

亮点:
⚡ 高效轻量的架构设计:基于混合专家(MoE)架构,Aria-UI 仅需激活 3.9B 参数,就能高效处理各种分辨率和比例的 GUI 输入,实现卓越性能。
🏆 领先的基准测试成绩:在权威测试平台表现优异:
OSWorld:排名第三
超越 Claude 3.5 Sonnet 的设备操控能力。

🤗 Hugging Face 在线 demo(立即试用!):
🔧 GitHub 仓库:
📑 论文链接:
🤗 Hugging Face 链接:
▶️ 视频演示:
-
https://raw.githubusercontent.com/AriaUI/AriaUI.github.io/refs/heads/master/static/videos/Can you make Bing the main search thingy when I look stuff up on the internet.mp4 -
https://github.com/AriaUI/AriaUI.github.io/raw/refs/heads/master/static/videos/Delete the following expenses from pro expense Streaming Services, Unexpected Expenses, Pet Supplies..mp4 -
https://github.com/AriaUI/AriaUI.github.io/raw/refs/heads/master/static/videos/add audio into my presentation file.mp4

研究背景:高性能视觉驱动的GUI智能体
-
决策规划(Planning): 通过持续感知和分析屏幕状态,智能体能够为特定用户目标规划出最优的操作序列。 -
语言-视觉定位(Grounding): 基于规划阶段生成的操作指令,智能体精确识别界面元素位置并执行相应的交互动作,实现从决策到行动的转化。
-
界面布局的异构性:不同设备和平台间的 GUI 呈现出显著的视觉差异,增加了元素定位的复杂度
-
交互指令的多样化:用户指令在表达形式和内容上存在巨大变化,要求模型具备强大的语义理解能力
-
任务场景的动态性:GUI 环境的实时变化和任务执行过程的复杂性,对模型的适应能力提出了更高要求

