

、
在 Mozilla 处理 Firefox 网络兼容性问题的工程师 Dennis Schubert 近期指责大模型公司疯狂爬取内容导致网站负载过高而运行变慢的帖子火了,因为 Schubert 道出了不少开发者的心声:
前段时间,我被 diaspora 项目网络基础设施(包括 Discourse、维基还有项目网站等)运行缓慢 / 负载高企所困扰,而查看流量日志之后我立马怒从心头起。
在过去 60 天里,diaspora 的 Web 资产共收到 1130 万条请求,相当于每秒 2.19 条请求。老实讲,这并不算多。虽然负载远远超过普通的个人博客,但我的基础设施应该能够从容处理才对。
但是,让我恼火的原因在于,查看头部用户代理统计,排在最前面的是:
有 278 万条请求(占全部流量的 24.6%)来自 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)。
有 169 万条请求(占全部流量的 14.9%)来自 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 (Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot)
有 49 万条请求(占全部流量的 4.3%)来自 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
有 25 万条请求(占全部流量的 2.2%)来自 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1;+https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36
在 22 万条请求(占全部流量的 2.2%)来自 meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)
从结果来看,我的服务器有 70% 的负载都来自那些该死的大模型训练操作。这群爬虫除了一遍又一遍地爬取互联网内容之外,毫无现实意义。
最可气的是,它们还不是爬取完一个页面就继续前进,而是 每 6 小时回来再爬一遍。很明显,他们既不关心目标服务器的性能、也不关注爬取内容的质量。近期,ChatGPT 和亚马逊都在爬取维基页面的所有修订历史,他们会索引每个页面上每条变更中的每一点差异,频繁引发超过每秒 10 条请求的峰值负载。这当然沉重打击了 MediaWiki 和我的数据库服务器,引发负载峰值,也导致人类用户卡死 / 访问速度变慢。
哪怕尝试限制它们的访问速率,对方也会一直切换其他 IP。而如果尝试通过用户代理字符串将其屏蔽,它们则会切换至非机器人 UA 字符串。至少在我看来,这就是在对整个互联网发动 DDoS 攻击。
以下是正常机器人的行为模式(经典搜索引擎机器人),供大家参考:
1.66 万条请求(占全部流量的 0.14%)来自 Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
1.59 万条请求(占全部流量的 0.14%)来自 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36
为什么流量明显更低?因为人家知道一遍又一遍爬取重复内容根本没有意义。
不说了,真的心累。
之后,Schubert 表示,计划根据 LLM 生成的一些包含无意义的文本片段,将它们重定向到随机生成的文本(非静态的,因此每次加载页面时看起来都会略有不同)。“遗憾的是,我需要完成一些正在进行的基础设施重组,然后才能将其部署到我托管的所有内容中。”
Schubert 帖子引起了很多开发者“大倒苦水”:“我更新了我网站的 robots.txt 上的爬虫阻止列表,发现他们似乎将抓取尝试次数增加了 10 倍。”还有人网友表示,“我看到了很多流量,根据它们访问的 URL 模式我可以判断出是机器人。它们不包括‘bot’用户代理,而且经常使用住宅 IP 池。我还没找到一个简单的方法来阻止它们。它们几天前也差点把我的网站搞垮了。”
受大模型公司爬虫困扰的还有大型网站。2024 年 7 月底,Anthropic 被曝使用 ClaudeBot 网络爬虫来为 Claude 等 AI 模型抓取训练数据,该爬虫在 24 小时内对 iFixit 网站进行了近一百万次攻击。
“爬取速度太快了,触发了我们的警报,开发团队开始采取行动,”iFixit 首席执行官 Kyle Wiens 表示,“iFixit 的流量很大。作为互联网的顶级网站之一,我们对网络爬虫和机器人非常熟悉。我们可以很好地处理这种负载,但这次属于异常情况。”

此外,Read the Docs 联合创始人 Eric Holscher 和 Freelancer.com 首席执行官 Matt Barrie 在 Wiens 的帖子下表示,他们的网站也遭到了 Anthropic 爬虫的猛烈抓取。这似乎也不是 ClaudeBot 的新行为,几个月前的 Reddit 帖子就揭示了 Anthropic 的网络抓取量急剧增加。今年 4 月,Linux Mint 网络论坛将网站中断归咎于 ClaudeBot 抓取活动造成的压力。
“LLMs 是一种该死的祸害。它们的训练基础设施就是一个可怕的、消耗一切的寄生虫,这个寄生虫正在摧毁互联网(并且在大规模浪费现实世界的资源)。”有网友气愤地说道。
通过 robots.txt 文件禁止爬虫是许多其他 AI 公司(如 OpenAI)的首选退出方法。
所谓 robots.txt 文件,是指存放在 Web 服务器上的简单文本文件,用于指导搜索引擎机器人及其他网络爬虫如何与我们的网站进行交互。其允许我们控制网站中的哪些部分可供爬虫程序访问,哪些部分明确禁止访问。虽然最初是为谷歌等搜索引擎所设计,但随着 AI 驱动工具在 Web 上大肆爬取内容,robots.txt 文件被越来越广泛地使用。

