
一款名为 Dia 的新开源文本到语音模型

初创公司Nari Labs推出文本转语音(TTS)模型Dia,拥有16亿参数,性能超越竞争对手。支持多种控制和定制功能,包括说话人标记、非语言音频提示等。目前仅限英语,正在逐步开源并开发消费者版本。
初创公司Nari Labs推出文本转语音(TTS)模型Dia,拥有16亿参数,性能超越竞争对手。支持多种控制和定制功能,包括说话人标记、非语言音频提示等。目前仅限英语,正在逐步开源并开发消费者版本。

由Nari Labs开发的Dia-1.6B因其逼真的对话生成能力而受到关注,仅开源两天便在GitHub收获了6.5K+Star。它支持多角色对话、拟人化表达、零样本声纹克隆等功能,并且运行效率高,音质媲美ElevenLabs和Sesame。

Nari Lab的Dia-1.6B模型通过开源和微调技术实现了高质量的人声对话生成,支持多种音色、语气和效果,目前在单卡配置下每秒可生成约40个token音频。两位韩国学生仅用3个月便自主开发完成此项目,使用谷歌TPU资源训练模型,并计划将其发展为一款完整应用。

机器之心报导,Dia-1.6B 是一个在 GitHub 等平台上走红的开源语音模型,不仅能生成说话的声音、对话,还能合成真实感强的各种声音。其参数量为1.6B,目前已被下载超过5600次,热度排名Hugging Face第二,已收获大量好评和星标。
Two undergraduate students created an AI model that generates podcast-style audio similar to Google’s NotebookLM. Nari Labs’ Dia model, with 16 billion parameters, can generate dialogues from scripts and add prosody, non-verbal cues like coughs and laughs. While the tool runs well and has a simple voice cloning feature, it lacks protection against misuse of generated content.
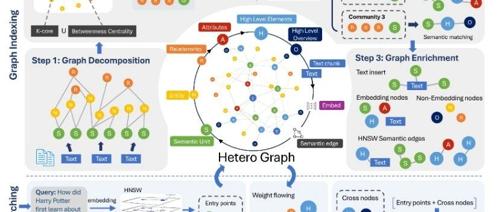
近期分享了五款AI技术产品:Dia文本转语音模型、SkyReels V2无限长度电影生成器、Open Codex命令行AI助手、NodeRAG异构图检索增强生成系统以及MCP Containers容器化MCP服务器。