
介绍一个 RAG 基础知识到高级实现的开源指南。指南名为 bRAG-langchain,它能帮你从基础到进阶,一步步搭建 Retrieval-Augmented Generation(RAG,检索增强生成)系统。
该教程是一个系列,里面不仅有实战例子,还涉及了很多前沿技术,比如 CRAG 和多向量检索,特别适合那些想深入了解 RAG 的开发者。
而且教程还是用Jupyter Notebook实现的,每个部分都有详细的讲解和代码示例,从环境配置、数据加载,到向量存储和检索优化,基本上能覆盖你想要实现的各种功能。
最重要的是,它还提供了一个可自定义的聊天机器人模板,让你可以轻松创建属于自己的RAG应用。
通过实践,你将学会如何设置向量数据库、利用多查询提升精准度、甚至集成更先进的检索模型如ColBERT、RAPTOR等。
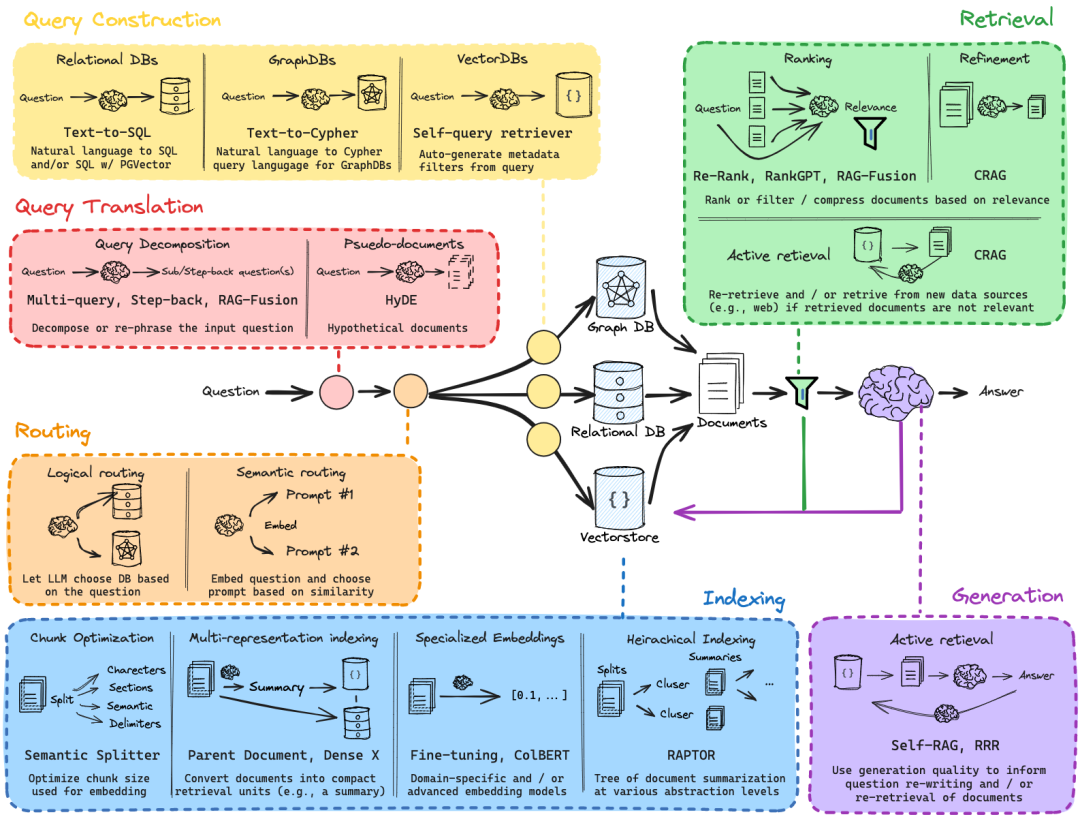
项目中恰好有个RAG关键组件图,我们先简单了解一下图1:
-
查询构建 (左上角黄色块):分为关系数据库、图数据库和向量数据库查询,它们将自然语言查询转为特定数据库的查询(如 SQL、Cypher),以及向量数据库的自查询检索。
-
查询翻译(红色块):包括查询分解和伪文档的生成,通过多查询生成和步退查询(如 RAG-Fusion),增强问题的表述。
-
路由 (橙色块):分为逻辑路由和语义路由,逻辑路由允许基于问题内容选择数据源,而语义路由则利用嵌入向量的相似度来匹配和路由查询。
-
检索 (绿色块)
-
排名和细化:使用各种技术(如重排序、RAG-Fusion、CRAG)来筛选、压缩和确定文档的相关性。 -
主动检索:如果现有文档不相关,可以从新的数据源(如互联网)重新检索或检索信息。
-
索引 (蓝色块)
-
文档分块优化:根据字符、部分、语义界定符等优化文档块大小。 -
多表征索引:设置一个多向量索引结构,以处理具有不同嵌入和表征的文档。 -
专用嵌入:利用微调、ColBERT等技术,生成领域特定的高级嵌入模型。 -
层次索引:将文档以层次化方式组织,更快地缩小潜在的搜索范围,从而加速查找过程。
-
生成 (紫色块)
-
活跃检索:利用生成的质量信息,指导文档的检索,确保生成回答的准确性。 -
自我RAG、RRR(递归等级重排序):提高回答的相关性和质量。
参考文献:
[1] https://github.com/bRAGAI/bRAG-langchain
[2] https://www.bragai.tech/
(文:NLP工程化)