


论文地址:
代码地址:
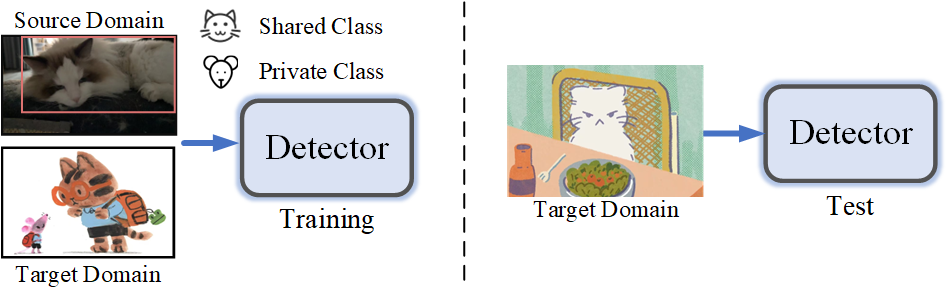

现有UniDAOD模型的不足
-
首先,区分源域和目标域中的类别,并将其划分为公共类别和私有类别; -
接着,去除私有类别,仅保留公共类别; -
然后,针对这些公共类别的特征进行对齐,从而实现从开放集场景到闭集场景的转变。
2. 概率阈值是否在复杂的检测任务中对不同特征都有效?
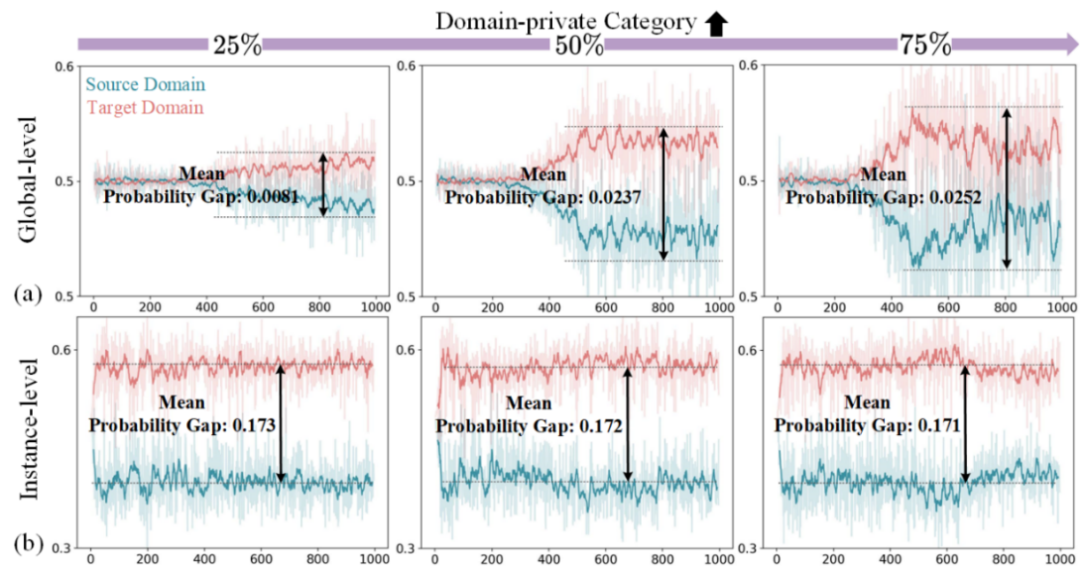
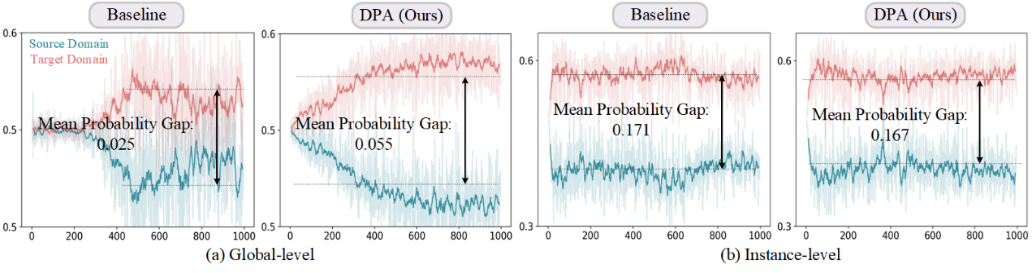
▲ 图2. 域鉴别器中的概率的可视化。横轴为训练迭代次数(×100),纵轴为域判别器的概率。