但它没有为网站所有者提供任何灵活性来表示哪些内容是允许的,哪些是不允许的。Perplexity 则完全忽略了 robots.txt 排除。尽管如此,它仍然是公司为数不多的几个选择之一,可以将他们的数据排除在 AI 培训材料之外,Reddit 在最近打击网络爬虫时就采用了这种方法。iFixit 解决 Anthropic 疯狂爬取的方式也是将抓取延迟扩展添加到了 robots.txt 中。
网友 markerz 介绍了他的情况,“我的一个网站被 Meta 的 AI 机器人彻底摧毁了。”他说道,Meta-ExternalAgent “请求越来越多,直到我的服务器崩溃,然后它会暂停一分钟,然后再次请求更多。”“我也修改了 robots.txt,但是 AI 机器人无视了它。”
markerz 的解决方案是添加一条 Cloudflare 规则来阻止来自其 User-Agent 的请求,此外还向链接和 robots.txt 添加了更多 nofollow 规则,但 markerz 表示这些只是建议,有些机器人似乎会忽略它们。另外,Cloudflare 还具有阻止已知 AI 机器人甚至疑似 AI 机器人的功能。
还有一些被爬虫困扰的个人开发者开始“报复”爬虫公司。Kevin Freitas 就开发了一款 WordPress 插件:AI Poison Pill,当有一个机器人爬网页内容时,该插件会扰乱网站博客文章和页面内容中的词汇。“用户在网站上撰写和发布的文字属于自己。与其阻止 AI/LLM 抓取机器人窃取你的内容,为什么不使用垃圾内容来毒害它们呢?”Freitas 说道。
开发者 Niko 还补充道,他会将这些机器人重定向到 gz.niko.lgbt,它会返回一个看似无害的 100MB HTTP 响应,但content-encoding: gzip解压缩后会变成 100GB,而找出答案的唯一方法就是实际解压缩它,所以如果那些公司想要任何东西,就必须通过它。这种做法不仅浪费那些公司的流量,还浪费磁盘空间和计算能力。
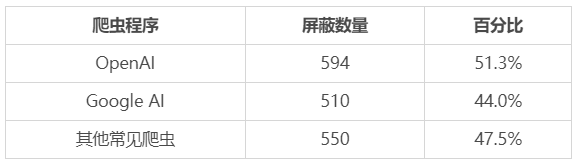
新闻媒体是被爬取较多的网站。截至本周早些时候,Palewire 项目共检查了 1158 家新闻出版商,并发现其中超过半数做出了同样的屏蔽选择,统计结果如下:
然而,一方面 AI 开发商往往并不那么守规矩;另一方面,像使用 robots.txt 作为版权保护方法的法律地位也仍有争议。虽然有些人认为屏幕 AI 爬虫属于合法的内容保护方式,但也有人觉得这可能不足以作为法庭支持的强制性版权执行主张。
首先,只需要通过简单的复制粘贴和内容读取就能让大语言模型(LLM)获取网站内容,用户就可以打破 robots.txt 设置的防御壁垒。而且很明显,用户将网站内容投喂给大模型的行为肯定不违法,也无法加以阻止。
其次,机构真的有勇气拒绝模型开发者将自有内容用作训练吗?真的确定要屏蔽一切访问活动吗?以 Perplexity 为例,一些网站就不会出现在 Perplexity 明确列出的来源网站中。另一方面,对于那些内容质量确实过硬的新闻机构,因为大模型开发商仍须依赖期信息来为 AI 用户提供优秀答案,所以出版机构也许能借此争取付费爬取(Perplexity Publishers’ Program 等项目就是实例)。
如果法院裁定 robots.txt 等是具备法律效力的工具,则意味着出版商能够更有效地保护其内容。但如果院方认为其合法性不足,出版机构可能还需要探索其他法律保护手段。此外,如果大模型开发商与各大出版巨头达成协议,那么留给小型、独立出版方的谈判空间也会更加有限。
AI 爬虫常被用于爬取内容以训练模型或者生成输出,还已经引发了严重的版权问题。
“窃取艺术家一生创作的作品,抽取其中的基本价值,然后将成果重新包装再跟原创作品竞争,这显然是不对的。”可换个角度讲,“Suno 在努力让音乐家、教师甚至是更多普通人都能使用 AI 工具创作原创音乐,可唱片公司却认为这会威胁到自己的市场份额。”这实际上就是美国唱片业协会(代表美国音乐产业)与音乐生成 AI 开发商 Suno 之间的争论焦点。
到底谁说的有理?只能留待法官去判断。
(文:AI前线)