
ExtractThinker 是一个灵活的文档智能工具,利用大型语言模型(LLMs)从文档中提取和分类结构化数据,类似于 ORM(对象关系映射),实现无缝的文档处理工作流程。主要功能如下所示:
-
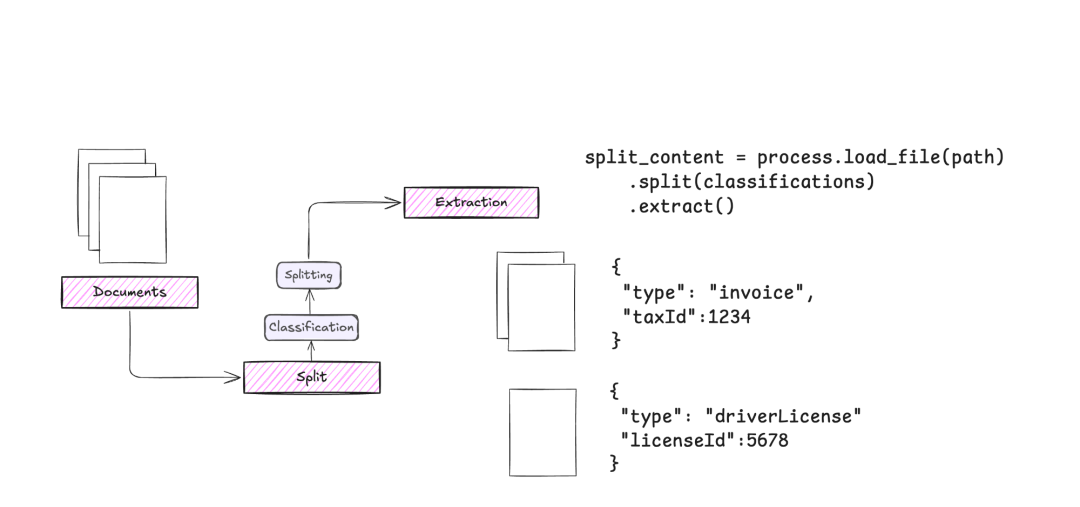
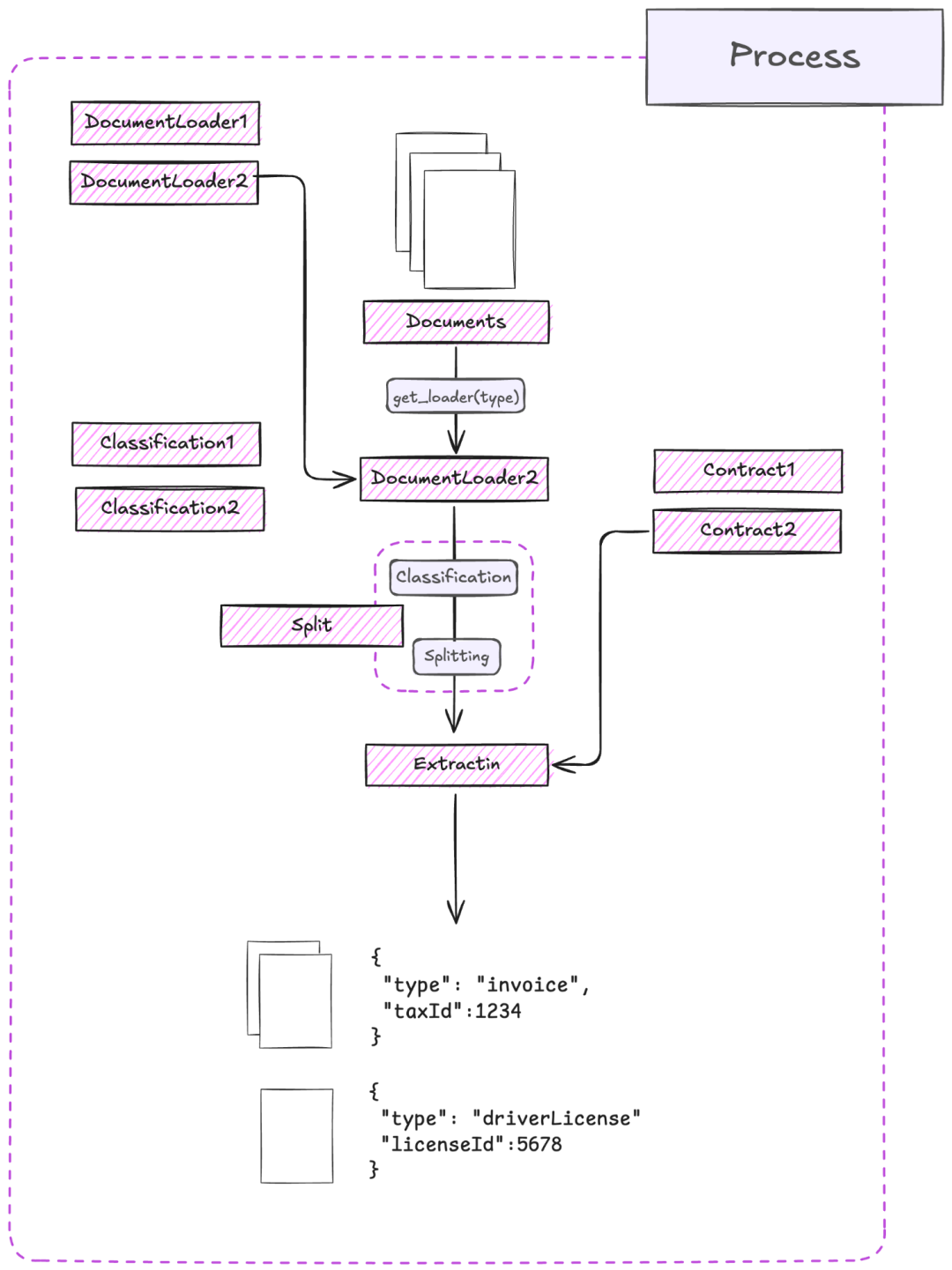
灵活的文档加载器:支持多种文档加载器,包括 Tesseract OCR、Azure 表单识别器、AWS Textract、Google Document AI 等。 -
可定制的合约:使用 Pydantic 模型定义自定义提取合约,实现精确的数据提取。 -
高级分类:使用自定义分类和策略对文档或文档部分进行分类。 -
异步处理:利用异步处理高效处理大型文档。 -
多格式支持:无缝处理各种文档格式,如 PDF、图像、电子表格等。 -
类似 ORM 的交互:以类似 ORM 的方式与文档和 LLMs 交互,便于直观开发。 -
拆分策略:实施懒拆分或急拆分策略,按页或整体处理文档。 -
与 LLMs 的集成:轻松集成不同的 LLM 提供商,如 OpenAI、Anthropic、Cohere 等。 -
社区驱动开发:受到 LangChain 生态系统的启发,专注于智能文档处理。
参考文献:
[1] https://enoch3712.github.io/ExtractThinker/getting-started/
[2] https://github.com/enoch3712/ExtractThinker
(文:NLP工程化)