。
此外,Allen AI的研究团队也开发出了一个几乎相同的训练流程,他们称之为「可验证奖励的强化学习」(RLVR)。这表明这个方向确实很有前途!
AI训练的「数据荒」时代或许并不会存在!
这个突破性的技术,将让更多创新应用有机会落地。不仅仅是大公司,普通开发者也将有机会用少量数据训练出高质量的模型。

Ilya 号称的数据耗尽问题,或许将被合成数据以巧妙的方式得到解决。
相关链接
[1] https://openpipe.ai/blog/openai-rft
[2] https://x.com/corbtt/status/1873864746023477482
(文:AGI Hunt)