-
强大的指令适配能力:为应对多种任务指令,Aria-UI 构建了一条灵活且可扩展的数据生成管道,能够高效生成多样化、高质量的指令样本。这使模型具备强大的泛化能力,无论何种任务环境都能灵活适应。
-
深度上下文感知:动态操作上下文对任务执行至关重要。Aria-UI 集成了纯文本和图文结合的历史操作记录,使其具备强大的上下文感知推理能力,显著提升模型在复杂任务场景下的执行效率和准确度。
在全面测试中,Aria-UI 在多项离线和在线基准任务中刷新了 SOTA 记录,不仅超越了传统纯视觉模型,也远远领先依赖 AXTree 等额外信息的方案。这一成果展示了纯视觉方法在 GUI 自动化领域的强大潜力,为未来更智能、高效的跨平台任务自动化探索提供了新思路。Aria-UI 的发布标志着纯视觉 GUI Grounding 从学术研究迈向实际应用。
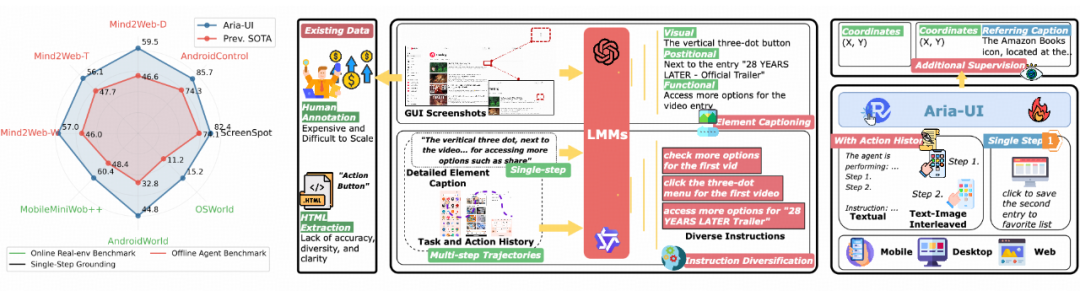


为此,Aria-UI 采用了一种创新的数据驱动方法,通过全新的数据合成 pipeline,覆盖了网页、桌面和移动端三大平台,为多样化指令适配能力提供了坚实的基础。
2.1 全方位覆盖多平台数据
Aria-UI 采用双阶段数据生成策略,构建了一套高效的数据处理 Pipeline:
-
第一阶段:界面元素的精细化描述
我们基于先进的多模态语言模型(如 GPT-4V 或 Qwen2-VL-72B)构建了元素描述生成系统。该系统整合了多维度输入信息:
-
界面元素截图
-
HTML 文本内容
-
空间位置信息
-
精准截取:聚焦目标元素的核心区域
-
可视化增强:通过红框标注突出目标元素
-
第二阶段:指令的智能化构建
通过这套精心设计的数据处理流水线,我们成功构建了一个跨平台的大规模指令数据集,涵盖网页、桌面应用和移动平台等多种场景,为模型训练提供了坚实的数据基础。
2.1.1 网页平台数据(Web)
-
网页智能筛选:首先,在网页筛选阶段,我们采用 fastText 模型对海量网页进行智能评估,建立了严格的质量控制机制。通过多维度的内容分析,系统自动过滤低质量和不当内容,重点保留那些具有丰富交互特性的高质量页面,确保数据源的可靠性。
-