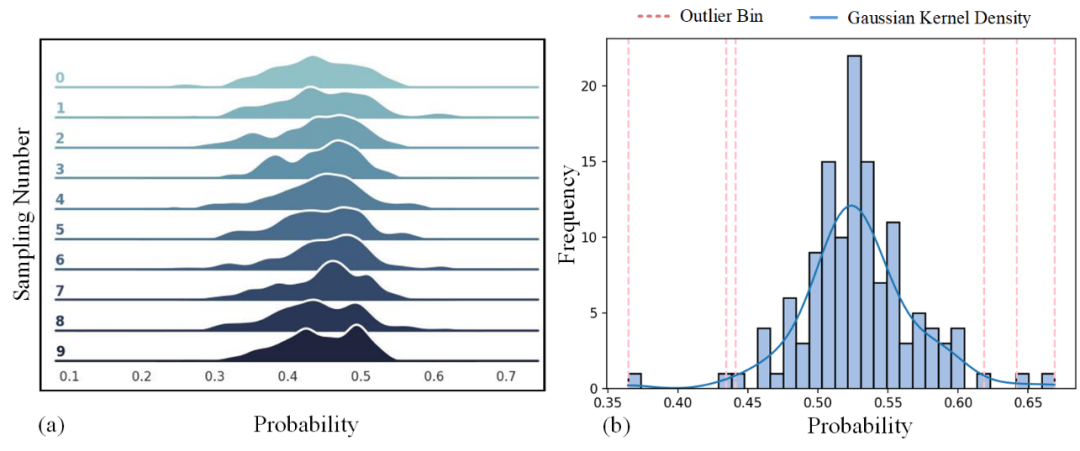
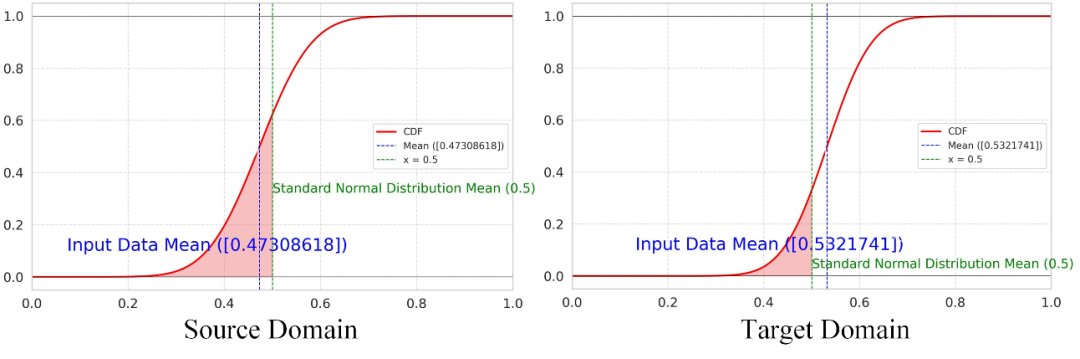
▲ 图5. 全局级别特征的分布累计函数CDF

