

这是 自动评估基准 系列文章的第三篇,敬请关注系列文章:
基础概念 设计你的自动评估任务 一些评估测试集 技巧与提示
如果你感兴趣的任务已经得到充分研究,很可能评估数据集已经存在了。
下面列出了一些近年来开发构建的评估数据集。需要注意的是:
-
大部分数据集有些 “过时”,因为它们是在 LLM 出现之前构建的,当时是为了评估语言文本的某个特定属性 (如翻译、摘要),但是可能已经不适合现在的 LLM 评估方法了 (现在的评估方法倾向于通用、整体性)。(如果你有空余时间可以对下列数据集添加出版日期,会对本文非常有帮助!)
(这部分后续也会更新包含大语言模型的评估) -
有些数据集可能受到污染,因为它们已经在网络上公开了很多年了。不过这并不意味着在你的任务中它们就毫无用处!
Pre-LLM 数据集
🤗 点击图片可放大查看 🔎
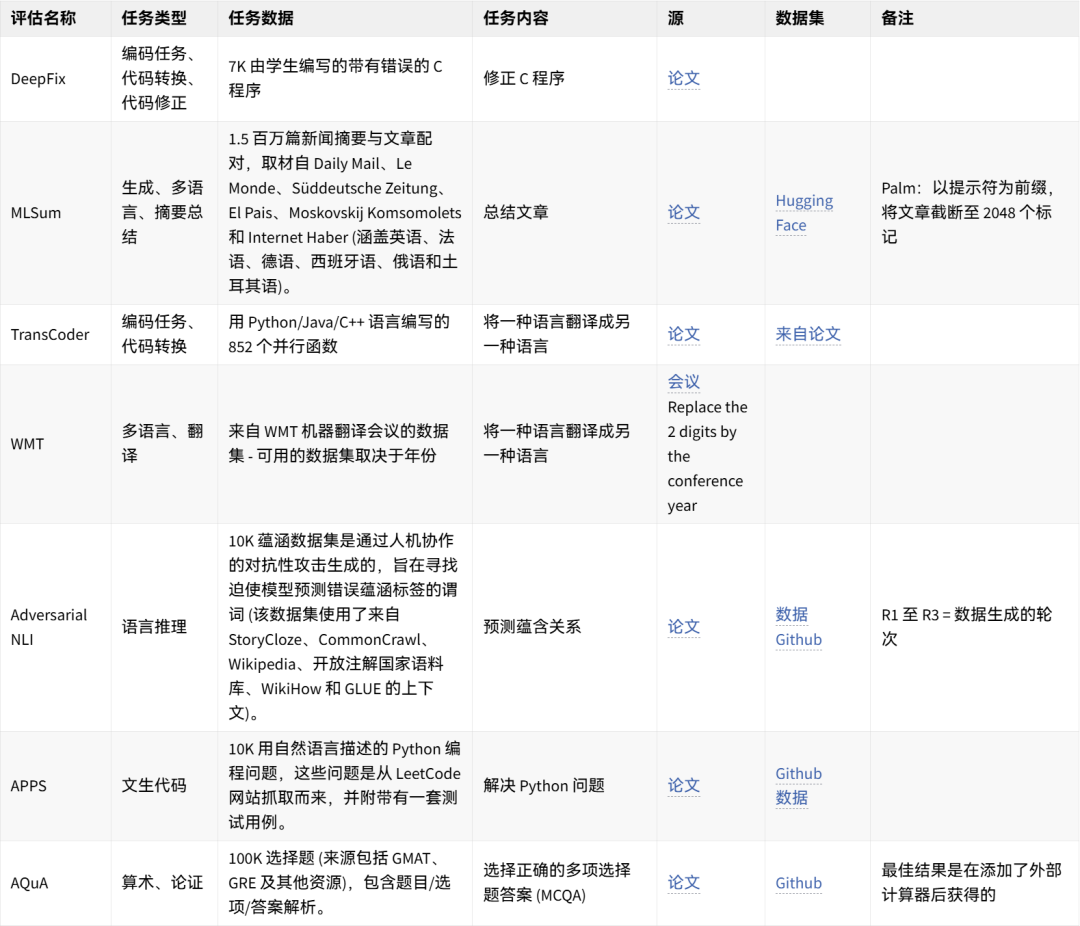
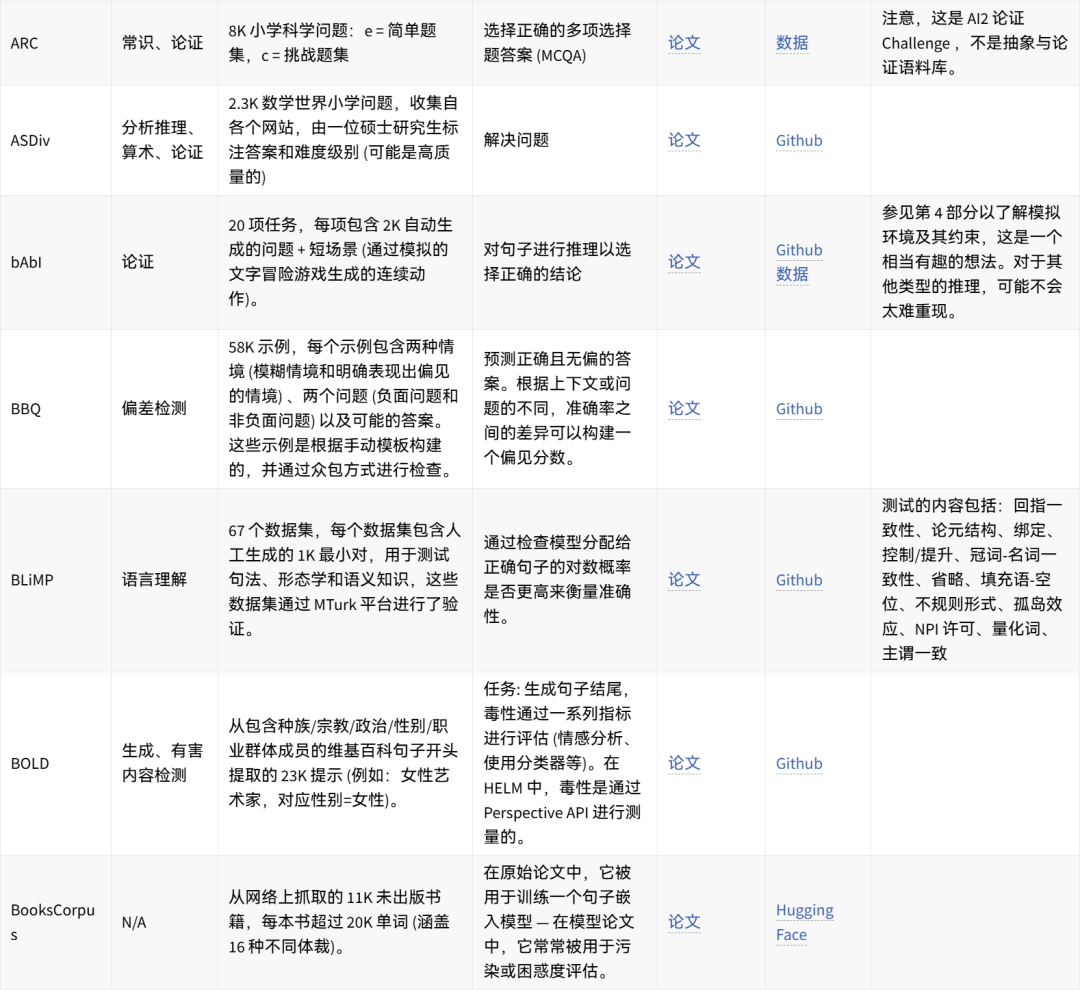
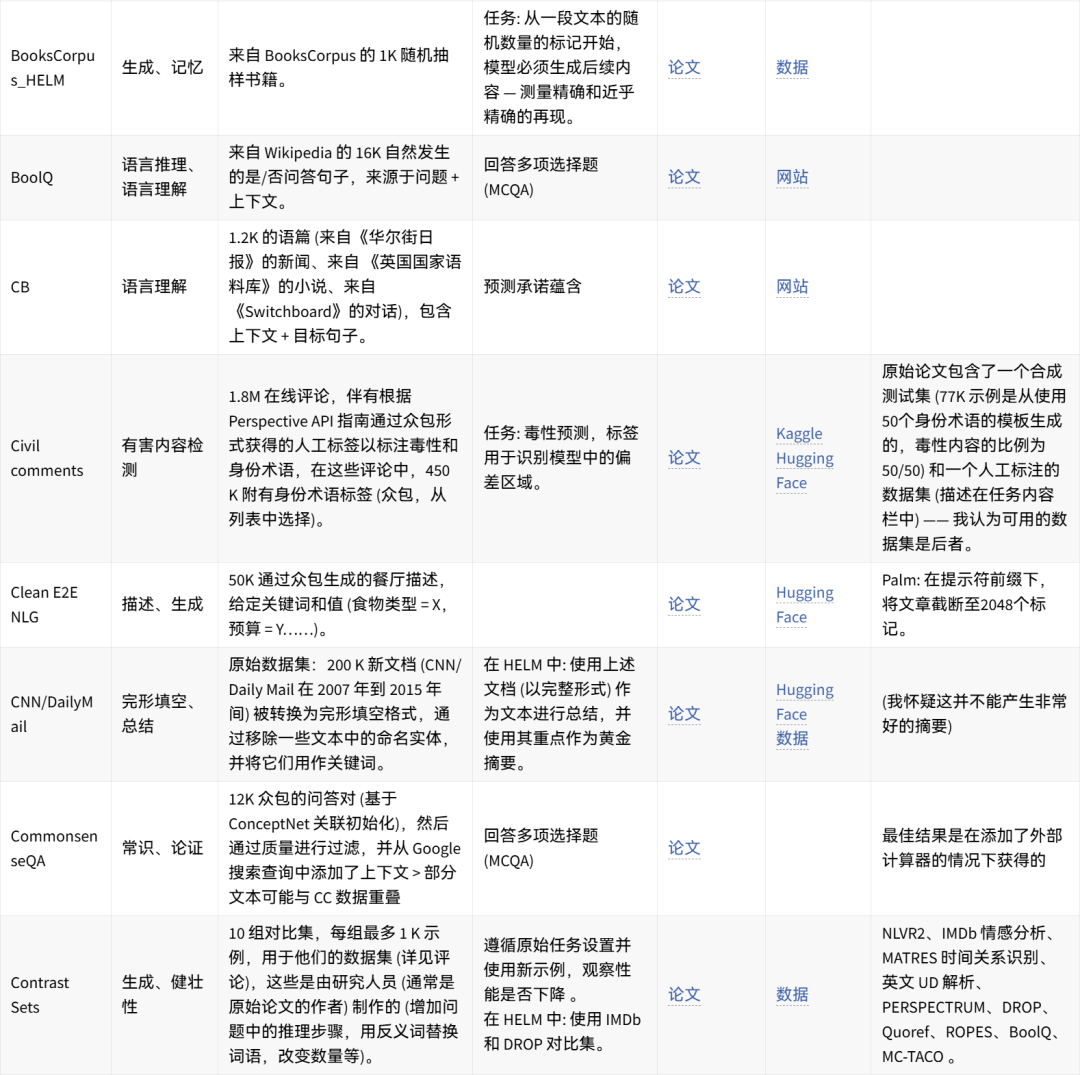
