新AI压缩器来了,Techivation发布AI-Compressor

今年音频技术向全面AI化发展,Techivation的新发AI-Compressor简化压缩器设置,提供精确增益衰减控制、感知滤波器和可缩放用户界面等功能。
今年音频技术向全面AI化发展,Techivation的新发AI-Compressor简化压缩器设置,提供精确增益衰减控制、感知滤波器和可缩放用户界面等功能。

Nokia与坦佩雷大学合作开发了一种新的基于深度神经网络(DNN)的环境声编码方法,能够自动适应不同的麦克风阵列排列,并在保持高质量音频处理的同时显著降低开发成本。

初创公司Nari Labs推出文本转语音(TTS)模型Dia,拥有16亿参数,性能超越竞争对手。支持多种控制和定制功能,包括说话人标记、非语言音频提示等。目前仅限英语,正在逐步开源并开发消费者版本。

Wondershare Filmora发布AI Audio to Video功能,助力创作者轻松制作引人入胜的短视频,迎合短视频流行趋势和年轻用户偏好。

以色列情报单位8200将人工智能技术整合到军事战略中,成功击毙哈马斯加沙城旅指挥官易卜拉欣·比亚里。AI技术使决策更快更精准,在战争期间发挥了重要作用。

近日xMEMS Labs宣布,BleeqUp Ranger AI运动眼镜采用了其创新的音频技术,这是首款商用的AI眼镜,支持紧凑型高性能音频解决方案。

Adobe 发布Firefly AI平台新版本,新增翻译音频、视频功能及背景音乐生成能力,提升创意工作效率。支持多种语言翻译、声音与视频同步调整,并提供图像和视频生成模型,增强内容创作灵活性。
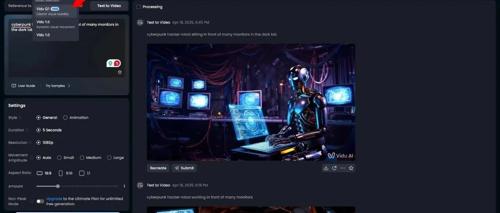
生数科技Vidu Q1发布,支持仅两张图片和一段文本提示生成高清5秒1080p视频,并提供高保真音效功能,支持精细化时间控制和多段音效叠加。该模型在提示词保真度、帧连贯性及渲染效率上表现突出,成本低至每秒0.3元。