元素提取:在交互元素提取环节,我们开发了基于 HTML 结构的智能识别算法,精准定位并提取具有交互功能的界面组件。算法重点关注按钮、图标等核心交互元素,并优先从复杂场景中采集具有代表性的样本,以提升数据集的实用价值。
-
多分辨率渲染:为适应不同设备环境,我们利用 Playwright 工具实现了多分辨率渲染策略,重点覆盖 1920×1080 和 2440×1600 两种主流分辨率。这种自适应渲染方案确保了数据集在各类显示设备上的通用性,显著提升了模型的跨设备适应能力。
通过这套系统化的处理流程,我们从 173K 个网页中成功提取了 200 万个高质量交互元素,并最终生成了 600 万条精准指令样本。这个规模可观、质量优异的数据集为网页任务自动化奠定了坚实的数据基础。
2.1.2 桌面平台数据(Desktop)
-
智能探索:Agent 通过访问系统的 A11y 树(可访问性树)选择下一步交互元素,并采用深度优先搜索遍历未访问区域;
通过这套自动化系统,我们成功构建了包含 50K 个高质量桌面元素样本的数据集,并据此生成了 150K 条丰富多样的交互指令,有效填补了桌面环境数据的空白,为 GUI 自动化研究提供了坚实的数据基础。
移动平台作为 GUI 自动化研究的核心领域,已积累了丰富的公开数据资源。其中,AMEX 数据集以其 104K 界面截图和 1.6M 交互元素的显著规模优势脱颖而出。然而,这个数据集存在一个关键局限:绝大部分界面元素仅配有简单的文本描述,缺少与实际应用紧密关联的自然语言指令。

通过这一系列创新,Aria-UI 不仅解决了现有数据集的局限性,还为模型在多样化指令适配能力上提供了更强的支持。无论是网页、桌面还是移动端,Aria-UI 都展现出卓越的性能,为未来的跨平台任务自动化提供了强有力的工具支持。

高效精准:Aria-UI 的模型架构解析
-
强大的多模态理解能力:Aria模型采用先进的多模态架构设计,能够精准理解和处理复杂的视觉-语言交互场景。其原生的多模态处理机制不仅可以准确识别 GUI 元素的视觉特征,还能深入理解元素间的空间关系和语义联系,为各类 GUI 任务提供了强大的环境适应能力,确保在不同场景下都能维持稳定的性能表现。
-
突出的性能效率:得益于创新的混合专家架构设计,Aria 模型将活跃参数规模精简至 3.9B,显著低于传统 7B 规模的密集模型。这种高效的参数配置不仅大幅提升了推理速度,还实现了更经济的计算资源利用。在实际应用中,系统能够快速响应用户指令,提供流畅的交互体验,完美平衡了性能和效率的需求。