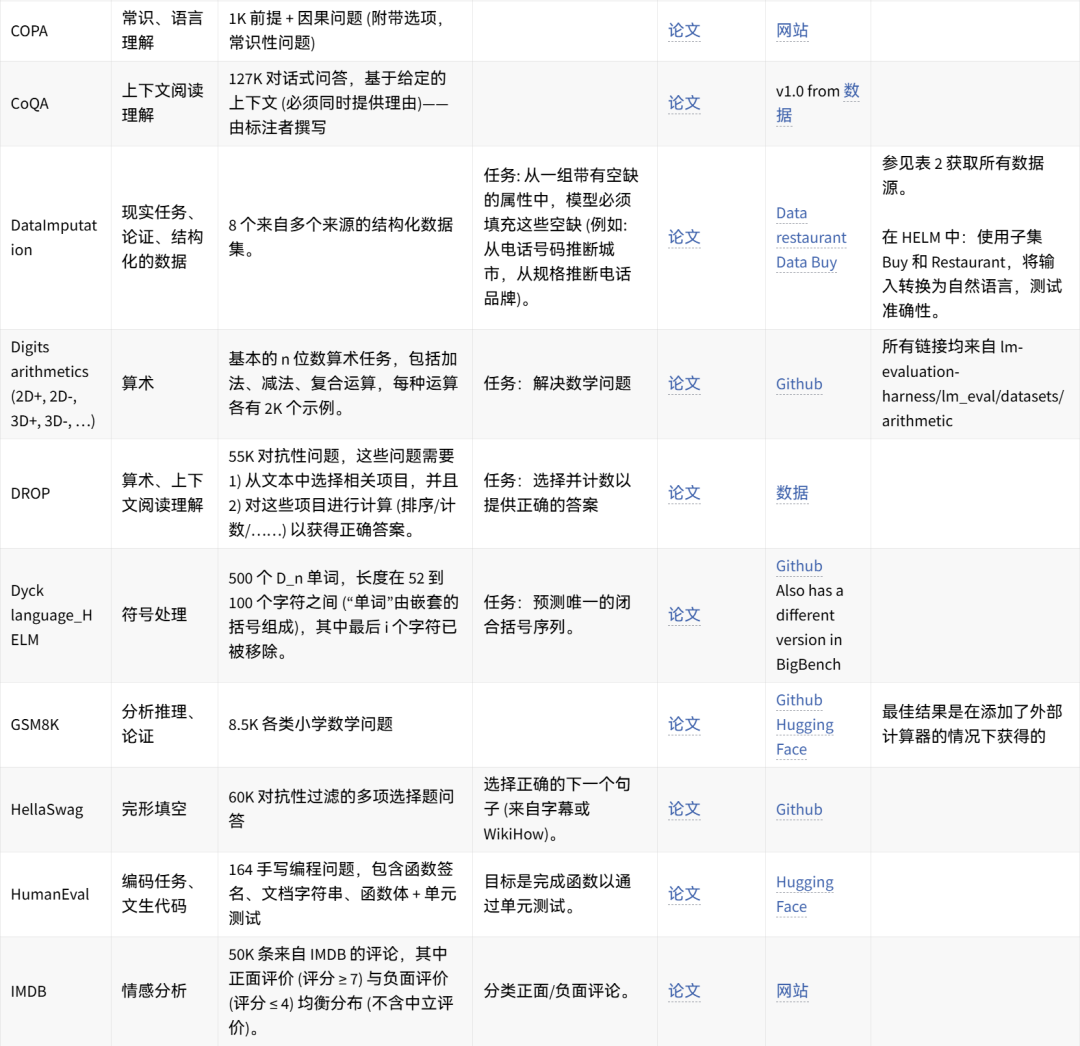
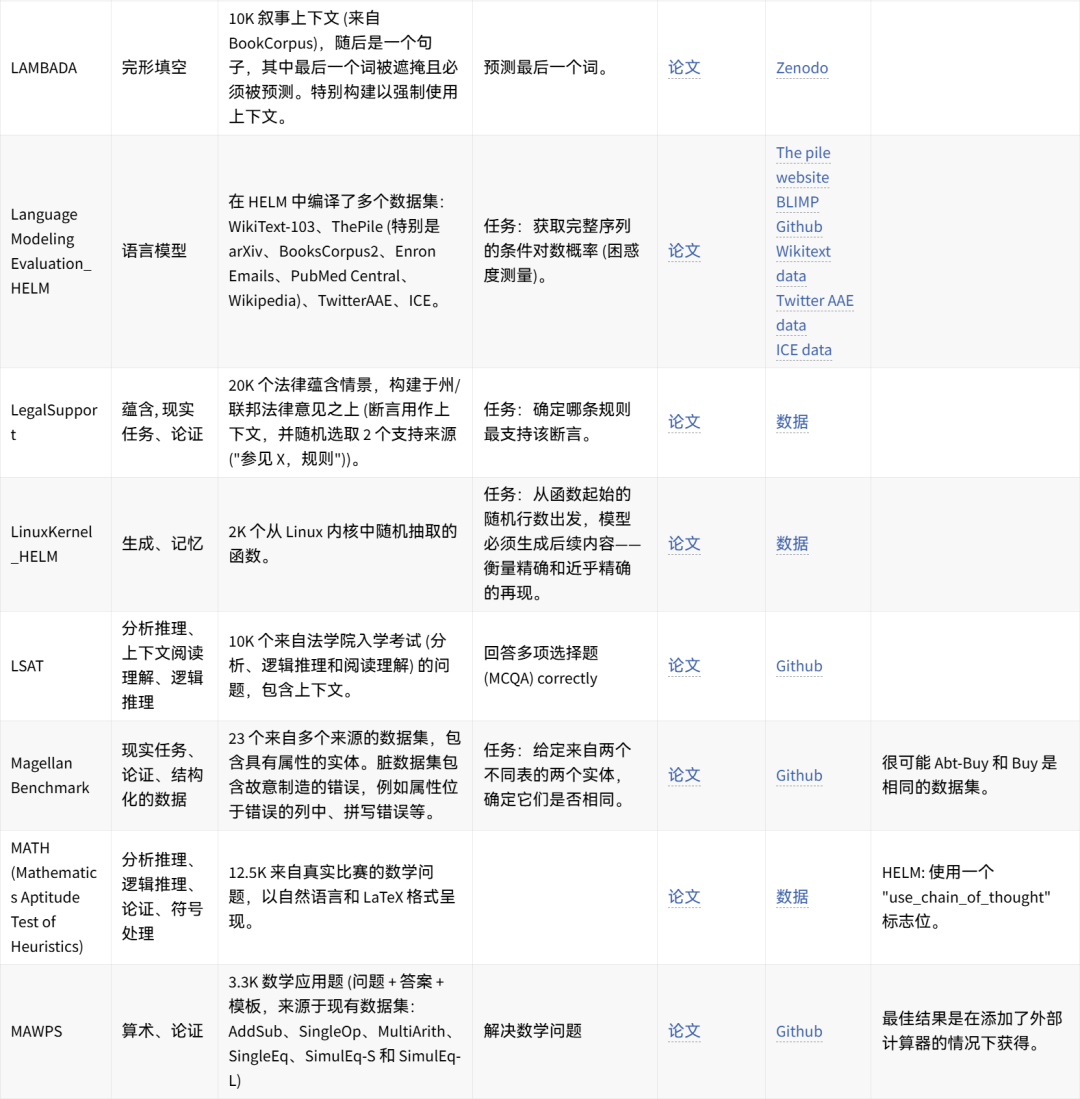
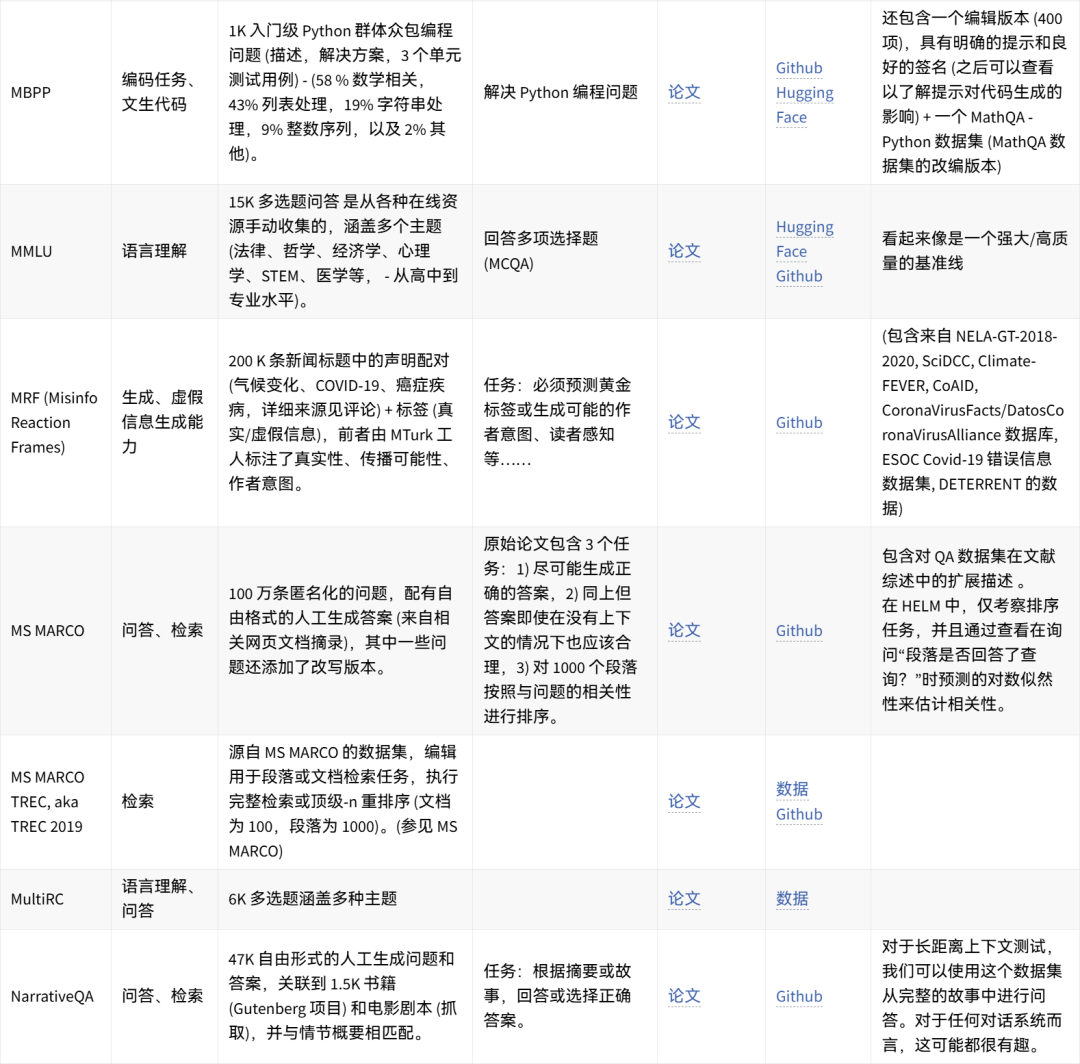
