一份生成式人工智能学习路线的手册:Generative AI Handbook
一份生成式人工智能学习路线手册介绍,涵盖基础知识、实践应用及最新研究进展,并提供多种学习资源,适合有一定编程基础和数学水平的学习者。
一份生成式人工智能学习路线手册介绍,涵盖基础知识、实践应用及最新研究进展,并提供多种学习资源,适合有一定编程基础和数学水平的学习者。
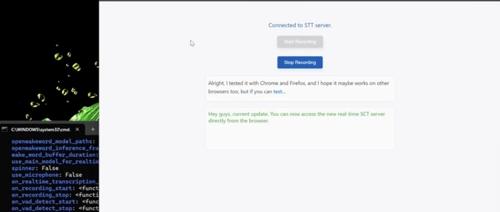
RealtimeSTT是一款开源工具,专注于实时将语音转录为文字。它提供智能体验如语音活动检测和唤醒词激活功能,简化录音控制,并支持多种用法场景。

一个只有150万参数的神经网络模型HOVER,让机器人的运动像极了人类。它能在英伟达Isaac模拟套件中以50分钟完成相当于一年高强度训练的速度进行精准控制。

SpeechSSM 新模型可一口气生成16分钟语音故事,无需文字辅助。相比传统AI「业余选手」,它采用分割处理内容方法,使模型在任何时刻只需处理固定长度的内容,并保持声音特征稳定,实现流畅连贯的即兴演讲效果。

专注于AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地。斯坦福大学与加州伯克利大学发布的《ChatGPT行为随时间变化》论文详细分析了GPT-3.5和GPT-4的性能波动及其原因,包括指令遵循度的变化、内容过滤能力的下降等问题。