4.1 高分辨率适配:提升界面处理精度
这些技术创新使 Aria-UI 在处理现代高分辨率界面时展现出卓越的适应性和精确性,为复杂 GUI 场景的自动化提供了可靠保障。
4.2 双阶段训练策略:构建全面交互能力
为确保模型的泛化性能,我们在训练过程中融入 20% 的基础单步数据,有效防止过度拟合特定场景。这种混合训练策略使模型在保持基础精度的同时,获得了出色的动态任务处理能力。
4.3 推理阶段:动态上下文赋能
在推理过程中,Aria-UI 会生成归一化至 [0, 1000] 范围的像素坐标,用于定位目标元素。借助上下文感知训练,模型可以将历史操作记录(如先前的元素交互或定位结果)作为输入,这种设计大幅提升了模型在复杂动态环境中的表现,使其能够高效执行跨平台任务。
通过这些优化,Aria-UI 不仅精准适配高分辨率和复杂界面,还能灵活应对动态环境中的多种任务,展现了卓越的性能和适应能力,为 GUI Grounding 的未来发展指明了方向。

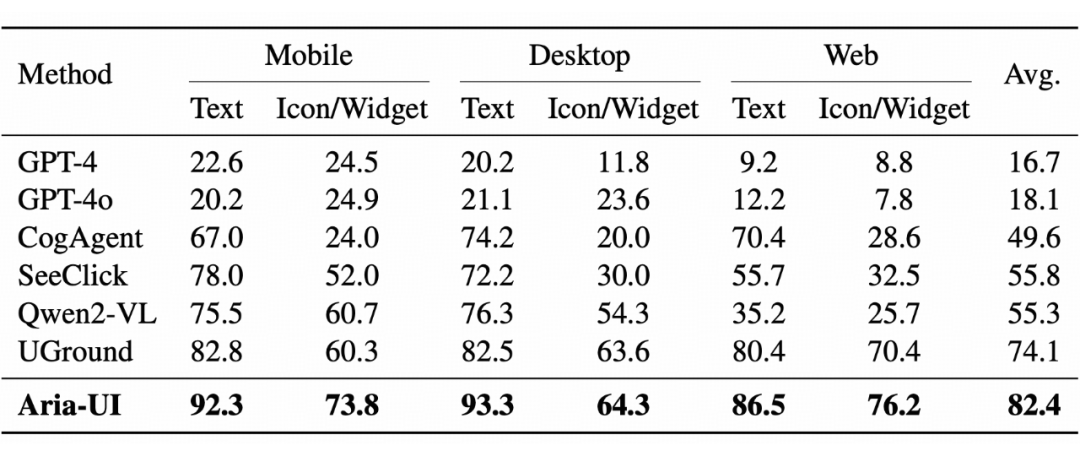
在 ScreenSpot 基准测试中,我们率先评估了 Aria-UI 的单步 GUI Grounding 能力。该测试涵盖六个子集,涉及多种类型元素和三大平台,为每个测试样本提供一张独特的 GUI 图像及人工标注的指令,要求模型精准定位特定元素。测试中,移动端与网页端的分辨率为 2K,桌面端样本分辨率为 540p。
结果表明,Aria-UI 在所有子集上的平均准确率达到 82.4%,展现了卓越的基础 Grounding 性能。特别是在涉及文本元素的任务中,Aria-UI 展现出强大的优势,充分证明了其在不同平台和元素类型中的强大适应能力与稳健性。
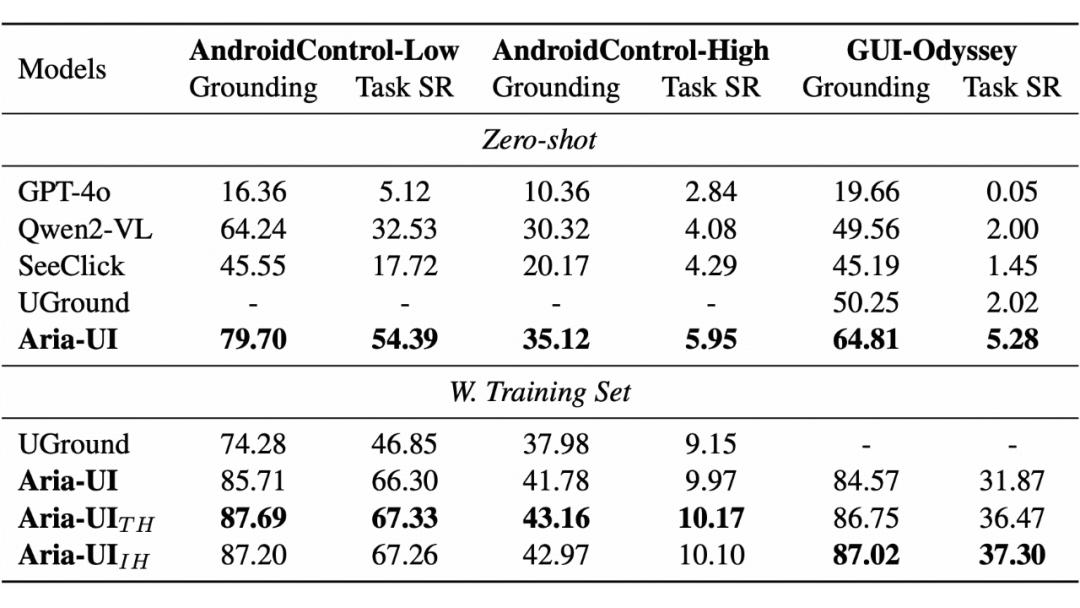
5.1 移动端:离线 Agent 表现强劲
在离线动态测试场景中,模型需为智能体的任务轨迹生成定位坐标。我们选择了 AndroidControl-Low、GUI-Odyssey 和 AndroidControl-High 三个数据集进行测试:
-
AndroidControl-Low 和 GUI-Odyssey提供逐步指令;
-