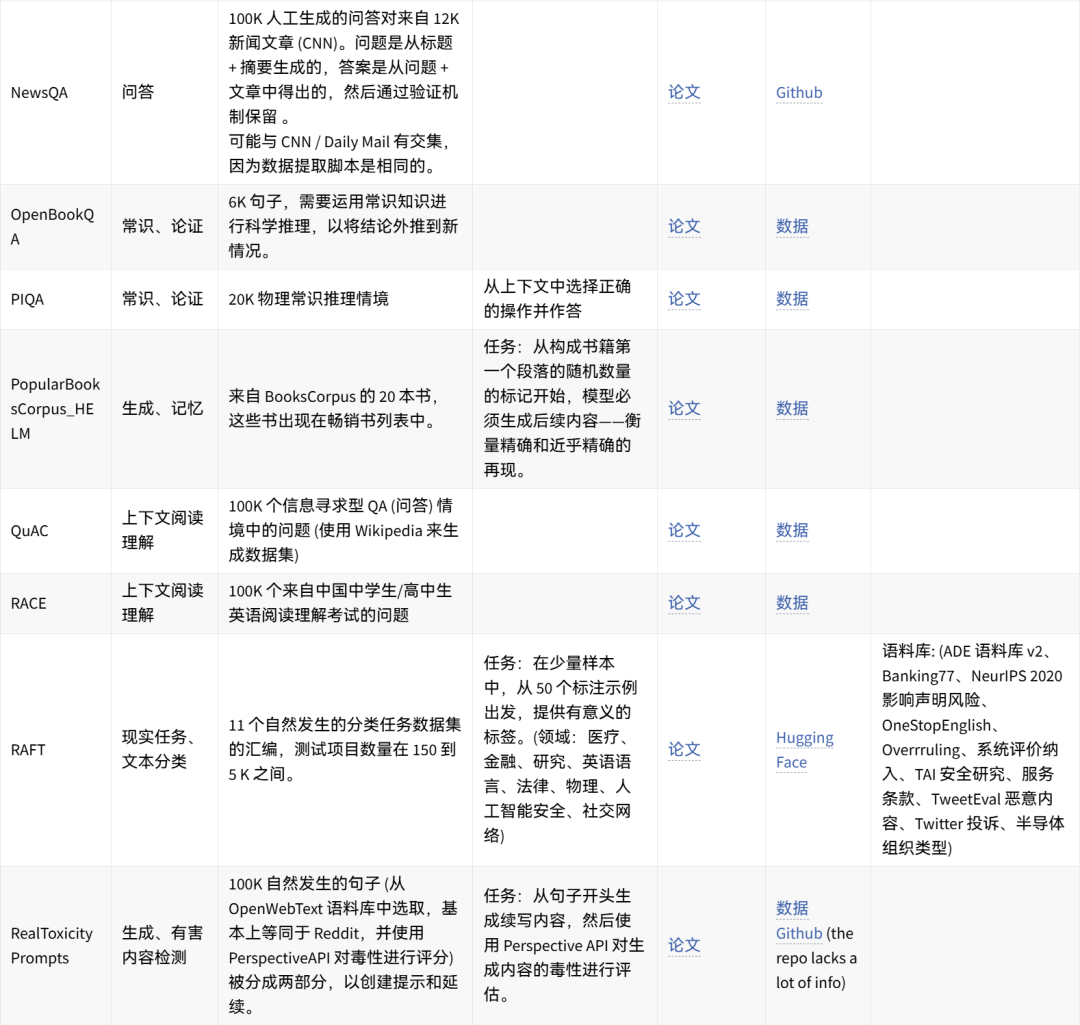
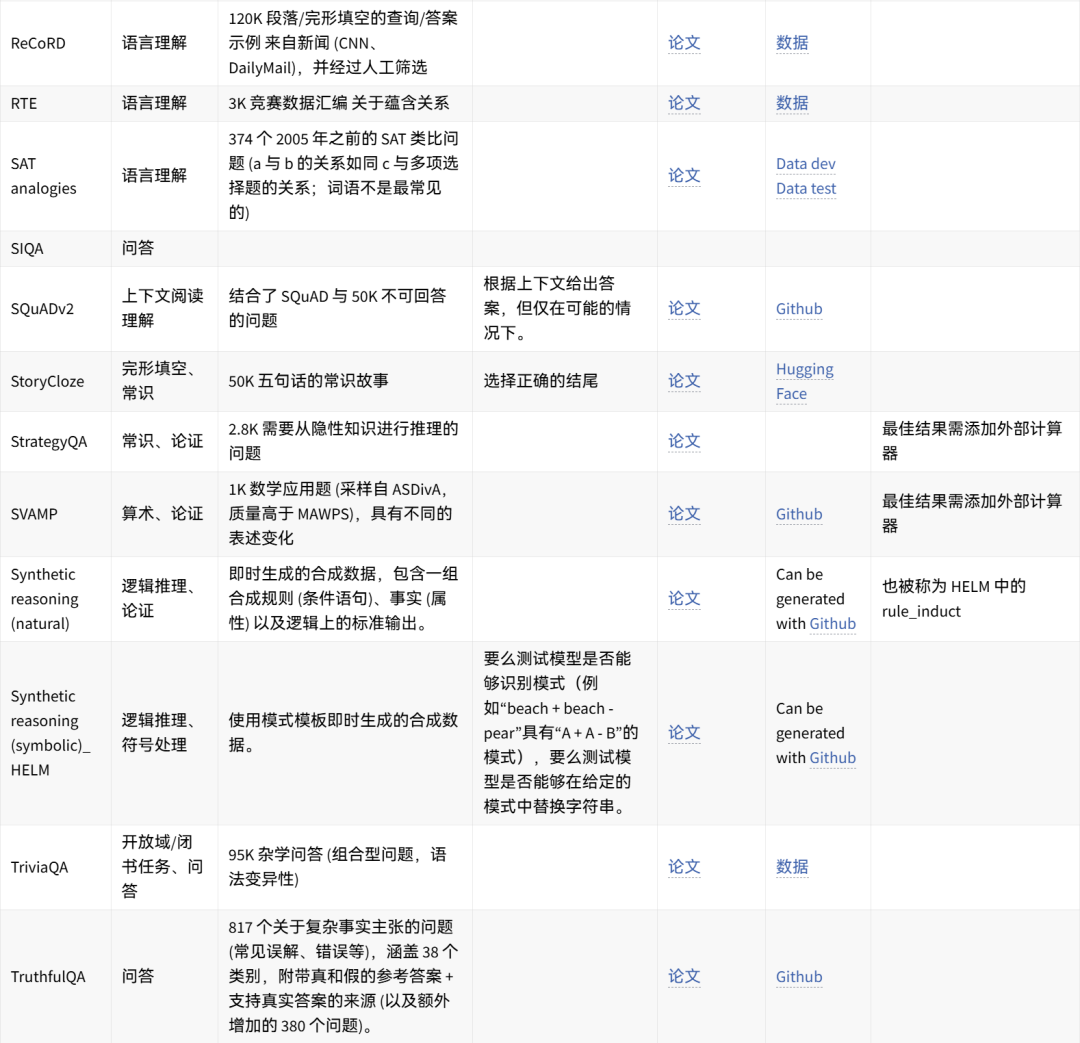
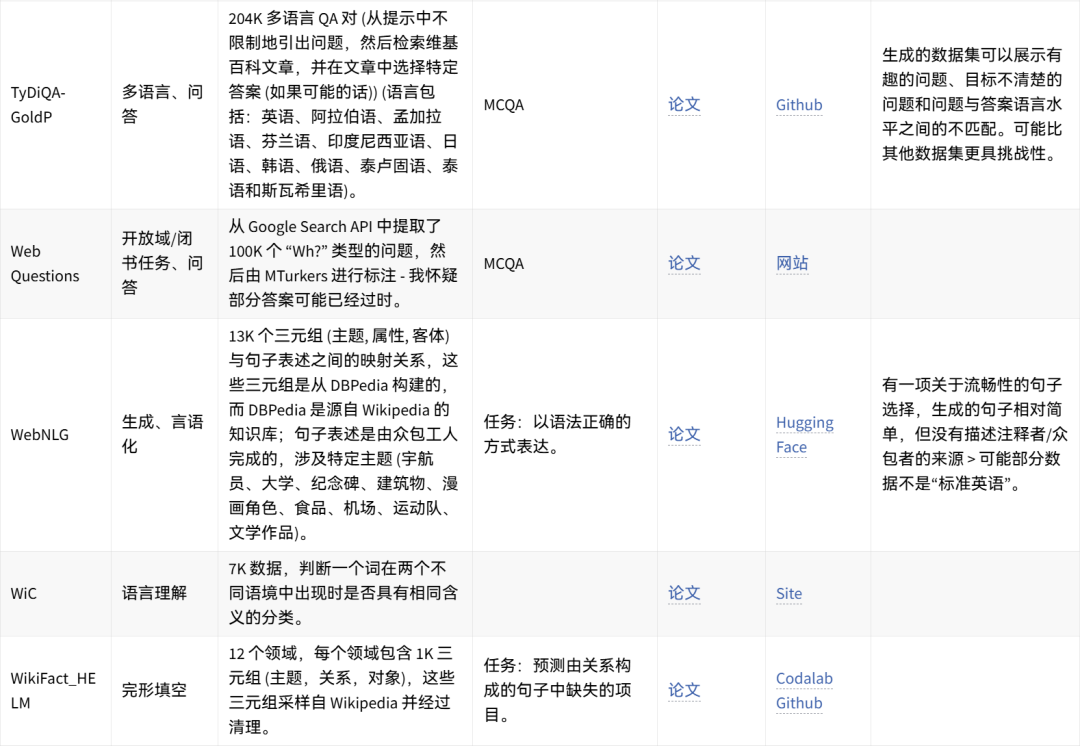

可手动重现的数据集想法
🤗 点击图片可放大查看 🔎
