
Ethical AI 歌手语音平台启动

Auribus公司推出Voice by Auribus创新产品,结合真实歌手与AI技术,为音乐制作人提供订阅模式的语音制作工具,并确保艺术家获得报酬,保护其权益。
Auribus公司推出Voice by Auribus创新产品,结合真实歌手与AI技术,为音乐制作人提供订阅模式的语音制作工具,并确保艺术家获得报酬,保护其权益。

Omnisent宣布完成300万美元Pre-Seed轮融资,由Atlantic Labs领投。该公司专注于通过硬件和软件创新开发声音技术的新应用,目标是制造业、能源、国防等市场。

Starkey MEA 在‘更好听力月’期间推出Edge AI,其核心的G2神经处理器使设备能够自动适应各种环境。Edge AI重新定义了听力支持,并具备增强用户体验的功能。

NotebookLM 团队成员创立 Huxe 公司推出新 AI 应用,连接用户电子邮件、日历等信息流并生成个性化音频简报。Huxe 计划与现有应用集成,初期仅向选定用户开放。

StoryRabbit推出的‘奥森·威尔斯呈现’利用AI技术重现传奇人物声音,让用户在日常地点体验沉浸式叙事。此应用程序由Treefort Media与奥森·威尔斯遗产方合作开发,已独家通过其应用程序推出。
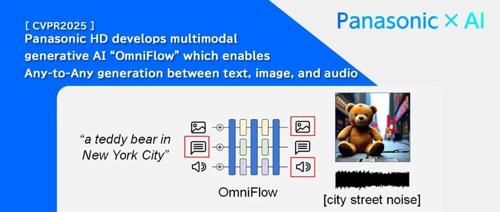
松下研发的OmniFlow多模态生成式AI技术能够自由转换文本、图像及音频等多种数据格式,即使少量包含所有三种模态的数据也能学习高精度模型,显著降低创建训练数据的成本。

Gemini 2.5 在 I/O 大会上展示了原生音频对话和生成能力,包括自然对话、风格控制、工具集成、多语言性等特性,提升了实时交互体验,并支持多种语音输出形式。