AndroidControl-High仅提供用户目标任务,需额外使用 GPT-4o 规划器生成逐步指令。
-
Aria-UI_TH:输入基于文本格式的动作历史,用于辅助理解任务上下文,兼顾效率与性能。
-
Aria-UI_IH:结合文本动作历史与图像信息的混合输入,提供更丰富的上下文,适用于需要精确视觉感知的场景。
结果显示,这两种变体在 AndroidControl 和 GUI-Odyssey 数据集上均超越现有基准模型,进一步验证了历史信息在任务完成中的重要作用。尤其是 Aria-UI_TH 在效率与性能之间实现了完美平衡。
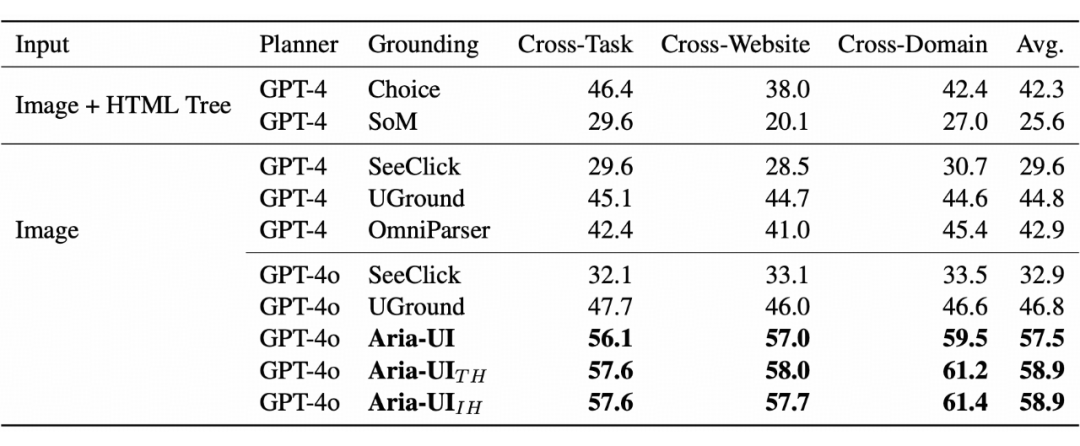
5.2 网页端:离线 Agent 的多模态适应能力
我们在 Multimodal-Mind2Web 基准上验证了 Aria-UI 的网页智能代理性能。此基准包含跨任务、跨网站及跨领域三种子集,考察模型在零样本场景中的表现。测试中,Aria-UI 平均准确率达到 57.5%,而两种变体分别达到 58.9%,显著超越现有模型。特别是在跨网站和跨领域任务上,Aria-UI_IH 展现了其强大的多模态上下文理解能力,为复杂网页环境中的精准定位提供了有力支持。
5.3 在线评估:真实场景中的强大能力
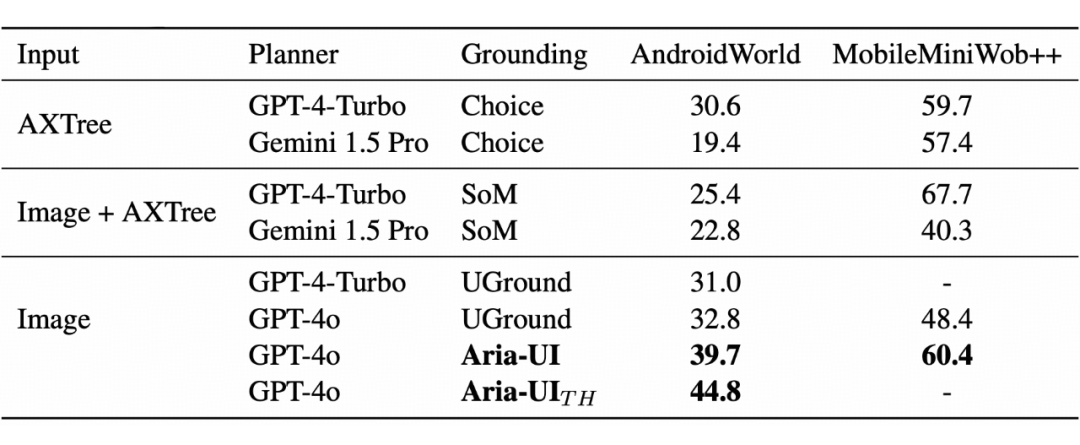
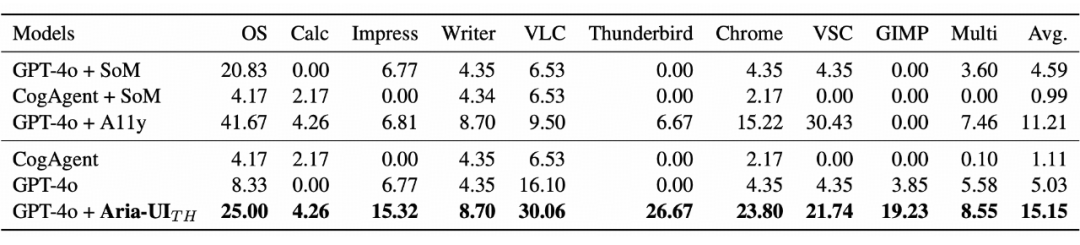
5.3.1 移动端与电脑端在线任务评估
移动与 Web 环境表现突破
-
在 AndroidWorld 移动模拟环境中,Aria-UI_TH 创造了 44.8% 的任务成功率新纪录,显著超越现有最先进方法。系统通过虚拟设备状态监测,在复杂指令处理和动态场景适应方面展现出独特优势。
-
在 MobileMiniWob++ 网页任务评估中,尽管传统 SoM 方法在简单布局任务上具有一定优势,但 Aria-UI 凭借其强大的纯视觉处理能力,在整体表现上仍然遥遥领先。这一成果充分证明了模型在跨场景应用中的卓越泛化能力。
5.3.2 复杂电脑系统环境下的优势效果
-
VLC 播放器:30.06%
-
Chrome 浏览器:23.80%
-
Impress 演示:15.32%
5.4 结论:多场景下的性能突破
(文:PaperWeekly)