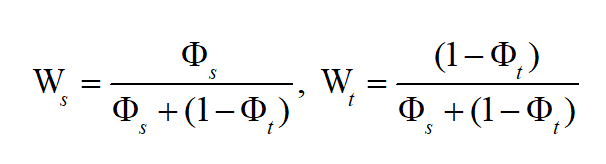

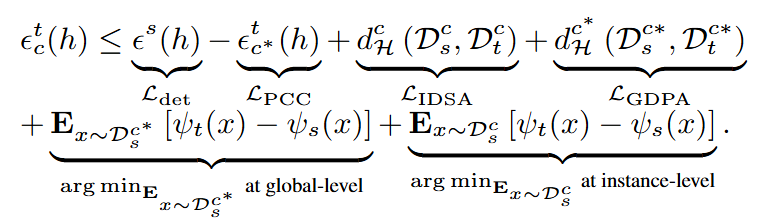
DPA模型框架
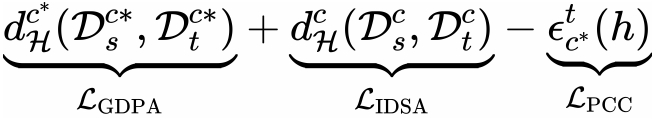
具体来说,GDPA 利用全局级别采样挖掘域私有类别样本并通过累积分布函数计算对齐权重来解决全局级别私有类别对齐。IDSA 利用实例级别采样挖掘域共享类别样本并通过高斯分布计算对齐权重来进行域共享类别域对齐以解决特征异质性问题。PCC 在特征和概率空间之间聚合域私有类别质心以缓解负迁移。
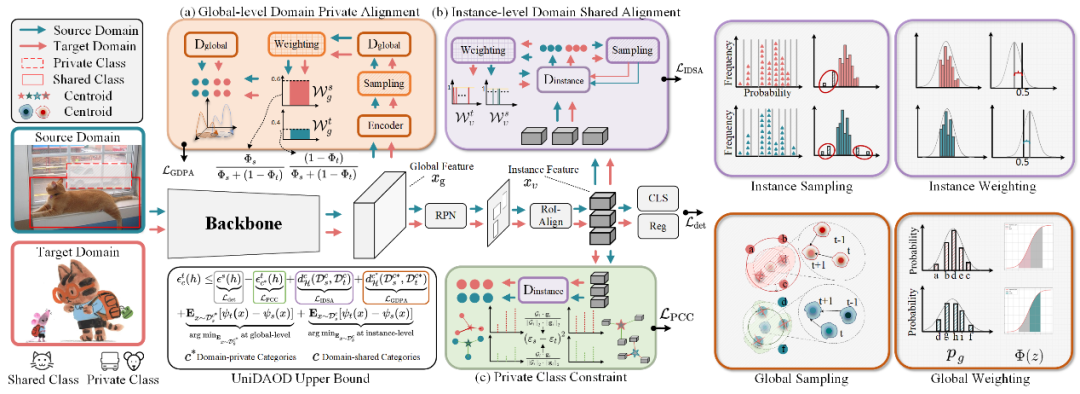
▲ 图6. 本文所提出的DPA 框架示意图

实验结果
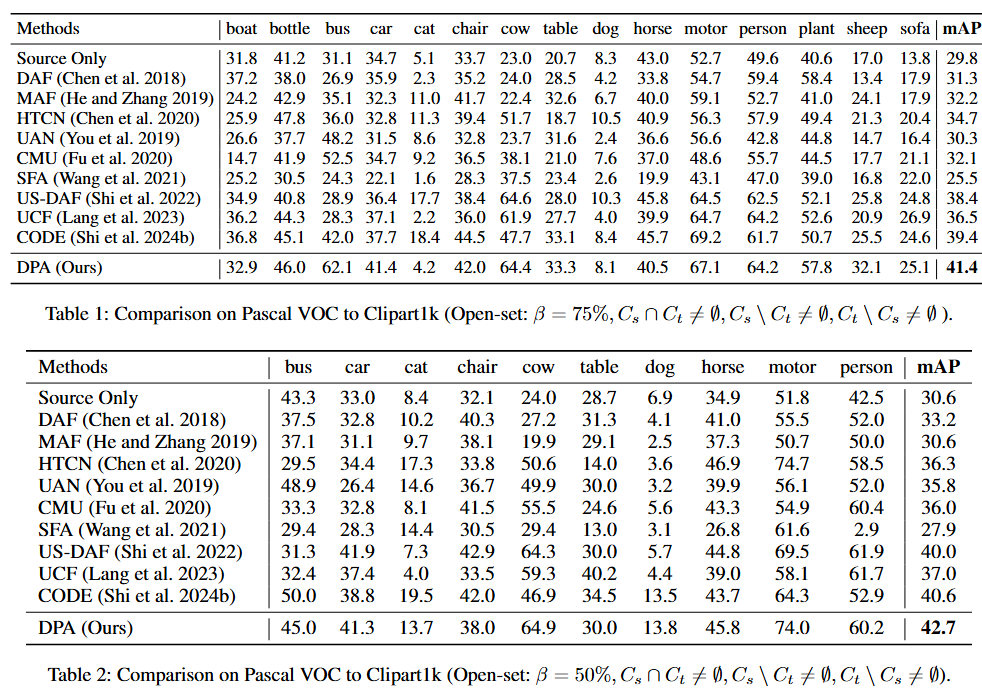
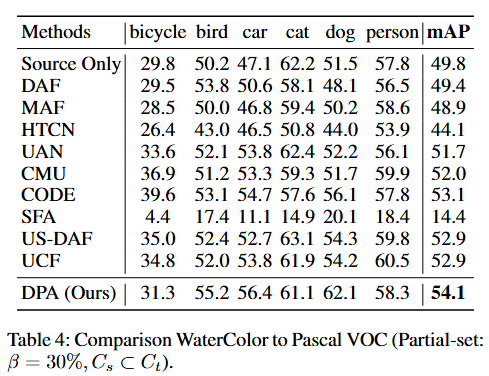
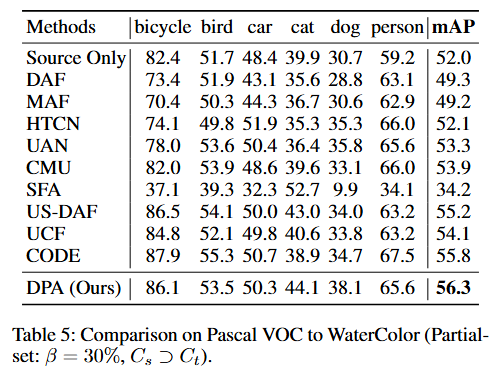
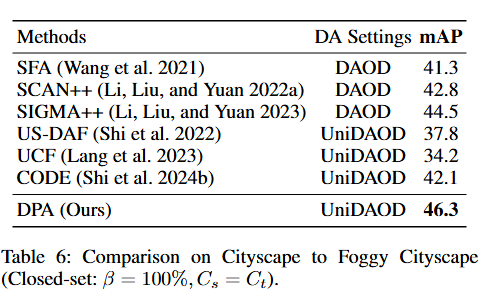
开放集场景中的性能结果