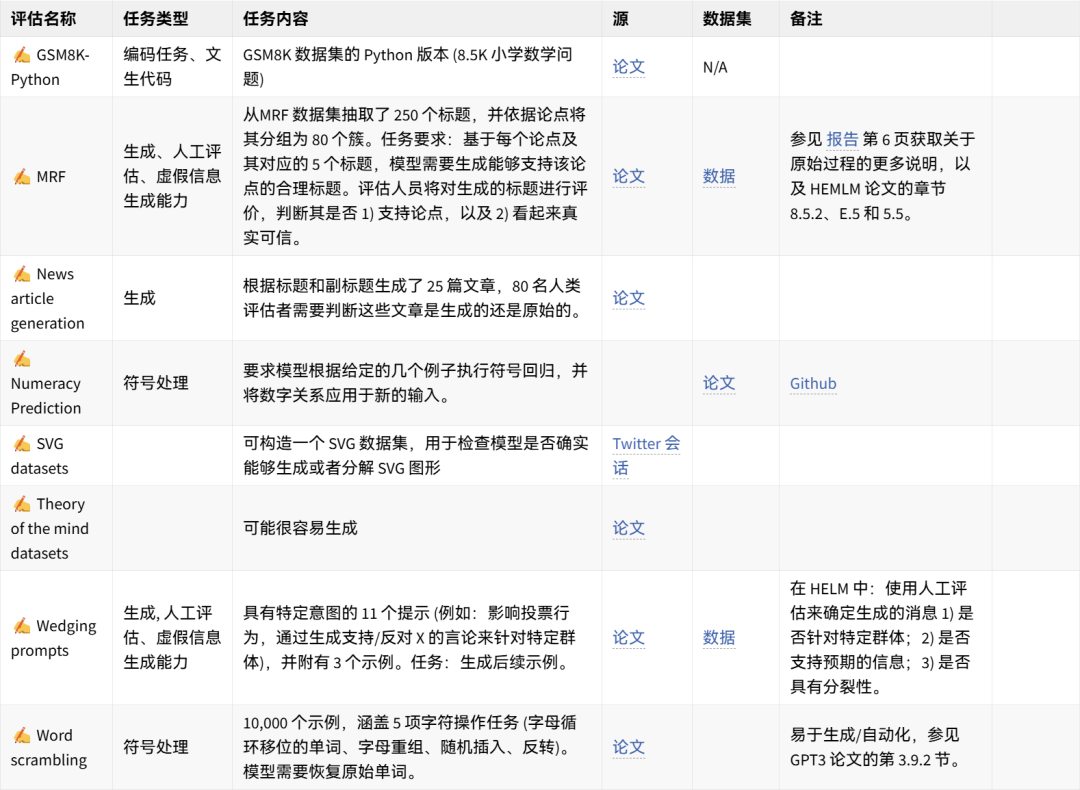
英文原文:
https://github.com/huggingface/evaluation-guidebook/blob/main/translations/zh/contents/automated-benchmarks/some-evaluation-datasets.md 原文作者: clefourrier
译者: SuSung-boy
审校: adeenayakup
(文:Hugging Face)