消融实验


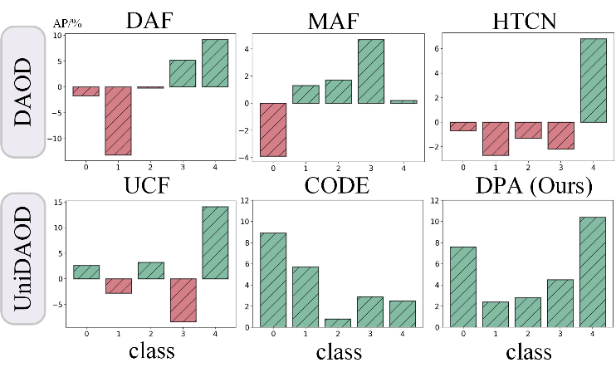
▲ 图7. 相较于Source-Only模型的类别性能提升(类别包括飞机、自行车、鸟、船和瓶子)。正迁移以绿色表示,负迁移以红色表示。
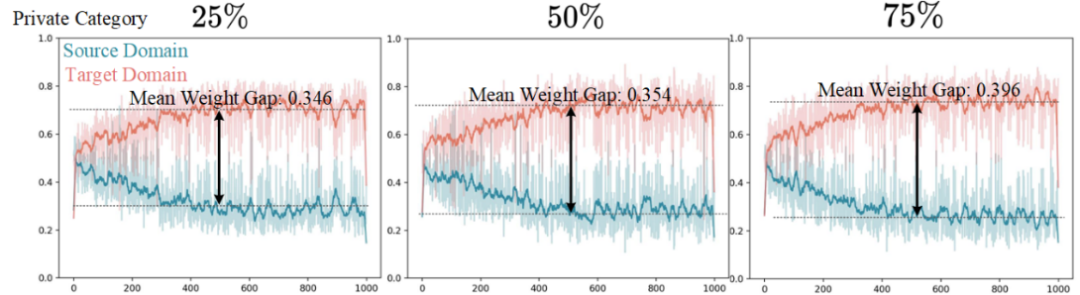
此外,我们对全局域私有对齐进行了权重定量分析(见图 9)。随着域私有类别比例的增加,平均权重差也随之增大,这表明对抗训练通过权重调整,自适应地惩罚了与域私有类别相关的特征。

大量实验表明,在开放集、部分集和封闭集场景中,DPA 框架显著优于现有的通用域自适应目标检测方法。
(文:PaperWeekly)